1.本发明涉及一种船舶轨迹预测方法,尤其涉及一种长期船舶轨迹预测方法。
背景技术:
2.船舶轨迹预测是水上交通态势感知的重要组成部分,是实现智能航运的关键性技术。从预测时长上可将船舶轨迹预测分为短期预测和长期预测两个领域。短期预测常用于船舶避碰。与路上交通不同,由于船舶的巨大惯性,短期预测相对容易实现,传统的恒速预测模型(constant velocity model,cvm)已经较为成熟,且已应用于商业产品。其他常见的预测方法中,中国专利文献号cn110070565b公开的一种基于图像叠加的船舶轨迹预测方法,采用卡尔曼滤波技术通过建模单船过去一段时间的运动来估计未来短期运动轨迹;中国专利文献号cn104484726b公开的船舶轨迹实时预测方法,运用隐马尔科夫模型同样可以利用单船在过去多个采样时刻的状态来预测下一采样时刻的状态。近年来,随着深度学习技术的崛起,不同深度的神经网络广泛用于短期船舶轨迹预测,其核心原理是将单船过去多个时刻的状态值按照时间序列输入神经网络模型进行训练,最终输出下一时刻船舶状态。
3.相比短期预测,长期预测的挑战性更高,它不仅需要考虑船舶过去的运动轨迹,还需要考虑航行水域的总体交通模式及通航条件等因素,因此很难通过直接改进现有机器学习模型实现。在已有的长期预测方法中,比较通用的做法是首先使用聚类技术对历史ais船舶轨迹进行处理从而识别总体交通模式,再将待预测船舶过去的行为特征与总体模式进行匹配,估算其最大概率的未来航线从而实现长期预测,如中国专利文献号cn112164247a公布的一种基于船舶轨迹聚类的船舶航线预测方法。然而现有方法尚存在缺陷,一是只能实现单一模式轨迹预测,未考虑多航行模式的预测;二是只能预测船舶轨迹的形态及位置信息,无法预测沿途各时刻的航向及航速等信息。
技术实现要素:
4.本发明所要解决的技术问题是提供一种长期船舶轨迹预测方法,改进已有船舶轨迹预测方法精度不够高且仅能实现单轨迹预测的缺陷,可以通过灵活调节阈值的方式实现多航行模式的轨迹预测,兼顾不同时刻航速及航向等重要信息预测,适用于内河海事监管、智能航运信息推送以及到港时间估计等应用领域。
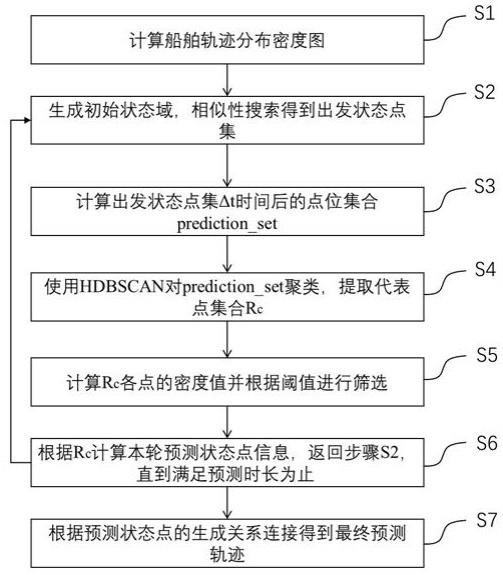
5.本发明为解决上述技术问题而采用的技术方案是提供一种长期船舶轨迹预测方法,包括如下步骤:s1、将预测水域空间按照规则网格进行划分,在网格化基础上计算船舶轨迹分布密度图;s2、由待预测船舶初始状态点生成初始状态域,在初始状态域内利用相似性搜索得到出发状态点集;s3、计算出发状态点集δt时间后的点位集合prediction_set;s4、使用密度聚类算法对prediction_set聚类,提取聚类结果主要集群并计算代表点,得到代表点集合rc;s5、计算rc各点在船舶轨迹分布密度图对应的密度值,如果低于设定的密度阈值,则将该点从rc中去除;s6、根据rc计算本轮预测状态点信息,再将其作为输入返回步骤
s2,重复s2~s6,直到满足预测时长为止;s7、从最后一轮计算得到的预测状态点逐轮向上,根据预测状态点的生成关系连接得到最终预测轨迹。
6.进一步地,所述步骤s1包括:s11、确定待预测水域空间范围,将其按照经纬网进行网格划分,网格边长取5
×
10-5
度;s12、使用线密度估计方法计算轨迹密度分布:将历史ais轨迹线集合叠加至网格,计算落入每个网格中的轨迹线数量n及其相交长度li,得到网格值;s13、对网格值进行全局归一化处理,使其值域控制在[0, 1]区间内,形成最终船舶轨迹分布密度图。
[0007]
进一步地,所述步骤s2包括:s21、确定待预测船舶的初始状态点,所述初始状态点包含海上移动业务识别码、瞬时位置、对地航速、对地航向和时间戳;s22、由待预测船舶初始状态点生成出发线,所述出发线的中点为初始状态点的位置坐标,所述出发线的角度与初始状态点对地航向保持垂直;s23、计算初始状态域,所述初始状态域由出发线生成的缓冲区构成,缓冲区计算方法为单线定距缓冲;s24、对初始状态域内历史ais轨迹点进行相似性搜索得到出发状态点集;s24、如果出发状态点集中存在多个具有相同mmsi值的元素,则保留其中与出发线垂直距离最近的一个元素。
[0008]
进一步地,所述步骤s2中初始状态域由出发线生成的缓冲区构成;所述出发线由待预测船舶初始状态点生成,出发线中点为初始状态点的位置坐标,出发线角度与初始状态点对地航向保持垂直;所述缓冲区由出发线单线定距缓冲生成。
[0009]
进一步地,所述步骤s24中相似性搜索采用下式计算:|sogsꢀ‑ꢀ
sogi| 《 γ|cogsꢀ‑ꢀ
cogi| 《 λ|ts‑ꢀ
ti| 《 τ其中,sogs表示初始状态点航速,sogi为搜索点航速,γ为航速阈值,cogs表示初始状态点航向,cogi为搜索点航向,λ为航向阈值,ts表示初始状态点时间戳,ti为搜索点时间戳,τ为时间阈值。
[0010]
进一步地,所述出发线长度为100米,缓冲值取值为50米,γ取值为1节,λ取值为30度,τ取值为10天。
[0011]
进一步地,所述步骤s3中δt时间后的位置由出发状态点所在的实际ais轨迹以线性内插方式计算得到,如果在某一时刻无法定位到前、后采样,则判定该时刻已超过实际ais轨迹时间范围,直接舍弃该点。
[0012]
进一步地,所述步骤s4中主要集群是指聚类结果中除了离群点外,元素数量占总数量超出预设比值的集群;所述代表点是指主要集群中距离中心点坐标最近的元素,所述中心点由主要集群中所有元素平均坐标计算得到。
[0013]
进一步地,所述步骤s5中密度阈值的选择区间设定如下: 对于单条常见航行规律的轨迹预测,密度阈值区间为[0.2,0.5];对于存在支汊航道航行的轨迹预测,密度阈值区间为[0.1,0.2];对于更多行为模式的轨迹预测,密度阈值区间为[0.05, 0.1]。
[0014]
进一步地,所述步骤s6中预测状态点信息包括位置坐标、航向及航速信息;其中预测状态点位置坐标为rc中各点的坐标,预测状态点航向为rc中各点与上一轮预测状态点坐
标形成的向量角度,极坐标轴正方向为正北,值域范围在[0
°
, 360
°
];预测状态点航速由rc中各点与上一轮预测状态点之间的距离d/δt计算得到,其中d为两点间的haversine距离。
[0015]
本发明对比现有技术有如下的有益效果:本发明提供的长期船舶轨迹预测方法,利用局部行为模式的相似性探知下一时刻潜在位置,利用总体行为模式的规律性约束不合理状态,通过循环递推的方式,实现精准的长期轨迹预测,同时兼顾沿途各采样时刻的航速及航向预测,此外,本发明还能够通过调节阈值的方式实现多航行模式的轨迹预测。
附图说明
[0016]
图1为本发明长期船舶轨迹预测方法流程图;图2为本发明计算得到的船舶轨迹分布密度图;图3为本发明初始状态域内相似性搜索方法示意图;图4为本发明的点位集合prediction_set示意图;图5为本发明预测状态点连接关系示意图;图6为本发明预测轨迹与实际轨迹对比效果图;图7为本发明在支汊航道水域预测效果图。
具体实施方式
[0017]
下面结合附图和实施例对本发明作进一步的描述。
[0018]
图1为本发明长期船舶轨迹预测方法流程图。
[0019]
请参见图1,本发明提供的长期船舶轨迹预测方法,在局部上利用船舶行为的相似性探知待预测船舶下一时刻潜在位置集合,使用密度层次聚类技术过滤异常值并提取预测点;在总体上利用历史轨迹分布的规律性通过阈值筛选约束预测点,并以循环递推的方式实现精准长期轨迹预测。本发明改进了已有船舶轨迹预测方法精度不够高且仅能实现单轨迹预测的缺陷,通过灵活调节阈值的方式实现多航行模式的轨迹预测,兼顾不同时刻航速及航向等重要信息预测,适用于内河海事监管、智能航运信息推送以及到港时间估计等应用领域,具体实施步骤如下。
[0020]
s1、将预测水域空间按照规则网格进行划分,在网格化基础上计算船舶轨迹分布密度图。
[0021]
长期船舶轨迹预测需要总体航行模式作为参考,尤其是在航道转弯大、分汊多的复杂内河水域。船舶轨迹分布密度图能够反映某一时空范围内船舶总体行为模式,通过如下方式实现:
①
确定待预测水域空间范围,将其按照经纬网进行网格划分,网格边长取5
×
10-5
度。
②
使用线密度估计方法(line density estimation)计算轨迹密度分布:将历史ais轨迹线集合叠加至网格,计算落入每个网格中的轨迹线数量n及其相交长度li,得到网格值。
③
对网格值进行全局归一化处理,使其值域控制在[0, 1]区间内,形成最终船舶轨迹分布密度图。如图2所示为本方法计算得到的船舶轨迹分布密度图,亮度值越高表示该处航迹密度越高,即有更多船舶从该位置驶过。
[0022]
s2、由待预测船舶初始状态点生成初始状态域,在初始状态域内利用相似性搜索
得到出发状态点集。
[0023]
为了安全航行,船舶驾驶者通常存在“从众”心理,在同一水域相近时间内船舶行为往往具有较强的相似性,本发明正是利用这种相似性开展预测。
①
确定待预测船舶的初始状态点,所述状态点包含海上移动业务识别码(mmsi)、瞬时位置、对地航速、对地航向和时间戳等5组元素。
②
由待预测船舶初始状态点生成出发线。出发线的中点为初始状态点的位置坐标,出发线的角度与初始状态点对地航向保持垂直。如图3所示,黑色三角表示初始状态点,箭头方向为对地航向,黑色粗线为生成的出发线,出发线长度根据水域大小灵活选择,本实施例中为100米。
③
计算初始状态域。初始状态域由出发线生成的缓冲区构成,缓冲区计算方法为单线定距缓冲,本实施例中缓冲值取50米。即以单线为中心轴线,向两侧延伸一定距离的平行条带多边形,如图3中灰色区域即为生成的缓冲区。
④
采用(1)式对初始状态域内历史ais轨迹点进行相似性搜索得到出发状态点集。
[0024] (1)其中,sogs表示初始状态点航速,sogi为搜索点航速,γ为航速阈值,取值为1节。cogs表示初始状态点航向,cogi为搜索点航向,λ为航向阈值,取值为30度。ts表示初始状态点时间戳,ti为搜索点时间戳,τ为时间阈值,取值为10天。
⑤
如果出发状态点集中存在m个(m》1)具有相同mmsi值的元素,则保留其中与出发线垂直距离最近的一个元素。如图3中黑点表示出发状态点集,其中p1和p2两点具有相同的mmsi值413837801,保留距离出发线垂直距离最近的p2。
[0025]
s3、计算出发状态点集δt时间后的点位集合prediction_set。
[0026]
δt根据预测需要设定,本实施例中设为10分钟。由于船舶ais轨迹采样频率各不相同,无法保证每条轨迹δt时间后刚好对应有一个实际采样,因此需要采用线性内插的方法计算坐标。设某出发状态点时间戳为t0,下一时刻时间戳为t
1 = t0 δt。取实际轨迹中t1的前一采样时刻ta,后一采样时刻tb,对应的位置坐标分别为(xa, ya)和(xb, yb),通过(2)式计算t1时刻的坐标(x1, y1):x1= x
a (xbꢀ‑ꢀ
xa)
×
(t
1-ta)/(t
b-ta) (2)y1= y
a (ybꢀ‑ꢀ
ya)
×
(t
1-ta)/(t
b-ta) 特别的,如果t1时刻无法定位到前、后采样,一般是由于t1已超过实际ais轨迹时间范围,则舍弃该点。如图4所示,黑色三角为待预测船舶的初始状态点,圆点构成的集合为δt时间后的prediction_set。可以看出,prediction_set代表了待预测船舶下一时刻潜在船位的集合,实际船位有极大概率处于该集合范围内。
[0027]
s4、使用密度聚类算法 hdbscan对prediction_set聚类,提取聚类结果主要集群并计算代表点,得到代表点集合rc。
[0028]
受到信号干扰以及设备误差影响,ais数据噪声非常常见,尤其是“飞点”现象,尽管可以通过预处理过滤噪声,然而很难实现完全消除。受此影响,prediction_set中会存在离群点影响预测结果精度。如图4所示prediction_set中有一个点处于陆域,明显不符合逻
辑,这就是由噪声数据带来的离群点,因此需要采用密度聚类算法对prediction_set聚类,例如dbscan、optics等密度聚类算法都能实现。但是在实际测试中发现,这些算法在聚类结果、离群点探测方面都不如hdbscan。hdbscan(hierarchical density-based spatial clustering of applications with noise)是一种基于密度的层次聚类方法,由campello,moulavi和sander开发,它通过引入最小生成树构建密度聚类层级,克服了传统dbscan方法对参数敏感的缺点,无需复杂调参即能得到可靠聚类结果并准确识别离群值。hdbscan可通过调用python的sklearn机器学习库实现。得到聚类结果后,提取其中主要集群并计算代表点集合rc。主要集群是指聚类结果中除了离群点外,元素数量占总数量30%以上的集群。代表点是指主要集群中距离中心点坐标最近的元素,中心点由主要集群中所有元素平均坐标计算得到。如图4所示两处菱形点位即为提取的代表点。
[0029]
s5、计算rc各点在船舶轨迹分布密度图对应的密度值,如果低于设定的密度阈值,则将该点从rc中去除。
[0030]
本步骤旨在通过总体航行模式进一步保证预测船位的合理性和可解释性。利用rc各点坐标信息获取在轨迹分布密度图中对应的密度值。设定一个密度阈值用于筛选,阈值大小根据对航行模式预测的精细化需求选取最佳参数。如果设定的阈值较高,预测结果一般就是一条符合最常见航行规律的轨迹。如果设定的阈值较低,则能够得到船舶在不同航行模式下的预测轨迹,例如在不同支汊航道航行的轨迹,在附近港区停泊的轨迹,或者从不同桥孔通过桥梁的轨迹等。本发明推荐的密度阈值在[0.05, 0.5]区间,具体来说,对于单条常见航行规律的轨迹预测,优选区间为[0.2,0.5];对于存在支汊航道航行的轨迹预测,优选区间为[0.1,0.2];对于更加精细的多行为模式轨迹预测,例如在附近港区停泊的轨迹,或者从不同桥孔通过桥梁的轨迹,优选区间为[0.05, 0.1]。
[0031]
s6、根据rc计算本轮预测状态点信息,再将其作为输入返回步骤s2,重复s2~s6,直到满足预测时长为止。
[0032]
预测状态点信息包括位置坐标、航向及航速等信息。其中预测状态点位置坐标即rc中各点的坐标,预测状态点航向为rc中各点与上一轮预测状态点坐标形成的向量角度,极坐标轴正方向为正北,值域范围在[0
°
, 360
°
]。预测状态点航速由rc中各点与上一轮预测状态点之间的距离d/δt计算得到,其中d为两点间的haversine距离。需要注意的是haversine距离是地球上两经纬度坐标点之间的近似平面距离,因此得到的航速单位是米/秒,需将其转换为节(海里/小时)。
[0033]
s7、从最后一轮计算得到的预测状态点逐轮向上,根据预测状态点的生成关系连接得到最终预测轨迹。
[0034]
预测轨迹可能为单条轨迹线,也可能为树形结构轨迹,对应到多种航行模式。如图5所示,x
4,1
, x
4,2
和x
4,3
为第4轮计算得到的预测状态点,其中x
4,1
, x
4,2
是根据上一轮预测状态点x
3,1
的信息计算得到的,因此将它们建立连接关系,同理x
4,3
与x
3,2
建立连接,x
3,1
、x
3,2
与x
2,1
建立连接。根据预测状态点的连接关系形成最终预测轨迹,如图5所示,共预测出船舶未来3条可能的轨迹:(x
1,1
→
x
2,1
→
x
3,1
→
x
4,1
),(x
1,1
→
x
2,1
→
x
3,1
→
x
4,2
),(x
1,1
→
x
2,1
→
x
3,2
→
x
4,3
)。
[0035]
本发明的效果可通过以下实验验证:本发明选取长江太仓至南通段作为实验区,包含浏河、白茆沙和通州沙三处水道,
大量江海联运船舶在该航段航行,具有较强代表性。历史ais轨迹数据时间范围为2021年5月~6月,选取其中60条实际航行时间超过5个小时的船舶作为测试数据。实验中δt设置为10分钟,共执行30轮迭代,总预测时长为5小时,步骤s5中密度阈值设置为0.3。将预测得到的船舶最终状态点与真实船舶轨迹5小时后的状态点进行对比验证,其中位置误差以两者之间haversine距离作为度量,航速及航向误差皆以两者之间绝对差作为度量。考察60组测试数据对比结果的中位值、最大值和最小值,如表1所示。
[0036]
由表1可见,对于长达5小时的长期预测,位置误差的中位值为0.63km,最小误差仅为0.01km,相对于该水域约80km的总航程来看,本方法预测结果达到较高的精度,完全能够满足eta等实际应用。此外,航速误差中位值控制在1节以内,航向误差中位值仅小于6度,同样说明了本方法的有效性。
[0037]
图6直观展示了预测轨迹与真实轨迹的对比效果,测试船舶的mmsi码为413378920,为上水航行船。图中白色三角为真实轨迹在每10分钟时刻的采样点,黑色圆点为预测轨迹每10分钟采样点。可以看出本方法预测的轨迹无论是轨迹形态还是各采样时刻的位置,都与真实轨迹保持一致。
[0038]
图7进一步展示了本方法在支汊航道水域多航行模式轨迹预测的效果。实验区选取长江仪征河段,世业洲将航道分为南北两个支汊,其中南汊为主航道,北汊为副航道。实验中δt设置为10分钟,共执行15轮迭代,总预测时长为2.5小时,步骤s5中密度阈值设置为0.1。测试船舶mmsi码为413824795,从副航道上水航行。不难看出,本方法不仅在副航道得到了与真实轨迹匹配度较高的预测轨迹,还能够预测本船如果选择主航道航行的轨迹。事实上,船舶选择主航道还是副航道,与船舶的目的港、航道条件以及驾驶人员的航行习惯都有关,在缺少这些数据时,对预测来说属于完全随机行为。而本发明能够根据预测需求,通过调节密度阈值的方式实现多航行模式的轨迹预测,这也是本方法区别与其他预测方法的有益效果。
[0039]
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
