一种融合视觉与文本共识特征的医学影像报告生成方法
- 国知局
- 2024-07-12 10:27:57
本发明涉及医疗与人工智能交叉,具体涉及一种融合视觉与文本共识特征的医学影像报告生成方法。
背景技术:
1、自动生成医学影像报告在临床中是至关重要的,它可以减轻有经验的放射科医生的繁重工作,并提醒没有经验的放射科医生误诊或漏诊。
2、然而,现有技术通过神经网络提取医学影像特征生成报告文本,这种纯数据驱动的方法存在视觉和文本偏差以及缺乏专业知识的问题。
技术实现思路
1、本发明的目的在于,提出一种融合视觉与文本共识特征的医学影像报告生成方法,提高医学影像报告生成的准确性和可靠性。
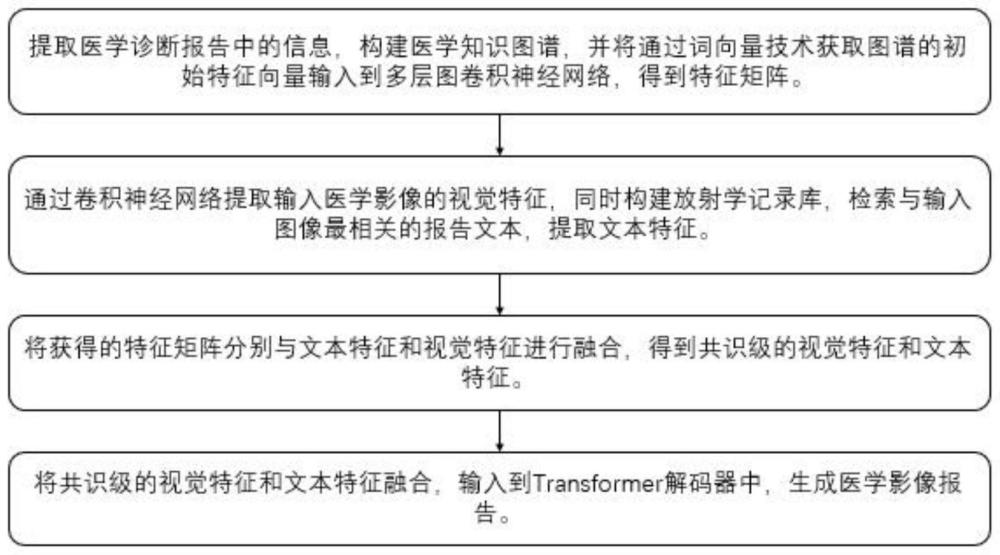
2、为实现上述目的,一种融合视觉与文本共识特征的医学影像报告生成方法,包括以下步骤:
3、提取医学诊断报告中的疾病名称、症状、区域等信息,构建医学先验知识图谱,通过glove技术获取医学先验知识图谱的初始特征向量;将初始特征向量输入至多层图卷积神经网络,得到特征矩阵;
4、通过卷积神经网络提取医学影像的视觉特征,同时构建放射学记录库,根据医学影像和库中医学影像的kl散度,从库中选取最相关的医学诊断报告,并通过自然语言处理,提取文本特征;
5、将所述视觉特征、文本特征经过自注意力机制实例化特征之后,与医学先验知识图谱的特征矩阵融合,生成共识级的视觉特征和共识级的文本特征,基于实例级特征与共识级特征得到视觉融合共识特征和文本融合共识特征;
6、将视觉融合共识特征和文本融合共识特征通过多头自注意力层融合后输入到transformer解码器中,生成医学影像报告。
7、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,所述构建医学先验知识图谱,包括:
8、获取若干医学诊断报告文本;
9、使用radgraph2网络提取医学诊断报告文本中的医学实体和关系;
10、通过提取的医学实体和实体之间的关系构建三元组,并逐步构建医学先验知识图谱。
11、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,得到特征矩阵方式为:
12、将医学先验知识图谱通过glove技术生成初始节点特征,表示为y;
13、使用多层图卷积神经网络gcn处理医学先验知识图谱和与之对应的节点特征。每层图卷积神经网络gcn都会根据图结构更新节点的表示,使得每个节点的表示都能捕捉到高阶邻域的信息。具体来说,每层图卷积神经网络gcn操作可以表示为:
14、
15、其中,h(l)是第l层的节点特征,(对于第一层,h(0)=y),为图的邻接矩阵a加上单位矩阵,是的每行元素求和得到的度数矩阵的对角矩阵,w(l)是第l层的权重矩阵,ρ是非线性的激活函数;
16、通过多层图卷积神经网络处理后获得的特征矩阵为z={z1,…,zq},即zi,z∈rq×d,d表示联合嵌入空间的维数。
17、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,通过卷积神经网络提取医学影像的视觉特征方式为:
18、将医学影像输入到faster-rcnn中,然后通过全连接层,生成m个区域级视觉特征o={o1,…,om},其元素都是f维向量;
19、通过自注意力机制,将上述m个区域级视觉特征o生成为实例级的视觉特征vi。
20、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,构建放射学记录库,根据医学影像和库中医学影像的kl散度,从库中选取最相关的医学诊断报告,具体为:
21、将若干医学影像及医学诊断报告作为放射学记录库,对于放射学记录库中的每条记录,首先提取视觉特征i=cnn(img),然后通过yi=avgpool(i)wc+bc得到i在疾病标签上的分布,其中yi∈r1×n,n为疾病标签个数,wc和bc为疾病分类线性变换的权重参数和偏置项;
22、通过得到医学图像的疾病分布与库中样本的疾病分布yi之间的kl散度,获得的分数用于从库中选择最相关的医学诊断报告。
23、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,提取文本特征方式为:
24、设最相关的医学诊断报告具有l个单词,将每个单词嵌入被顺序馈送到bi-gru中;之后,可以通过执行均值池来聚合每个时间步长的前向和后向隐藏状态向量,从而获得词级文本特征{t1,…,tl};
25、通过自注意力机制,将上述l个词级文本特征{t1,…,tl}细化为为实例级的文本特征ti。
26、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,共识级的视觉特征获取方式为:
27、
28、
29、其中wv∈rd×d为可学习的参数矩阵,为表示语义特征zi对应的显著性得分,λ控制softmax函数的平滑度;
30、共识级的文本特征获取方式为:
31、
32、
33、其中wt∈rd×d为可学习的参数矩阵,为表示语义特征zi对应的显著性得分,λ控制softmax函数的平滑度。
34、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,通过加权和运算得出视觉融合共识特征和文本融合共识特征:
35、cf=βvi+(1-β)vc
36、ff=βti+(1-β)tc
37、其中β是控制两种实例级特征与共识级特征比率的调谐参数。
38、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,将视觉融合共识特征和文本融合共识特征通过多头自注意力层融合方式为:
39、hc=σ(wvvf+wttf)
40、其中wv和wt是一个可学习的参数,σ是sigmoid激活函数。
41、本发明中多头自注意力层包括多头注意力,残差标准化以及前馈网络层;多头注意力计算过程如下:
42、
43、
44、multihead(q,k,v)=woconcat(head1,...,headn)其中q,k,v为上述融合特征hc,和wo为可学习的参数;
45、残差标准化过程如下:
46、
47、hd=ln(x+multihead(x))
48、其中x为上述融合特征hc,μ和σ分别为hc的均值和标准差,γ和β是可学习的参数向量,维度与hc相同,⊙表示逐元素相乘,hd为hc经过残差标准化得到的结果;
49、前馈网络实现过程如下:
50、ffn(x)=max(0,xw1+b1)w2+b2
51、其中x为上述特征hd,w1和w2是网络权重矩阵,b1和b2是偏置项;
52、将前馈网络所得到的结果在进行一次残差标准化,所得到的结果则为多头注意力层融合后的特征he。
53、根据本发明提供的一种融合视觉与文本共识特征的医学影像报告生成方法,生成医学影像报告方式为:
54、基于目标输出掩蔽多头注意力,过程如下:
55、a`=a+m
56、其中,a`为掩蔽多头注意力的结果,a为多头注意力,m为掩蔽矩阵,其上三角部分包括对角线设置为非常小的值如负无穷,而其他位置为0,且m和a维度相同。
57、将上述掩蔽多头注意力的结果进行残差标准化、前馈网络和残差标准化处理后,所获得的结果作为多头注意力中的q,将上述得到的结果he作为多头注意力中的k,v,放入多头注意力后,经过残差标准化、前馈网络和残差标准化处理,放入linear&softmax层,经过线性变化以及用softmax将线性变化的结果转换为分布概率,最后生成医学影像报告。
58、本发明采用的以上技术方案,与现有技术相比,具有的优点是:本方法融合了视觉特征和文本特征以及知识图谱中的先验知识,以提高报告的准确性和可靠性。
本文地址:https://www.jishuxx.com/zhuanli/20240614/87106.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。