一种基于代谢物的自发性早产风险预测模型及其构建方法和应用与流程
- 国知局
- 2024-07-11 17:39:33
本发明属于生物医学,具体涉及一种基于代谢物的自发性早产风险预测模型及其构建方法和应用。
背景技术:
1、早产(ptb)是全世界的一个重大公共卫生问题。它是导致小于5岁婴儿死亡的直接原因,与存活婴儿的严重并发症具有极大的相关性。每年全世界约有15万新生儿早产,占全球活产儿总数的11%,早产率从几个欧洲国家的约5%到非洲的18%不等。在过去的20年里,早产率一直在稳步上升。在全球65个国家中,超90%国家的早产率在过去1年内都有所上升。2010年全球早产率约为6.14%,相当于约8万活产儿,其中约81.1%发生在亚洲和撒哈拉以南非洲。超过75%的围生儿死亡率以及50%的围产期和远期疾病与早产相关联。早产是全球儿科人群死亡的主要原因。随着过去几十年新生儿护理技术的重大进步,早产儿(妊娠37周<)的存活率有所提高,特别是极早产儿(妊娠28周<)的存活率有所提高。尽管技术进步提高了这些脆弱人群的生存率,但早产仍与严重的并发症相关,包括ivh、nec、bpd和感觉障碍。
2、目前,发达国家中约有占所有分娩的12.5%的早产案例,并且与死亡率和发病率的显着增加有关。who将早产定义为妊娠37周前或自女性末次月经第一天起少于259日的所有分娩。早产可根据胎龄进一步细分:极早产(<28周)、早产(28-<32周)和中度早产(妊娠32-<37周)。且导致长期并发症,不良结局的机率和严重程度随着胎龄的降低和护理质量的降低而增加。早产有两种类型——自发性和医源性。在受自发性早产影响的病例中,宫缩在第37周之前开始,没有任何临床干预,主要是由于宫颈功能不全或宫内感染等。另一方面,医源性早产发生在严重的妊娠并发症中,例如先兆子痫(pe)或胎儿生长受限(fgr)。因此,及时发现自发性早产(sptb)是预防高风险妊娠的一项艰难挑战。研究表明约50%的sptb主要发生在缺乏临床危险因素的女性中。目前的sptb诊断方法包括:产科访谈、产妇特征和宫颈经阴道超声检查,但其并没有解决新生儿早产的问题。这就是为什么sptb是一个困难且复杂的现实问题的原因。这一现实问题源于妊娠数据的性质,此类数据具有动态变化,嘈杂,并且通常包含重要变量组的缺失数据的特点。因研究中需兼顾各种各样的潜在因素以及持续缺乏可靠的变量数据的特性,sptb的预测更具挑战性。
3、此外,因机器学习的发展对生物学产生的新见解,即在理解从现代高通量实验中收集或生成的大量数据的结果或趋势方面提供了诸多可能性。机器学习常用的的工具包括随机森林、支持向量机、人工神经网络和遗传算法。在处理代谢组学步骤中,监督机器学习方法有助于峰值选取、归一化和缺失数据插补。对于知识驱动的分析,机器学习有助于生物标志物检测、分类和回归、生化途径识别等。因而,更好地了解潜在变量并使用机器学习方法来开发更好地预测sptb的新方法至关重要。
技术实现思路
1、本发明的目的是提供一种基于代谢物的自发性早产风险预测模型及其构建方法,通过3-丙酸、povpc、亚油酸肉碱和磷脂酰肌醇4种代谢物进行构建,能可靠地反映胎儿缺陷或产前异常的风险。
2、为实现上述目的,本发明提供了如下方案:
3、本发明提供一种基于代谢物的自发性早产风险预测模型,所述基于代谢物的自发性早产风险预测模型基于4种代谢物进行构建,所述4种代谢物为3-丙酸、povpc、亚油酸肉碱和磷脂酰肌醇。
4、本发明还提供一种基于代谢物的自发性早产风险预测模型的构建方法,包括以下步骤:
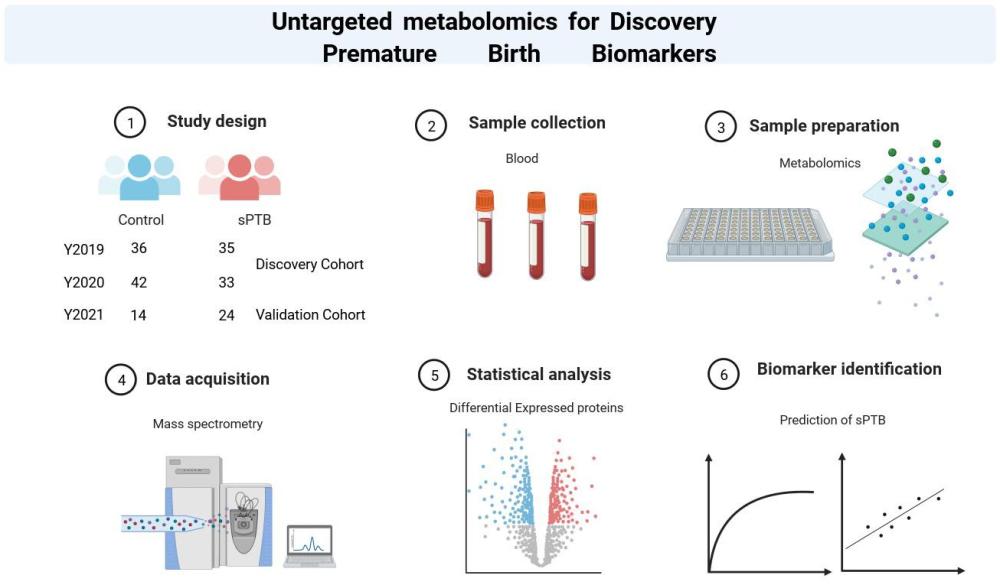
5、(1)样本的收集:选择自发性早产病例作为早产组,选择分娩胎龄不小于37周的参与者作为对照组,分别收集早产组和对照组的血浆;
6、(2)质谱前样本的处理:将步骤(1)中收集的血浆进行代谢物提取,进行代谢组学样本前处理;
7、(3)质谱检测:将步骤(2)中进行血浆样本前处理后的血浆样本进行色谱检测和高分辨质谱检测;
8、(4)质谱的数据处理:将经步骤(3)检测后的数据进行代谢物鉴定、数据归一化、缺失值填充、数据转换;
9、(5)代谢物风险预测模型的构建:将经步骤(4)处理后的数据经生信分析后通过机器学习建立基于3-丙酸、povpc、亚油酸肉碱和磷脂酰肌醇4种代谢物的代谢物风险预测模型。
10、进一步的,在步骤(2)中,所述代谢物提取的具体步骤为:4℃环境下解冻所述步骤(1)中收集的血浆样本,精确取100μl样本,加入4倍体积的提取试剂进行代谢物提取,至于摇床上1500rpm,20min振荡混合,混匀后,将96孔板置于离心机中,2200g,4℃条件下离心10min;离心结束后,将全部上清进行冻干;当进行检测时,取冻干样本加入200μl的复溶剂(0.1%fa水,含混合同位素内标溶液)进行复溶,质谱上机5μl用于定量分析。
11、进一步的,在步骤(3)中,所述色谱检测的条件为:将所述步骤(2)中处理的样品在vanquish超高效液相色谱仪上通过反相色谱柱和亲水色谱柱对其中的代谢物进行分离,然后再分别进行高分辨质谱检测;流动相为水/甲醇,溶剂均加入0.1%fa和2mm甲酸铵缓冲盐,代谢物在acquitytm beh c18(waters co.,usa,1.7μm,2.1×100mm)柱子上分离,洗脱梯度如下:12min内有机相从2%升高到100%,多余的6min用于冲洗和平衡柱子;流速和柱温分别为0.3ml/min和40℃,分别采用正离子或负离子模式进行检测。
12、进一步的,在步骤(3)中,所述高分辨质谱检测的条件为:代谢物检测在质谱仪qexactive plus质谱仪上完成,数据依赖型采集方式采集数据;质谱采用加热电喷雾离子源,正离子检测模式离子化电压为4kv,负离子检测模式为3.5kv,鞘气流速为45arb,辅助气体流速为10arb,加热器温度为355℃,毛细管温度为320℃,离子传输透镜rf水平为50%;全扫分辨率为70,000@m/z200,agc为1e6,最大离子进样时间为100ms,扫描质核比范围为70~1050m/z,二级扫描分辨率为17,500@m/z 200,agc为1e5,最大离子进样时间为50ms扫描质核比范围为70~1050m/z,标准化碰撞能量为40%,使用超纯氮气作为碎裂气体。
13、进一步的,在步骤(4)中,所述代谢物鉴定使用compound discoverer软件处理全扫描和数据依赖性ms2代谢谱数据,以进行全面的组分提取;采用xcalibur quan browser提取总离子流图曲线下面积值作为代谢物的定量信息提取;代谢物结构鉴定通过比对检测获得的一级、二级质谱图与本平台自建标准品ms/ms数据库,hmdb数据库,nist数据库和mzcloud数据库进行匹配打分,对于代谢物鉴定或结构注释,先决条件为母离子质量准确性介于±5ppm范围内,保留时间偏差介于±0.2min范围内,同位素信息和相对同位素丰度模式拟合分数70%用于确认化学式;所述同位素信息为10ppm范围内至少包含一个同位素;最终鉴定打分score值大于80的代谢物注释结果再次经过专业技术人员人工审核后,将来自多种检测方法的代谢物定量原始信息合并在一起,合并过程中,将重复检测到的代谢物定量信息排除,以保证代谢物定量信息的独特性,数据合并后再进行数据预处理过程;
14、所述数据归一化通过vsn算法将所有的数据映射到同一尺度,让每一个特征数据保持相同的影响力;
15、所述缺失值填充为首先对检测结果缺失值进行评估,去除缺失值大于80%的代谢物;然后对于缺失值进行填充,进行填充的方法为极小值、中位数、平均值、knn、随机森林及最大期望值中的任一种;
16、所述数据转换为log2数据转化。
17、进一步的,在步骤(5)中,所述生信分析包括代谢组学质控分析、差异代谢组学分析。
18、进一步的,在步骤(5)中,所述机器学习的具体步骤为:
19、s1、以2020年采集的血浆样本数据作为训练集来训练模型,以2019年采集的血浆样本数据作为验证集,以2021年采集的血浆样本数据作为外部验证集来进行模型优化和验证;
20、s2、使用python3.10编程语言中的scikitlearn包实现一个c支持向量分类;
21、s3、采用sklearn.feature\uselection.sequentialfeatureselector-transformer的顺序特征选择方法来选择特征的最佳组合;
22、s4、使用sklearn.model_selection.gridsearchcv函数对每个特征组合进行交叉验证网格搜索,优化支持向量机模型中的超参数;
23、s5、在网格搜索阶段,使用训练集中的超参数组合训练不同的支持向量分类模型,其中c范围为0.001~1000,区间为10;kernel选择linear,poly,rbf,degree 2~3,间隔1;gamma范围为0.0001至1000,间隔为10;
24、s6、在对多个预测模型进行评价后,选择参数c=100,gamma=0.01,kernel=rbf的预测模型。
25、进一步的,在步骤s3中,所述顺序特征选择方法需要复位的参数有两个:n_features_to_select,范围为1到10,间隔为1;还分别进行正向选择和反向选择的方向。
26、本发明还提供一种所述的基于代谢物的自发性早产风险预测模型在预测自发性早产风险中的应用。
27、母体的生理过程适应于支持胎儿的生存,胎儿组织作为内分泌器官,产生多种蛋白质进入母体和胎儿循环。因此,在正常怀孕期间,在母体循环中可以发现一系列母体和胎儿物质。由于妊娠或遗传异常,循环物质的这种平衡可能被扰乱。鉴定妊娠特异性的母体或胎儿循环中的蛋白质有助于产前诊断或预后的生物标志物,并可能有助于更好地了解潜在的病理生理学。妊娠早期疾病的循环标志物可能在临床症状出现之前用作预后或诊断性疾病标志物,而妊娠后期检测到的生物标志物可能与疾病的实际表型更密切相关。“组学”时代显著增加了识别疾病生物标志物的潜力。在过去十年中,蛋白质组学使研究人员能够使用口腔拭子识别早产儿nec的预测生物标志物。更具体地说,血浆蛋白质组学先前已经确定了可能在早产儿视网膜病变发展中起作用的蛋白质。然而,迄今为止,对血浆蛋白生物标志物预测早产儿其他结局的研究有限。
28、临床代谢组学最好被定义为旨在改善医疗实践的代谢组学分析。因此,临床代谢组学应该导致与临床状况特异性相关的生物标志物的鉴定。这些生物标志物可以用于诊断、预后或更好地了解病理,最终导致改善治疗。为了使这些生物标志物的临床应用,大多数研究都集中在体液中生物标志物的鉴定上。母亲血液样本的容易采集与血液作为分子运输介质的作用相关联,使血液看成为发现生物标志物的有吸引力的来源。从孕妇身上采集血液可以安全进行,获得的样本量足以进行多次检测。使用母体血液样本还可以鉴定出ds、先兆子痫或iugr等疾病的潜在代谢标记物,因此证实其分析可能可靠地反映胎儿缺陷或产前异常的风险。
29、本发明公开了以下技术效果:
30、本发明使用来自188名妊娠女性的血浆样品进行非靶向全谱代谢组分析,旨在通过发现代谢组学生物标志物,结合临床危险因素,建立风险预测模型,用于预测自发性早产,提供一种适用于妊娠女性的非侵入性早产筛查工具。本发明计算出三个数据集的准确度值、灵敏度值、特异性值及精度值发现其具有良好的准确度、较高的灵敏度、特异性及精度。3-(2-羟基苯基)丙酸、povpc、亚油酸肉碱和pi(16:0/16:0)四种代谢物具有很宽的水平范围,突出了它们对模型预测的重大贡献。
本文地址:https://www.jishuxx.com/zhuanli/20240615/85342.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表