一种基于深度强化学习的机械臂推抓协同方法
- 国知局
- 2024-07-08 11:08:30
本发明属于视觉机器人抓取,具体而言,涉及到一种基于深度强化学习的机械臂推抓协同方法。
背景技术:
1、传统工业机器人已经成熟应用于固定轨迹的任务,然而在现实环境中经常会出现未知的物体以及非结构化的工作环境,在处理一些类似问题或者在抗干扰的方面传统算法存在一些不足。因此拥有自适应能的规划算法收到研究者的重视,例如使用已进行过抓取的图像中人工提取出特征,再利用传统方法学习出提取特征与抓取位姿之间的映射关系。
2、机器人抓取大概可以分为两大类,分析法和经验法。分析法需要建模物体三维模型来找到抓取效果较为稳定的抓取框或者抓取点,但在实践中常常难以准确建模物体,同时这种方法泛用性较低,难以迁移到其他物体上。随着深度学习技术的快速进步,以卷积神经网络为典型的例子,基于经验法的机器人抓取方法也成为了近年来的研究热点。基于深度学习的机器人抓取控制算法常见算法例如滑动窗口法需要对图片进行数据标注,这会消耗大量的标注时间。同时,基于深度学习的机器人抓取控制方法在抓取密集物体堆积场景下的物体时,机械臂抓取成功率较低,这导致了该类方法的泛用度也较差。基于深度强化学习的机器人推抓协同控制方法采用无模型训练方式,训练初期积极样本过少而使训练初期样本利用率低,且经验池回放过程往往不能突出样本重要性,若要达到较高的抓取成功率,则需要大量的训练成本,无法达到满意的训练效果;同时,由于抓取目标的不明确问题,导致抓取成功率较低。
技术实现思路
1、本发明要解决的技术问题是:
2、现有方法在训练初期积极样本过少而使训练初期样本利用率低,且经验池回放过程往往不能突出样本重要性,无法达到满意的训练效果;同时,由于抓取目标的不明确导致抓取成功率较低。
3、本发明为解决上述技术问题所采用的技术方案:
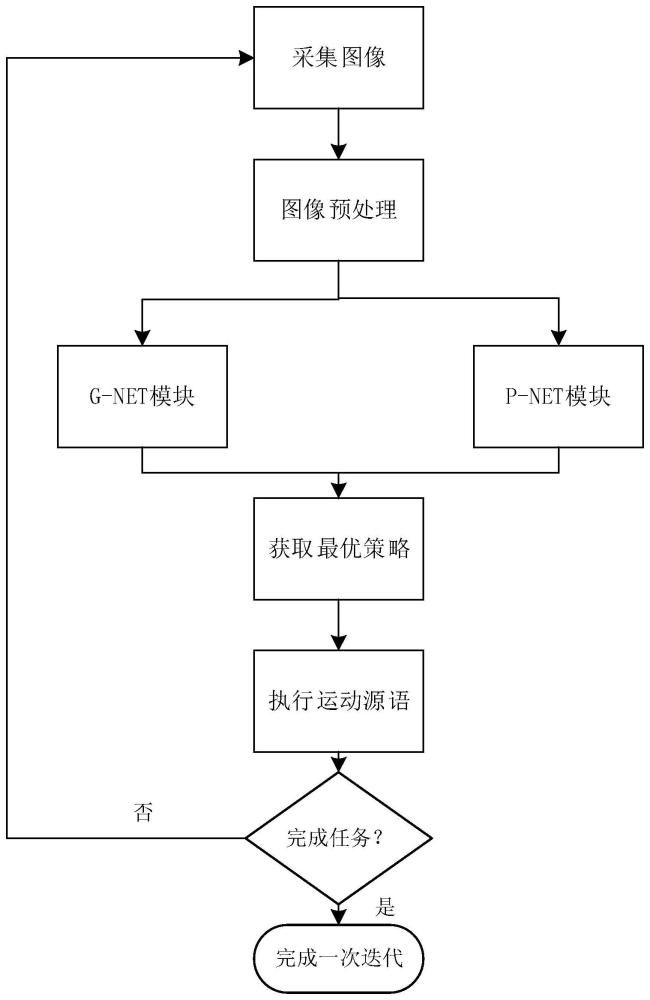
4、本发明提供一种基于深度强化学习的机械臂推抓协同方法,包括如下步骤:
5、步骤一、采集任务场景中rgb-d图像,对图像进行雅可比转换,对图像进行预处理,得到rgb-d高度图像;
6、步骤二、将rgb-d高度图像进行语义分割,识别各物体的位置信息,根据物体的位置信息计算目标中心分散度度量,选取抓取难度最小的物体作为目标抓取物体,并根据目标物体生成对应的掩膜图像;
7、步骤三、建立基于fcn网络和dqn框架构建预测模型,所述fcn网络包括网络主干、g-net和p-net网络分支;
8、步骤四、通过网络主干对rgb-d图像、rgb-d高度图像以及掩膜图像分别进行特征提取,采用g-net和p-net进行特征融合和上采样,得到两个的q值热力图;
9、步骤五、使用贪婪策略生成抓取策略;
10、步骤六、基于抓取策略执行抓取动作,根据场景反馈计算动作的奖励,采用优先级经验回放方法从经验池中采样一个样本,计算其td-error,对预测模型参数进行更新,至达到预设的训练次数阈值;
11、步骤七、采用训练好的预测模型进行任务场景中的推抓操作。
12、进一步地,步骤一中所述对图像进行预处理包括对图像进行双边滤波处理,对滤波后的图像分别进行腐蚀、膨胀、开运算、闭运算处理,最后对图像进行二值化处理。
13、进一步地,步骤二中所述根据物体的位置信息计算目标中心分散度度量,具体计算公式为:
14、
15、式中,pa和pb分别表示物块a和物块b的坐标,k表示场景中总物块的数量,t表示物块的离散程度。
16、进一步地,步骤四中所述网络主干为densenet-121,通过网络主干对rgb-d图像、rgb-d高度图像以及掩膜图像分别进行特征提取,得到3072通道的特征图。
17、进一步地,所述g-net和p-net都包含两个1x1的conv2d和两个batchnorm2d,通过第一个1x1的卷积层将3072通道的特征图降维到64通道,通过第二个1x1的卷积层将64通道的特征图降维到1通道,之后再通过上采样将图像分辨率放大到16倍。
18、进一步地,步骤五中具体包括如下过程:
19、将掩膜图像与q值热力图进行点乘,将结果图像中的最大预测值q点,并将其转换为运动原语,包含动作执行位置点(x,y,z)和执行动作角度,即为当前状态的抓取策略。
20、进一步地,步骤六中经验池中样本为执行动作前的场景图像s、执行动作后的场景图像s′、执行动作的位姿信息a与奖励信息r的集合(s,a,r,s′)。
21、进一步地,步骤六中采用优先级经验回放方法更新预测模型参数,根据td-error计算该分组的采样概率,即:
22、psample∝|δt|+ε
23、式中,psample表示样本的被采样概率,|δt|表示神经网络估计的误差,ε表示超参数。
24、进一步地,步骤六中采用sumtree方法进行优先级的采样和更新。
25、进一步地,所述采用sumtree方法进行优先级的采样和更新采样,具体为:首先生成一个[0,sum]区间内的随机数,然后从根节点开始,根据随机数的大小,选择左子节点或右子节点,至到达叶子节点,叶子节点即采样的经验;更新时,只更新受影响的节点,即从叶子节点到根节点的路径上的所有节点,每个节点的更新量等于其左右子节点的更新量之和。
26、相较于现有技术,本发明的有益效果是:
27、一、本发明提出了一个目标中心分散度度量的指标,它能判断物体的离散度,在训练过程中它既可以作为g net模块的决策优先级标准,也可以作为p net的奖励软函数。这一指标针使得决策模块会选择抓取难度较低的目标物体,增加了神经训练初期的任务完成率,丰富了积极样本的浓度,加快了训练速率。
28、二、本发明改进了全卷积网络的主干结构,添加了对掩膜图像进行特征提取的主干网络,通过设计多输入的网络结构实现多特征融合,增加了神经网络的处理能力。
29、三、本发明改进了经验池回放的采样策略,通过重要性采样方法来代替现存强化学习算法所使用的均匀采样方法,改进了参数更新的效果。
技术特征:1.一种基于深度强化学习的机械臂推抓协同方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,步骤一中所述对图像进行预处理包括对图像进行双边滤波处理,对滤波后的图像分别进行腐蚀、膨胀、开运算、闭运算处理,最后对图像进行二值化处理。
3.根据权利要求1所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,步骤二中所述根据物体的位置信息计算目标中心分散度度量,具体计算公式为:
4.根据权利要求3所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,步骤四中所述网络主干为densenet-121,通过网络主干对rgb-d图像、rgb-d高度图像以及掩膜图像分别进行特征提取,得到3072通道的特征图。
5.根据权利要求4所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,所述g-net和p-net都包含两个1x1的conv2d和两个batchnorm2d,通过第一个1x1的卷积层将3072通道的特征图降维到64通道,通过第二个1x1的卷积层将64通道的特征图降维到1通道,之后再通过上采样将图像分辨率放大到16倍。
6.根据权利要求5所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,步骤五中具体包括如下过程:
7.根据权利要求6所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,步骤六中经验池中样本为执行动作前的场景图像s、执行动作后的场景图像s′、执行动作的位姿信息a与奖励信息r的集合(s,a,r,s′)。
8.根据权利要求7所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,步骤六中采用优先级经验回放方法更新预测模型参数,根据td-error计算该分组的采样概率,即:
9.根据权利要求8所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,步骤六中采用sumtree方法进行优先级的采样和更新。
10.根据权利要求9所述的基于深度强化学习的机械臂推抓协同方法,其特征在于,所述采用sumtree方法进行优先级的采样和更新采样,具体为:首先生成一个[0,sum]区间内的随机数,然后从根节点开始,根据随机数的大小,选择左子节点或右子节点,至到达叶子节点,叶子节点即采样的经验;更新时,只更新受影响的节点,即从叶子节点到根节点的路径上的所有节点,每个节点的更新量等于其左右子节点的更新量之和。
技术总结本发明一种基于深度强化学习的机械臂推抓协同方法,属于视觉机器人抓取领域,为解决无模型训练在训练初期样本利用率低,且经验池回放过程往往不能突出样本重要性,无法达到满意的训练效果的问题;以及由于抓取目标的不明确导致抓取成功率较低的问题。本发明通过计算目标中心分散度度量,选取抓取难度最小的物体作为目标抓取物体,并根据目标物体生成对应的掩膜图像;建立基于FCN网络和DQN算法框架的预测模型,通过网络主干对RGB‑D图像、RGB‑D高度图像以及掩膜图像分别进行特征提取,采用G‑Net和P‑Net进行特征融合和上采样,得到两个的Q值热力图;采用优先级经验回放方法从经验池中进行采样并进行模型参数更新,最终得到预测模型完成任务场景中的推抓操作。技术研发人员:苏丽,何志远受保护的技术使用者:哈尔滨工程大学技术研发日:技术公布日:2024/6/13本文地址:https://www.jishuxx.com/zhuanli/20240617/52275.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。