无文本转录的全局韵律类型转移的制作方法
- 国知局
- 2024-06-21 10:38:28
背景技术:
1、本发明总体上涉及语音处理,并且更具体地涉及无文本转录的全局韵律(prosody)类型转移。
2、韵律在表征说话者或情绪的类型中起重要作用,但大多数非平行语音或情绪类型转移算法不转换任何韵律信息。韵律的两个主要成分是音高(pitch)和节奏(rhythm)。节奏概述了电话持续时间的序列,并且表达短语、语音速率、暂停、以及显著性的一些方面。音高反映了语调(intonation)。将韵律信息(特别是节奏分量)从语音分离出来是有挑战性的,因为它涉及打断输入语音与分离的语音表达之间的同步。因此,大多数现有的韵律类型转移算法将需要依赖于某种形式的文本转录来识别内容信息,这将应用仅限于高资源语言。高资源语言是存在许多数据资源的语言,使得可以开发用于这些语言的基于机器学习的系统。
3、语音类型转移是指将源语音转移到目标域的类型,同时保持内容不变的任务。例如,在语音类型转移中,域对应于说话者身份。在情绪类型传递中,域对应于情绪类别。在这两个任务中,韵律被认为是领域类型的重要部分,例如,不同的说话者或情绪具有独特的韵律模式。然而,在这两种应用中很少有现有技术算法可完全转换韵律方面,并且需要转录。
技术实现思路
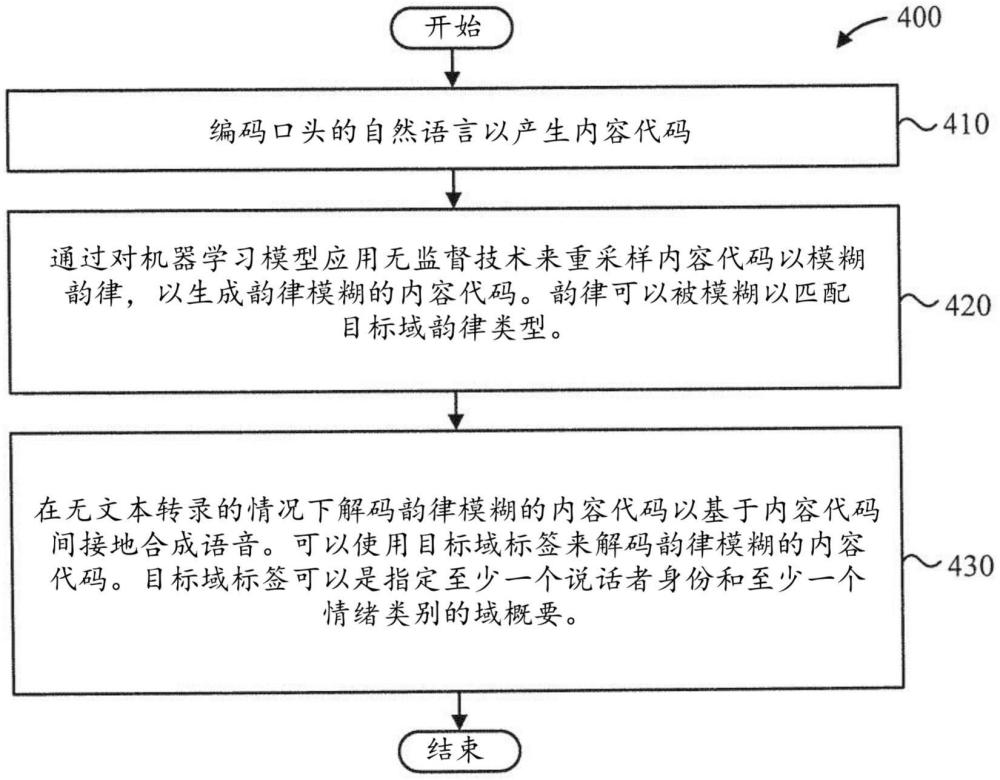
1、根据本发明的方面,提供了一种使用机器学习模型的用于口头的自然语言(spoken natural language)中的韵律的分离的计算机实现的方法。该方法包括由计算设备对口头的自然语言编码以产生内容代码。该方法还包括由计算设备在无文本转录的情况下,通过对机器学习模型应用无监督技术来重采样内容代码以模糊韵律,以生成韵律模糊的内容代码。该方法附加地包括由计算设备解码韵律模糊的内容代码以基于内容代码间接地合成语音。
2、在实施例中,可以使用基于相似度的随机重采样技术来重采样内容代码,基于相似度的随机重采样技术将相似度超过阈值量的内容代码段缩短(使用基于相似度的下采样)或者延长(使用基于相似度的上采样)为相等长度,以形成韵律模糊的内容代码。在实施例中,高于阈值的相似度可以是韵律相似度阈值。
3、在实施例中,可以通过自我表现表达学习(self-expressive representationlearning)来引导重采样步骤。
4、在实施例中,通过重采样步骤可以在内容代码中使多个韵律分量之中的节奏分量模糊,以生成韵律模糊的内容代码。
5、在实施例中,可以使用目标域标签来解码韵律模糊的内容代码。在实施例中,目标域标签可以是指定至少一个说话者身份和至少一个情绪类别的域概要。
6、在实施例中,可以通过两阶段训练技术来执行重采样步骤,两阶段训练技术防止执行编码步骤的编码器与执行解码器步骤的解码器串通以共同编码和解码节奏信息。在实施例中,两阶段训练技术可包括同步训练部分和异步训练部分,同步训练部分使用样本长度对准器对准样本长度并恢复输入韵律,异步训练部分缺少样本长度对准器以使解码器能够推断韵律。
7、根据本发明的其他方面,提供了一种使用机器学习模型的用于口头的自然语言中的韵律的分离的计算机程序产品。计算机程序产品包括计算机可读存储介质,计算机可读存储介质具有程序指令。程序指令可由计算机执行以使计算机通过计算机的编码器编码口头的自然语言以产生内容代码。程序指令可由计算机执行,以使计算机由计算机的重采样器在无文本转录的情况下,通过对机器学习模型应用无监督技术来重采样内容代码以模糊韵律,以生成韵律模糊的内容代码。程序指令可由计算机执行以使计算机通过计算机的解码器对韵律模糊的内容代码进行解码以基于内容代码间接地合成语音。
8、根据本发明的又一些方面,提供了一种全局韵律转移系统。该系统包括用于存储程序代码的存储器设备。该系统还包括处理器设备,可操作地耦合到存储器设备,用于运行程序代码以编码口头的自然语言以产生内容代码。处理器设备还运行程序代码以在无文本转录的情况下,通过对机器学习模型应用无监督技术对内容代码重采样来模糊韵律,以生成韵律模糊的内容代码。处理器设备还运行程序代码以解码韵律模糊的内容代码以基于内容代码间接地合成语音。
9、从以下将结合附图阅读的对说明性实施例的详细描述,这些和其他特征和优点将变得清晰。
技术特征:1.一种使用机器学习模型用于口头的自然语言中的韵律的分离的计算机实现的方法,所述方法包括:
2.根据权利要求1所述的计算机实现的方法,其中,韵律传达所述口头的自然语言中的节奏和音高。
3.根据权利要求1所述的计算机实现的方法,其中,所述编码步骤由所述计算设备的编码器执行,所述重采样步骤由所述计算设备的重采样器执行,并且所述解码步骤由所述计算设备的解码器执行。
4.根据权利要求1所述的计算机实现的方法,其中,所述内容代码是使用基于相似度的随机重采样技术被重采样的,所述基于相似度的随机重采样技术使用基于相似度的下采样缩短或者使用基于相似度的上采样延长相似度超过阈值量的内容代码片段为相等长度,以形成韵律模糊的内容代码。
5.根据权利要求4所述的计算机实现的方法,其中,高于所述阈值的相似度是韵律相似度阈值。
6.根据权利要求1所述的计算机实现的方法,其中,所述重采样步骤是通过自我表现表达学习来引导的。
7.根据权利要求1所述的计算机实现的方法,其中,通过所述重采样步骤在所述内容代码中使多个韵律分量之中的节奏分量模糊,以生成韵律模糊的内容代码。
8.根据权利要求1所述的计算机实现的方法,其中,所述韵律模糊的内容代码是使用目标域标签进行解码的。
9.根据权利要求8所述的计算机实现的方法,其中,所述目标域标签是指定至少一个说话者身份和至少一个情绪类别的域概要。
10.根据权利要求1所述的计算机实现的方法,其中,所述方法被配置为具有编码组件、重采样组件、和解码组件的基于云的服务。
11.如权利要求1所述的计算机实现的方法,其中所述重采样步骤是通过两阶段训练技术来执行的,所述两阶段训练技术防止执行编码步骤的编码器与执行解码器步骤的解码器串通以共同地编码和解码节奏信息。
12.根据权利要求11所述的计算机实现的方法,其中,所述两阶段训练技术包括同步训练部分和异步训练部分,所述同步训练部分使用样本长度对准器对准样本长度并恢复输入韵律,所述异步训练部分缺少样本长度对准器以使解码器能够推断韵律。
13.一种计算机程序产品,用于使用机器学习模型的口头的自然语言中的韵律的分离,所述计算机程序产品包括具有程序指令的计算机可读存储介质,所述程序指令可由计算机执行以使所述计算机:
14.根据权利要求13所述的计算机程序产品,其中,所述内容代码是使用基于相似度的随机重采样技术被重采样的,所述基于相似度的随机重采样技术使用基于相似度的下采样缩短或者使用基于相似度的上采样延长相似度超过阈值量的内容代码片段为相等长度,以形成韵律模糊的内容代码。
15.根据权利要求13所述的计算机程序产品,其中,所述重采样步骤是通过自我表现表达学习来引导的。
16.根据权利要求13所述的计算机程序产品,其中,所述韵律模糊的内容代码是使用目标域标签进行解码的。
17.根据权利要求16所述的计算机程序产品,其中,所述目标域标签是指定至少一个说话者身份和至少一个情绪类别的域概要。
18.根据权利要求13所述的计算机程序产品,其中,所述重采样步骤是通过两阶段训练技术执行的,所述两阶段训练技术防止执行所述编码步骤的编码器与执行所述解码器步骤的解码器串通以共同编码和解码节奏信息。
19.根据权利要求18所述的计算机程序产品,其中,所述两阶段训练技术包括同步训练部分和异步训练部分,所述同步训练部分使用样本长度对准器对准样本长度并恢复输入韵律,所述异步训练部分缺少样本长度对准器以使解码器能够推断韵律。
20.一种全局韵律转移系统,包括:
技术总结提供了一种使用机器学习模型用于口头的自然语言中的韵律的分离的计算机实现的方法。该方法包括由计算设备对口头的自然语言编码以产生内容代码。该方法还包括由计算设备在无文本转录的情况下通过对机器学习模型应用无监督技术来重采样内容代码以模糊韵律,以生成韵律模糊的内容代码。该方法附加地包括由计算设备解码韵律模糊的内容代码以基于内容代码间接地合成语音。技术研发人员:钱恺之,张阳,常十雨,熊瑾珺,淦创,D·考克斯受保护的技术使用者:国际商业机器公司技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/20868.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。