一种基于深度学习的精神分裂症语音检测方法及系统与流程
- 国知局
- 2024-06-21 10:38:27
本发明涉及个人健康风险评估,具体涉及一种基于深度学习的精神分裂症语音检测方法及系统。
背景技术:
1、精神分裂症是一种慢性神经退化性障碍,具有复发率高、致残率高等特点,常伴随患者终生,严重损害了患者的生活质量和社会认知,其主要临床表现包含幻听、妄想、言语(思维)紊乱、行为异常、阴性症状(如语言贫乏、情感淡漠等)。若能在精神症状发作的早期采取合理有效的自动检测手段,及时加以干预治疗,将有助于改善患者的病况。
2、目前精神分裂症的临床诊断和监测评估的方法主要有以下几种方式:一是脑影像学方法,通过功能核磁共振(functional nuclear magnetic resonance,fmri)诊断脑实质及脑功能的改变,但仪器操作复杂,检测费用高昂,且缺乏客观的生物学标记;二是脑电信号方法,但α波、β波均无特异性,对诊断的价值有限;三是视频分析方法,相比于正常人,精神分裂症患者具有更少的身体运动和更呆滞的面部表情,可以通过分析提取受试者的表情动作特征实现自动检测,但目前的研究瓶颈在于缺乏统一的实验范式,尚处于起步阶段,未达到临床辅助诊断水平;四是基因组学方法,但在基因测序捕捉时仍存在假阳性和假阴性的问题。
3、研究表明精神分裂症的阴性症状与语音情感表达密切相关,随着大数据、人工智能、语音信号处理算法的飞速发展,将语音情感特征应用于精神分裂症的研究,将为临床诊断精神分裂症提供全新的检测方法。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供一种克服上述全部或至少一部分问题的基于深度学习的精神分裂症语音检测方法及系统。
2、根据本发明的一个方面,提供了一种基于深度学习的精神分裂症语音检测方法,包括:
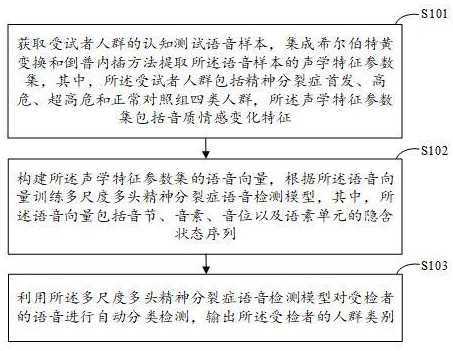
3、获取受试者人群的认知测试语音样本,集成希尔伯特黄变换和倒谱内插方法提取所述语音样本的声学特征参数集,其中,所述受试者人群包括精神分裂症首发、高危、超高危和正常对照组四类人群,所述声学特征参数集包括音质情感变化特征;
4、构建所述声学特征参数集的语音向量,根据所述语音向量训练多尺度多头精神分裂症语音检测模型,其中,所述语音向量包括音节、音素、音位以及语素单元的隐含状态序列;
5、利用所述多尺度多头精神分裂症语音检测模型对受检者的语音进行自动分类检测,输出所述受检者的人群类别;
6、所述集成希尔伯特黄变换和倒谱内插方法提取所述语音样本的声学特征参数集包括:
7、在所述语音向量中加入均值与方差具有相同分布的不同噪声,合成目标语音信号;
8、计算模态函数中各个imf分量对应的边际谱的频带能熵比的比值,筛选出包含共振峰的imf分量,以重构所述语音向量;
9、利用倒谱内插方法提取多个所述共振峰的声学特征参数集,其中,所述声学特征参数集包括各个共振峰频率、带宽、幅值对应的峰值数、均值、方差、中位数、众数、极差、偏度以及峭度。
10、更进一步地,对所述多尺度多头精神分裂症语音检测模型的优化函数进行范数优化,所述范数的具体公式为:
11、
12、其中,…为向量参数。
13、更进一步地,所述优化函数采用rmsprop算法,根据学习率和修正矩阵偏差更新所述rmsprop算法的参数变化量,所述参数变化量更新的具体公式为:
14、
15、其中,为参数变量量,为学习率,为超参数,为一阶修正偏差,为二阶修正偏差。
16、更进一步地,所述一阶修正偏差的具体公式为:
17、
18、其中,为一阶系数,s为一阶矩估计,t为时间步长;
19、所述二阶修正偏差的具体公式为:
20、
21、其中,为二阶系数,为二阶矩估计。
22、更进一步地,所述多尺度多头精神分裂症语音检测模型的损失函数为:
23、
24、其中,k为第k个词,k为词的个数,为语音向量中词的序号,为序列模型解码器第k个词的概率,为前一个词的序号,为上下文信息,x为上下文向量特征。
25、更进一步地,所述多尺度多头精神分裂症语音检测模型中各个卷积网络模块包括一维卷积、门控单元激活和随机失活操作;
26、所述一维卷积运算的具体公式为:
27、
28、其中,s(t)为卷积运算结果,u,v为自变量为t的函数,a是累加变量;
29、所述门控单元激活的具体公式为:
30、
31、其中,k为当前网络层的输入,f、g为卷积核,为激活函数,b、c为偏置参数。
32、更进一步地,所述方法还包括:
33、将所述认知测试语音样本划分为长度为3秒的片段,分别提取所述片段的基因频率、响度、频谱通量、能量以及尖锐度。
34、更进一步地,在所述根据所述语音向量训练多尺度多头精神分裂症语音检测模型之前,所述方法还包括:
35、对所述语音向量进行归一化,使用的归一化函数具体为:
36、
37、其中,、分别为语音向量列中的最小值及最大值,为归一化后的各元素的值。
38、根据本发明的另一方面,提供了一种基于深度学习的精神分裂症语音检测系统,包括:
39、语音获取模块,用于获取受试者人群的认知测试语音样本,集成希尔伯特黄变换和倒谱内插方法提取所述语音样本的声学特征参数集,其中,所述受试者人群包括精神分裂症首发、高危、超高危和正常对照组四类人群,所述声学特征参数集包括音质情感变化特征;
40、模型训练模块,用于构建所述声学特征参数集的语音向量,根据所述语音向量训练多尺度多头精神分裂症语音检测模型,其中,所述语音向量包括音节、音素、音位以及语素单元的隐含状态序列;
41、分类检测模块,用于利用所述多尺度多头精神分裂症语音检测模型对受检者的语音进行自动分类检测,输出所述受检者的人群类别。
42、根据本发明提供的方案,获取受试者人群的认知测试语音样本,集成希尔伯特黄变换和倒谱内插方法提取所述语音样本的声学特征参数集,其中,所述受试者人群包括精神分裂症首发、高危、超高危和正常对照组四类人群,所述声学特征参数集包括音质情感变化特征;构建所述声学特征参数集的语音向量,根据所述语音向量训练多尺度多头精神分裂症语音检测模型,其中,所述语音向量包括音节、音素、音位以及语素单元的隐含状态序列;利用所述多尺度多头精神分裂症语音检测模型对受检者的语音进行自动分类检测,输出所述受检者的人群类别。本发明集成希尔伯特黄变换和倒谱内插方法提取声学特征,利用多尺度多头精神分裂症语音检测模型对受检者的语音进行自动分类检测,为临床诊断精神分裂症提供全新的检测方法。
43、本发明的技术效果:
44、(1)通过集成希尔伯特黄变换和倒谱内插方法所提取的声学特征,尤其是针对非稳态与非线性信号,在频域各频率分量的幅度保持不变,不仅去除了干扰噪音,使得声学特征更加突出。
45、(2)改进多尺度多头精神分裂症语音检测模型的一维卷积运算,有效地缓解模型的过拟合问题,起到正则化的作用,可以和l1正则化、l2正则化和最大范数约束等方法互为补充。
46、(3)对语音向量进行归一化处理,消除了奇异样本数据导致的不良影响。
47、(4)对多尺度多头精神分裂症语音检测模型的优化函数进行范数优化,使得到的解更为平滑。
48、(5)根据学习率和修正矩阵偏差更新rmsprop算法的参数变化量,使得模型的收敛速度更快,可以避免学习率过大或过小的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20867.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表