一种基于改进残差网络的带噪合成语音检测方法
- 国知局
- 2024-06-21 10:38:23
本发明属于带噪语音合成检测,具体涉及一种基于改进残差网络的带噪合成语音检测方法。
背景技术:
1、人声已被广泛用于生物识别认证,这使得人机交互系统可以取代传统的密码。语音识别技术是指通过识别和分析过程使计算机能够将语音信号转换为相应的文本或命令的技术。自动说话人验证(asv)是一种语音识别技术,通过区分人语音的语音打印特征来识别个体。在许多情况下,asv技术可以取代传统的密码身份验证。成为一种方便有效的认证方法,可以易于应用于远程人员身份验证。
2、但是基于语音的身份验证系统容易受到恶意欺骗攻击,如语音转换和文本转语音的攻击。现有的反合成语音检测研究和asvspoof挑战系列都专注于纯语音。然而,在真实场景中语音会有背景音等噪声,攻击者可以通过在伪造的语音中添加噪声使反伪造检测方法失效。因此,伪造的噪声语音已经成为基于语音的认证系统的一大威胁。
3、目前对合成语音的检测方法主要分为三步,特征提取、模型训练和模型分类。语谱图特征提取方法大多根据生物结构特征(如人耳识别声波所依靠的结构特征)对语音倒谱系数进行提取。常见的倒谱系数有线性频率倒谱系数(lfcc)、梅尔频率倒谱系数(mfcc)、瞬时频率耳蜗滤波器倒谱系数(cfccif)、无限脉冲响应常数q变换倒谱系数(icqc)、基于恒定q变换(cqt)的倒谱系数cqcc等。模型分类主要有生成法、判别法和基于dnn的端到端分类法等。检测模型中常常大量使用传统的残差块。需要解决的问题是:1、在带噪环境下,如何保证模型不被合成语音欺骗;2、面对不同的噪音环境下,如何确保模型的正确识别率不会出现大的波动。
技术实现思路
1、为解决上述技术问题,本发明提出了一种基于改进残差网络的带噪合成语音检测方法,通过在传统残差块上使用特征增强层来代替恒等映射,使得到的改进的残差块具有特征增强和噪声抑制的功能,提高网络对带噪合成语音的检测能力。
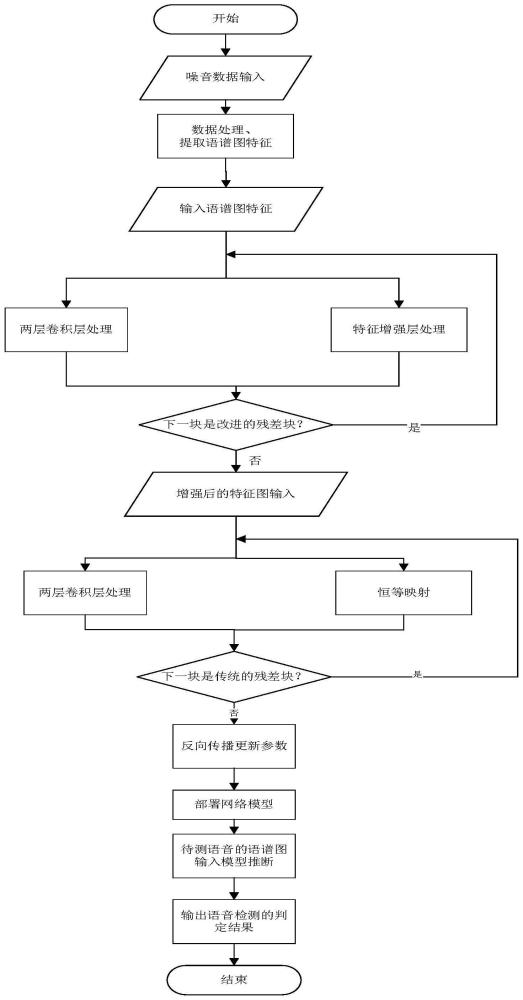
2、本发明采用的技术方案为:一种基于改进残差网络的带噪合成语音检测方法,具体步骤如下:
3、s1、噪音数据输入网络模型的数据处理模块,进行数据处理和语谱图特征提取;
4、s2、模型输入步骤s1提取的语谱图特征到改进的残差块中,分别进行两层卷积层处理和特征增强层处理,将结果相加输入下一层,并判断下一块是否为改进的残差块,若是,重复步骤s2,若否,进入步骤s3;
5、s3、模型输入步骤s2中被改进残差块增强后的语谱图特征到传统的残差块,分别进行两层卷积层处理和恒等映射,将结果相加输入下一层,并判断下一块是否为传统的残差块,若是,重复步骤s3,若否,进入步骤s4;
6、s4、基于步骤s2、s3,语谱图特征依次通过多个改进的残差块和传统残差块后输出真实语音和合成语音的预测分数,并将预测分数和实际分数的损失值反向传播至网络中,根据每一层网络的输入梯度更新网络参数,完成语音检测的训练过程;
7、s5、基于步骤s1-s4完成的模型训练过程,将参数已经训练好的模型放入设备上的合成语音检测推断模块,输出语音的预测分数,最终得到真实语音和合成语音的判定结果,完成语音检测。
8、进一步地,所述步骤s1具体如下:
9、s11、从数据集中获取训练的噪声数据,并检查训练集中语音的采样率;
10、s12、对于所有输入的语音,若语音数据的采样率为16khz,则直接将短语音复制至最长语音的长度,否则使用工具包sox转换语音采样率为16khz,再将短语音复制至最长语音的长度;
11、s13、通过重复短语音来控制所有语音长度相同;
12、s14、将输入的语音转化为语谱图特征输入模型进行特征提取;
13、设定xn表示当前时刻的语音信号,xn-1表示上一时刻的语音信号。将语音信号xn进行预加重处理,得到预加重之后的信号yn:
14、yn=xn-a*xn-1
15、其中,a表示预加重系数。
16、将语音数据按10ms分为短段,然后进行加窗操作:
17、
18、其中,w[n]表示窗函数,α表示一个常数,取值为0.46使窗函数为汉明窗,n表示第n时刻。
19、加窗之后进行快速傅里叶变换,在取幅值平方后对各谱线的振幅都作对数计算后得到语谱图,特征提取完毕。
20、进一步地,所述步骤s2具体如下:
21、s21、模型输入步骤s1提取的语谱图特征到改进的残差块中,进行两层卷积层处理;
22、第l层改进的残差块的特征图输入xl,经过两个卷积层计算直接输入下一层,记两个卷积层的表达式为f(·),得到改进残差块的部分输出f(xl);
23、s22、模型输入步骤s1提取的语谱图特征到改进的残差块中,进行特征增强层处理;
24、s221、根据输入感受野参数p将xl折叠为
25、其中,xl∈rh×w,r表示实数域,h、w分别表示矩阵的宽和高。
26、s222、特征增强层根据视野参数p对输入的语谱图特征进行噪音特征和反合成特征判定,生成噪音特征的抑制权重值和反合成特征的增强权重值;
27、以patch矩阵中每一列作为判定噪声或反合成特征的基本单元,记patch的任意第k列为t表示矩阵的转置操作。
28、根据中是否为当前的极大值来计算权重值并赋值
29、其中,权重赋零值是对噪音特征的直接抑制,表示增强反合成特征的权重值;表示对应的增强权重值,表示中间变量,对应于
30、再遍历所有的k∈[1,...,hw]计算获得用于存储patch矩阵对应位元素的权重值。
31、s223、通过步骤s222得到的所有权重值生成展开后的权重矩阵nl;
32、特征增强层通过将展开到nl∈rh×w,获得针对xl∈rh×w中所有元素的权重矩阵。
33、s224、通过哈达玛积获得经过第l层特征增强层的输出zl=nl*xl;
34、其中,zl表示xl经过特征增强层后得到被增强后的语谱图特征。
35、s23、将步骤s21得到的卷积层输出和步骤s22得到的特征增强层的输出直接相加,得到第l层改进残差块的输出yl=f(xl)+zl=f(xl)+nl*xl;
36、s24、判断下一块残差块是否为改进的残差块,若是,重复步骤s21-s23,若否,进入步骤s3。
37、进一步地,所述步骤s3具体如下:
38、s31、模型输入步骤s2中被改进残差块增强后的语谱图特征到传统的残差块,进行两层卷积层处理;
39、第q(q>l)层传统的残差块的特征图输入x′q,经过两个卷积层计算直接输入下一层,记两个卷积层的表达式为f(·),得到部分输出f(x′q);
40、s32、模型输入步骤s2中被改进残差块增强后的语谱图特征到传统的残差块,进行恒等映射直接输出到下一层;
41、s33、将步骤s31得到的卷积层输出和步骤s32得到的恒等映射的输出直接相加,得到第q层传统的残差块的输出y′q=f(x′q)+x′q;
42、s34、判断下一块残差块是否为传统的残差块,若是,重复步骤s31-s33,若否,进入步骤s4。
43、进一步地,所述步骤s4具体如下:
44、s41、输入语谱图特征,基于步骤s2进行多层改进残差块处理;
45、基于步骤s2,第l层改进残差块的输出yl=f(xl)+nl*xl,第l层改进残差块中两个卷积层的计算过程为f(·),两个卷积层中的输出为f(xl),且由上一层输出直接传播到下一个改进残差块可得xl+1=yl,则第l(l>l)层改进残差块的输入xl:
46、
47、s42、输入语谱图特征,基于步骤s3进行多层传统残差块处理,输出模型预测分数;
48、基于步骤s3,第q层传统的残差块的输入x′q,两个卷积层的计算过程为f(·),两个卷积层中的输出为f(xq′),第q层传统的残差块的输出y′q=f(x′q)+x′q,则x′q(q>q)是第q层传统残差块的输入,通过堆叠传统的残差块获得x′q的表示:
49、
50、s43、反向传播过程中,通过将模型的预测分数与真实分数的损失值反向传播来更新传统残差块参数;
51、通过步骤s2的改进残差块的处理,使传统残差块的输入为被增强后的语谱图特征,在多层的传统残差块中,记δ′为损失函数,则第q层(q<q)传统残差块的输入梯度可由第q层传统残差块的输入梯度表示为:
52、
53、通过梯度在传统残差块中的传播,网络自动更新传统残差块的模型参数。
54、s44、反向传播过程中,通过将模型的预测分数与真实分数的损失值反向传播来更新改进残差块参数;
55、在多层的改进残差块中,记δ为损失函数,在反向传播过程中,第l层特征增强层计算nl权重被视为常量,则第l层(l<l)改进残差块的输入梯度可由第l层改进残差块的输入梯度表示:
56、
57、使深层传播的梯度值一边经过卷积层传播,一边经过多次nl的权重调整后直接输出到浅层的改进残差块中。
58、通过梯度在改进残差块中的传播,网络自动更新改进残差块的模型参数。
59、进一步地,所述步骤s5具体如下:
60、s51、将完整的待检测语音进行步骤s1的数据处理,得到包含语音信息的语谱图特征;
61、s52、将语谱图特征输入已经训练好的模型进行推断,得出真语音和合成语音的输出分数;
62、s53、若真语音分数更高则返回判定为真给用户,否则返回判定为假。
63、本发明的有益效果:本发明的方法通过在传统的残差块上添加了一个特征增强层来代替恒等映射得到改进的残差块,基于改进残差块进行模型训练,得到已训练好的模型,将待测语音进行语音预处理并输入语谱图特征进行模型推断,获得真假语音的输出分数后,将真假判定结果返回给用户,完成语音检测。本发明的方法提出的改进的残差块提高了改进残差网络对于带噪合成语音的检测能力,通过特征增强层控制网络在不同深度时所倾向的噪声抑制和特征增强能力,相比于现有检测方法检测精度更高。
64、本发明的方法适用于具有语音解锁功能的高精度设备,该类设备在噪音环境中受到合成语音威胁较大,在使用了本发明的方法后,能有效检测带噪合成语音,即使攻击者知道了解锁口令并采用合成语音技术生成受害者的语音,也无法通过检测。本发明的方法还适用于在环境噪音较大时,攻击者常常通过合成高噪音语音来欺骗语音解锁的设备,而在使用了本发明的方法后,能有效检测出合成语音。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20857.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表