语音处理方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 10:39:07
本技术涉及语音降噪领域,尤其涉及语音处理方法、装置、设备及存储介质。
背景技术:
1、近年来,语音技术以及芯片半导体技术的高速发展带动了可穿戴式设备的快速发展,例如以无线蓝牙耳机为代表的智能可穿戴式设备成为了市面上最炙手可热的产品之一,各大手机公司相继推出了各自的无线蓝牙耳机产品,这些产品都能实现语音通话,给人们的生活带来了极大的便利。
2、对于无线蓝牙耳机的使用者来说,语音质量决定了其听感舒适度,但是通常无线蓝牙耳机的佩戴者所处的声场环境中充斥着各种噪声,比如马路上的汽车鸣笛声、车载环境中的发动机噪声等。这些复杂声场环境中的噪声和嘈杂人声会降低语音的质量和可懂度,大大降低语音通信的体验。因此,为了提高无线蓝牙耳机中的语音通信在复杂场景下的稳定性和体验感,有必要对语音信号进行降噪处理。
技术实现思路
1、本技术提供语音处理方法、装置、设备及存储介质,以对语音信号进行降噪处理。
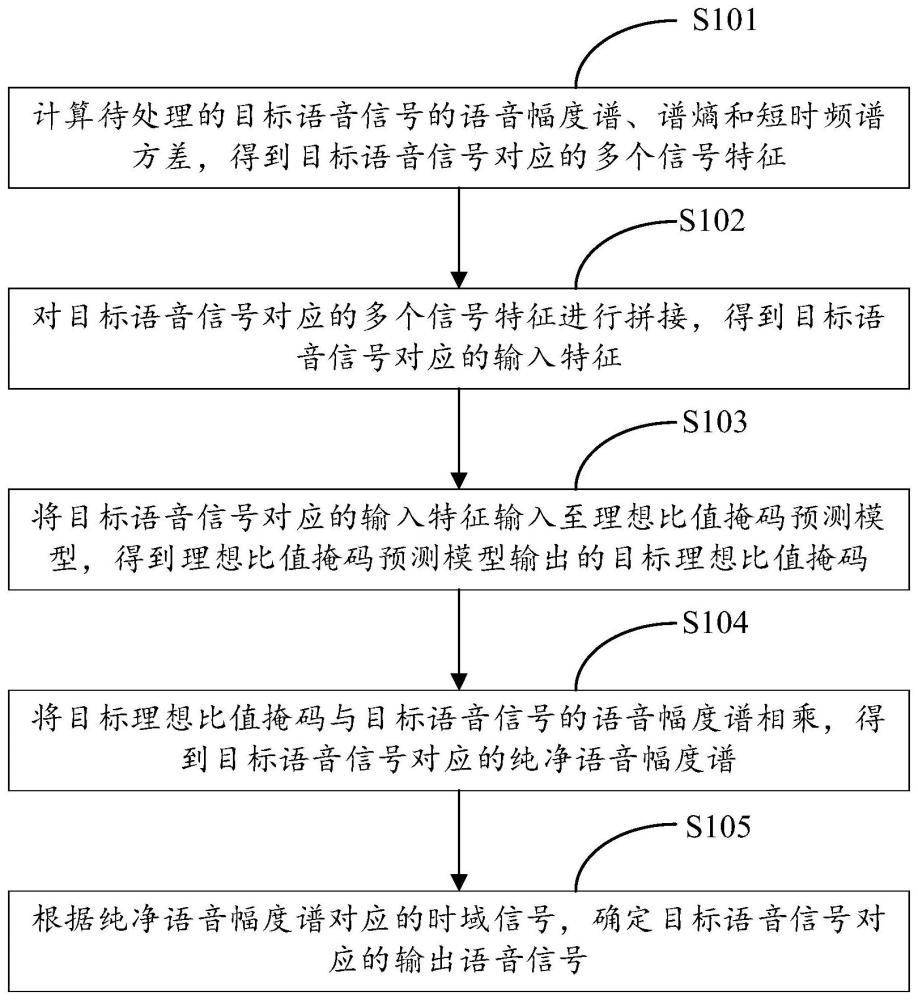
2、第一方面,提供一种语音处理方法,包括:
3、计算待处理的目标语音信号的语音幅度谱、谱熵和短时频谱方差,得到所述目标语音信号对应的多个信号特征;
4、对所述多个信号特征进行拼接,得到所述目标语音信号对应的输入特征;
5、将所述输入特征输入至理想比值掩码预测模型,得到所述理想比值掩码预测模型输出的目标理想比值掩码,所述理想比值掩码预测模型用于输出理想比值掩码,所述理想比值掩码为纯净语音幅度谱与带噪语音幅度谱的比值,所述理想比值掩码预测模型为基于互注意力机制的模型;
6、将所述目标理想比值掩码与所述目标语音信号的语音幅度谱相乘,得到所述目标语音信号对应的纯净语音幅度谱;
7、根据所述纯净语音幅度谱对应的时域信号,确定所述目标语音信号对应的输出语音信号。
8、在该技术方案中,通过计算待处理的目标语音信号的语音幅度谱、谱熵和短时频谱方差,得到目标语音信号对应的多个信号特征,并对目标语音信号对应的多个信号特征进行拼接,得到目标语音信号对应的输入特征,然后将目标语音信号对应的输入特征输入至理想比值掩码预测模型中,得到目标语音信号对应的目标理想比值掩码;最后将目标理想比值掩码与目标语音信号的语音幅度谱相乘,得到目标语音信号对应的纯净语音幅度谱,并根据纯净语音幅度谱对应的时域信号,得到目标语音信号对应的输出语音信号;由于理想掩码比值为纯净语音幅度谱与带噪语音幅度谱的比值,将目标理想掩码比值与目标语音信号的语音幅度谱相乘,得到目标语音信号对应的纯净语音幅度谱,可实现对语音信号中的噪声的滤除,根据纯净语音幅度谱对应的时域信号得到目标语音信号对应的输出语音信号,实现了对语音信号的降噪处理;另外,由于是计算待处理的目标语音信号的语音幅度谱、谱熵和短时频谱方差来作为目标语音信号对应的多个特征,并对目标语音信号对应的多个特征进行拼接来得到目标语音信号对应的输入特征,使得理想掩码比值模型基于输入特征能够更好地区分人声和噪声,从而能够输出更准确的理想比值掩码,进而能够更准确地滤除噪声,达到更好的降噪效果。
9、结合第一方面,在一种可能的实现方式中,所述理想掩码预测模型包括输入模块、依次连接的至少一个互注意力网络和输出模块,所述输入模块的输出特征为所述至少一个互注意力网络中的第一个互注意力网络的输入特征,所述至少一个互注意力网络中的上一互注意力网络的输出特征为所述至少一个互注意力网络中的下一互注意力网络的输入特征;所述输入模块用于对所述目标语音信号对应的连续多个语音信号帧的输入特征进行特征融合,输出初始特征;所述互注意力网络用于对所述互注意力网络的输入特征进行互注意力打分,并将打分得到的最终打分向量与所述互注意力网络的输入特征进行融合,输出互注意力特征;所述输出模块用于根据所述至少一个互注意力网络中的最后一个互注意力网络输出的互注意力特征,输出理想比值掩码。通过在理想掩码预测模型中引入输入模块和互注意力网络,输入模块能够对多个语音信号帧的输入特征进行关联,互注意力网络考虑了帧与帧之间的相关联系,从而能够输出更准确的理想比值掩码。
10、结合第一方面,在一种可能的实现方式中,所述理想掩码预测模型还包括门控循环单元,所述门控循环单元连接在所述最后一个互注意力网络与所述输出模块之间,所述最后一个互注意力网络的输出特征为所述门控循环单元的输入特征,所述门控循环单元的输出特征为所述输出模块的输入特征;所述门控循环单元用于对所述最后一个互注意力网络输出的互注意力特征进行序列处理,输出序列特征。通过在理想掩码预测模型中引入门控循环单元,能够增强帧与帧之间的长期相关性,从而能够输出更准确的理想比值掩码。
11、结合第一方面,在一种可能的实现方式中,所述输入模块包括第一移位寄存器、第一全连接层、转置层、多头全连接层、打分层和第一输出层;所述第一移位寄存器用于缓存所述目标语音信号对应的连续多个语音信号帧的输入特征;所述第一全连接层用于基于所述目标语音信号对应的连续多个语音信号帧的输入特征,对所述目标语音信号对应的连续多个语音信号帧进行频点关联,输出频点关联特征;所述转置层用于对所述频点关联特征进行转置,输出转置频点关联特征;所述多头全连接层用于对所述转置频点关联特征进行多头全连接,输出多头全连接特征;所述打分层用于对所述多头全连接特征进行相关性打分,输出相关向量;所述第一输出层用于对所述相关向量进行映射,输出所述初始特征。
12、结合第一方面,在一种可能的实现方式中,所述互注意力网络包括多头注意力模块、全连接归一单元、跳跃连接单元;所述多头注意力模块用于对所述互注意力网络的输入特征进行互注意力打分,输出初始打分向量;所述全连接归一单元用于对所述初始打分向量进行全连接拟合归一化,输出所述最终打分向量;所述跳跃连接单元用于对所述互注意力网络的输入特征和所述最终打分向量进行跳跃连接,输出所述互注意力特征。
13、结合第一方面,在一种可能的实现方式中,所述多头注意力模块包括第二全连接层、第三全连接层、第四全连接层、第二移位寄存器、第三移位寄存器、矩阵映射单元和矩阵相乘层;所述第二全连接层、第三全连接层、第四全连接层分别用于对所述互注意力网络的输入特征进行全连接特征提取,输出全连接矢量;所述第二移位寄存器用于缓存所述第三全连接层输出的全连接矢量;所述第三移位寄存器用于缓存所述第四全连接层输出的全连接矢量;所述第一矩阵映射单元用于对所述第二全连接层输出的全连接矢量和所述第二移位寄存器缓存的全连接矢量进行矩阵相乘和映射,输出第一映射向量;所述矩阵相乘层用于对所述第一矩阵映射单元输出的第一映射向量和所述第三移位寄存器缓存的全连接矢量进行矩阵相乘,输出所述初始打分向量。
14、结合第一方面,在一种可能的实现方式中,所述将所述输入特征输入至理想比值掩码预测模型,得到所述理想比值掩码预测模型输出的目标理想比值掩码之前,还包括:获取训练样本集,所述训练样本集包括多个训练样本,每个训练样本包括多个样本信号特征和所述多个样本信号特征对应的样本理想比值掩码,所述多个样本信号特征为样本带噪语音信号对应的多个信号特征;根据所述训练样本集,对所述理想比值掩码预测模型进行训练。
15、结合第一方面,在一种可能的实现方式中,所述获取训练样本集,包括:获取样本纯净语音信号和环境噪声信号;对所述样本纯净语音信号和环境噪声信号进行混合,得到所述样本带噪语音信号;计算所述样本带噪语音信号的语音幅度谱、谱熵和短时频谱方差,得到所述样本带噪语音信号对应的多个样本信号特征;计算样本纯净语音信号的语音幅度谱与所述样本带噪语音信号的语音幅度谱的比值,得到所述多个样本信号特征对应的样本理想比值掩码。
16、第三方面,提供一种计算机设备,包括存储器以及一个或多个处理器,所述存储器连接至所述一个或多个处理器,一个或多个处理器用于执行存储在存储器中的一个或多个计算机程序,一个或多个处理器在执行一个或多个计算机程序时,使得该计算机设备实现上述第一方面的语音处理方法。
17、第四方面,提供一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序包括程序指令,上述程序指令当被处理器执行时使上述处理器执行上述第一方面的语音处理方法。
18、本技术可以实现如下技术效果:由于理想掩码比值为纯净语音幅度谱与带噪语音幅度谱的比值,将目标理想掩码比值与目标语音信号的语音幅度谱相乘,得到目标语音信号对应的纯净语音幅度谱,可实现对语音信号中的噪声的滤除,根据纯净语音幅度谱对应的时域信号得到目标语音信号对应的输出语音信号,实现了对语音信号的降噪处理;另外,由于是计算待处理的目标语音信号的语音幅度谱、谱熵和短时频谱方差来作为目标语音信号对应的多个特征,并对目标语音信号对应的多个特征进行拼接来得到目标语音信号对应的输入特征,使得理想掩码比值模型基于输入特征能够更好地区分人声和噪声,从而能够输出更准确的理想比值掩码,进而能够更准确地滤除噪声,达到更好的降噪效果。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20936.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表