一种中文高保真语音合成音色定制方法与流程
- 国知局
- 2024-06-21 10:38:57
本发明涉及语音合成,特别是涉及一种中文高保真语音合成音色定制方法。
背景技术:
1、语音合成(text to speech,tts)是将语言文字内容转化成语音的过程。而音色定制是在此基础上,根据用户提供的少量录音样本,使合成出来的任意语音都具有该用户的音色特点。与本发明方案最相近的技术是一种被称为语音克隆(voice clone,vc)的技术。目前该技术主要有以下两个难题:1.合成出来的语音存在不自然的停顿现象,韵律欠佳,难以保留原始发音的韵律;2.当用户提供的语音样本时长较短时,由于语料(文字)较少,涵盖的发音信息相应也较少,会给定制的音色带来不利的影响。
技术实现思路
1、本发明目的是针对背景技术中存在的问题,提出一种中文高保真语音合成音色定制方法,通过预训练bert语言模型使合成出来的语音停顿更加符合定制角色的特点,实现高保真的定制效果;针对用户录音语料较少的问题,本发明方案采用动态规划的方法进行最优的语料选取,使用户的录音样本包含更全面的发音信息。
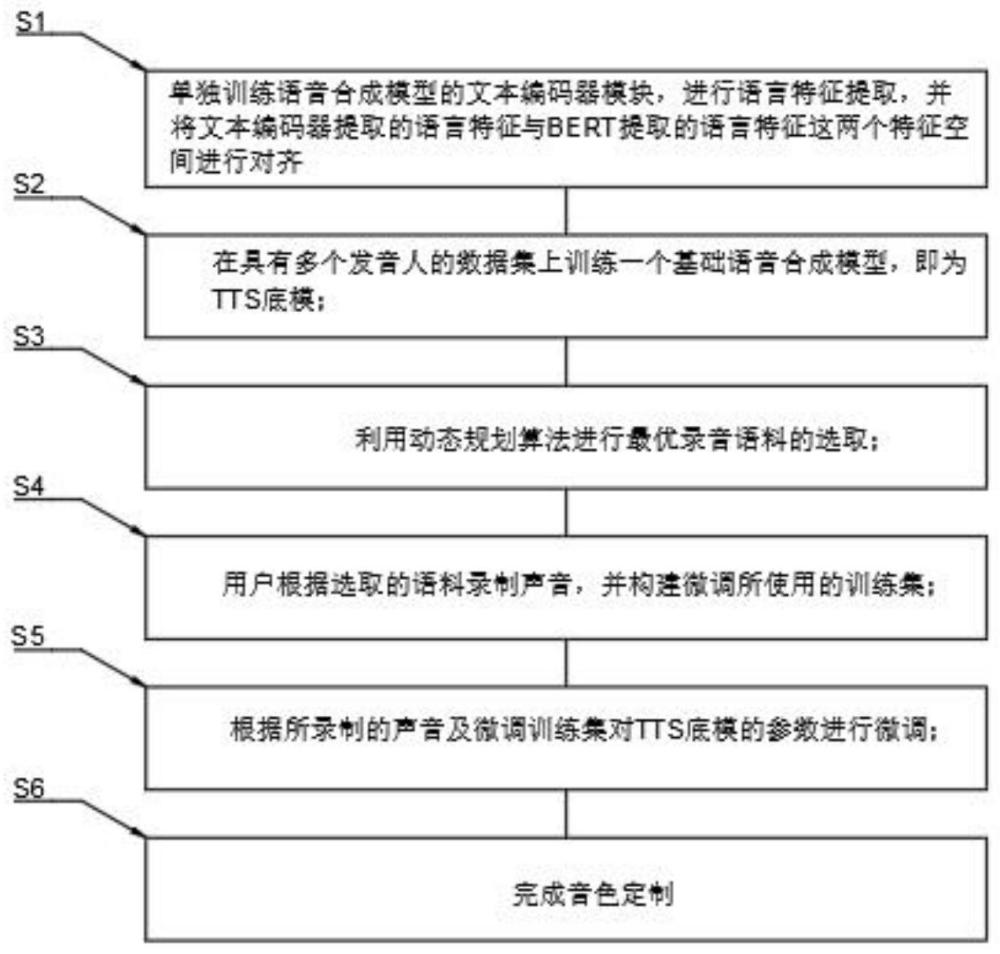
2、本发明的技术方案,一种中文高保真语音合成音色定制方法,包括以下具体步骤:
3、s1、单独训练语音合成模型的文本编码器模块etext,进行语言特征提取,并将文本编码器提取的语言特征与bert提取的语言特征这两个特征空间进行对齐;
4、s2、在具有多个发音人的数据集上训练一个基础语音合成模型,即为tts底模;
5、s3、利用动态规划算法进行最优录音语料的选取;
6、s4、用户根据选取的语料录制声音,并构建微调所使用的训练集;
7、s5、根据所录制的声音及微调训练集对tts底模的参数进行微调;
8、s6、完成音色定制。
9、s1中将文本编码器与bert模型提取的语言特征进行对齐的损失函数为:
10、
11、s2中还包括以下步骤:
12、s21、将输入文本通过预处理得到音素序列;其中音素序列包括汉语的声母,韵母和音调;
13、s22、通过文本编码器得到文本的语言特征vlang;
14、s23、为每个不同的发音人训练一个音色特征向量vid;并根据该特征向量来生成每个音素的时长和文本的发音特征。
15、s23还包括以下步骤:
16、s231、将s22中训练好的文本编码器提取的语言特征vlang与音色特征向量进行拼接,得到音素时长特征zd,通过音素时长预测模块来预测每个音素的发音时长;
17、s232、通过与s231相同的方式,得到梅尔频谱特征zm,并采用梅尔频谱变换模块来预测文本对应的梅尔频谱xm;
18、s233、将预测的梅尔频谱再次与音色特征向量vid拼接后,经过声码器g生成可以通过音频软件播放的声波数据y。
19、通过计算预测的梅尔频谱与真实声音的梅尔频谱之间的差值,得到语音信号的重建损失:
20、
21、通过mas单调对齐搜索算法计算音素的发音时长损失:
22、
23、其中d和分别代表输入文本中每个音素的预测发音时长和通过mas算法计算得到的发音时长。
24、s2采用生成对抗网络的思想,引入梅尔频谱的对抗损失:
25、
26、底模训练的损失函数为以上各项损失之和:
27、
28、文本编码器采用nlp领域中的transformer结构,包含六个注意力层和一个全连接投影层,音素时长预测模块采用一个三层的一维卷积和一个全连接投影层,生成器和鉴别器采用hifi-gan所提出的多周期鉴别器网络结构。
29、s3中利用背包算法选择k个句子的最优句子索引,并得到用于微调音色的语料t′={ti|i∈idxlist}。
30、s4中用户根据指定的语料进行文字朗读,并在每句话之间停顿1秒以上;
31、在收到用户录制好的语音样本,根据预先指定的停顿时间将音频切分为若干条较短的样本,并与语料的每句话相对应,够建微调所使用的训练集。
32、与现有技术相比,本发明具有如下有益的技术效果:
33、1、本发明先单独训练语音合成的文本编码器,将其特征空间与bert进行对齐,然后再训练其它模块,这样模型具有比较好的韵律,且与现有的音色定制技术所采用的预训练的bert语言模型进行文本特征的提取的方式相比,不会降低推理速度。
34、2、本发明采用动态规划的方法进行最优的语料选取,使用户的录音样本包含更全面的发音信息,定制后与原音色相似性较高。
技术特征:1.一种中文高保真语音合成音色定制方法,其特征在于,包括以下具体步骤:
2.根据权利要求1所述的一种中文高保真语音合成音色定制方法,其特征在于,s1中将文本编码器与bert模型提取的语言特征进行对齐的损失函数为:
3.根据权利要求1所述的一种中文高保真语音合成音色定制方法,其特征在于,s2中还包括以下步骤:
4.根据权利要求3所述的一种中文高保真语音合成音色定制方法,其特征在于,s23还包括以下步骤:
5.根据权利要求4所述的一种中文高保真语音合成音色定制方法,其特征在于,通过计算预测的梅尔频谱与真实声音的梅尔频谱之间的差值,得到语音信号的重建损失:
6.根据权利要求5所述的一种中文高保真语音合成音色定制方法,其特征在于,通过mas单调对齐搜索算法计算音素的发音时长损失:
7.根据权利要求6所述的一种中文高保真语音合成音色定制方法,其特征在于,s2采用生成对抗网络的思想,引入梅尔频谱的对抗损失:
8.根据权利要求2所述的一种中文高保真语音合成音色定制方法,其特征在于,文本编码器采用nlp领域中的transformer结构,包含六个注意力层和一个全连接投影层,音素时长预测模块采用一个三层的一维卷积和一个全连接投影层,生成器和鉴别器采用hifi-gan所提出的多周期鉴别器网络结构。
9.根据权利要求1所述的一种中文高保真语音合成音色定制方法,其特征在于,s3中利用背包算法选择k个句子的最优句子索引,并得到用于微调音色的语料t'={ti|i∈idxlist}。
10.根据权利要求1所述的一种中文高保真语音合成音色定制方法,其特征在于,s4中用户根据指定的语料进行文字朗读,并在每句话之间停顿1秒以上;
技术总结本发明涉及语音合成技术领域,特别是涉及一种中文高保真语音合成音色定制方法,包括S1、单独训练语音合成模型的文本编码器模块,并将文本编码器与BERT的特征空间进行对齐;S2、在具有多个发音人的数据集上训练一个基础语音合成模型;S3、利用动态规划算法进行最优录音语料的选取;S4、用户根据选取的语料录制声音,并构建微调所使用的训练集;S5、根据所录制的声音及微调训练集对TTS底模的参数进行微调;S6、完成音色定制。本发明方案采用动态规划进行最优的语料选取,使用户的录音样本包含更全面的发音信息;本发明通过预训练BERT语言模型使合成出来的语音停顿更加自然,通过引入对抗网络,使训练出的音色更加符合定制角色的特点,实现高保真效果。技术研发人员:杨帆,孙宇飞,郝强,潘鑫淼,胡建国受保护的技术使用者:小视科技(江苏)股份有限公司技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/20921.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表