基于语音信号先验概率特性的语音信号增强方法及系统
- 国知局
- 2024-06-21 10:39:17
本发明涉及语音增强领域,特别涉及一种基于语音信号先验概率特性的语音信号增强方法及系统。
背景技术:
1、多通道语音增强通过对传声器阵列采集得到的多路信号进行空间滤波来实现期望语音信号的提取。相比单通道语音增强,多通道语音增强可以同时利用时域频域及空域的信息来实现期望语音的提取,具有更高的降噪性能上限。此外,多通道语音增强方法理论上可以保证处理后的期望语音是无失真的。多通道语音增强在会议系统、助听器和人机交互系统有着重要的作用。
2、多通道语音增强方法常采用的实现手段是波束形成。按照波束形成器的系数是否根据采集数据而自适应的调节,波束形成器可以分为固定波束形成和自适应波束形成。固定波束形成器一般假定噪声场服从一些特定的空间分布形式,然后设计对应噪声场的最优波束形成器。当实际的噪声场满足假定的空间分布形式时,固定波束形成器的效果较好。但是当实际的噪声场不满足假定的分布形式时(而这是实际中常遇到的情况),固定波束形成对于噪声效果的效果变差。相比于固定波束形成器,自适应保护形成器则根据环境中噪声场的变化来自动地调整其系数,理论上可以实现更好的降噪效果。
3、如图1所示,在实际环境下用传声器阵列采集声频信号时,除了会采集到期望说话人的信号,还不可避免地采集到说话人声音的混响信号和噪声信号。自适应波束形成器系统通过对采集的多个通道信号线性滤波来实现期望语音信号的提取。在各类自适应波束形成器中,广义旁瓣消除器因其简单高效的结构而被广泛研究与应用。广义旁瓣消除器(generalized sidelobe canceller,gsc)由固定波束形成器(fixed beamformer,fb),阻塞矩阵(blocking matrix,bm)以及自适应干扰消除器(adaptive interferencecanceller,aic)三个模块构成。其中fb用于产生无失真的期望语音参考,而bm被用于消除期望语音信号,产生噪声参考,aic则用来消除fb输出中的残留噪声。关于fb和bm的精细设计可以部分改善广义旁瓣消除器的性能,但实际实现广义旁瓣消除器时,最重要的步骤是需要对自适应干扰消除器的更新进行有效地控制,才能在语音增强任务中保证系统的稳定性以及语音信号的低失真和低噪音。现有在线实现的更新控制方法往往会存在残留噪声大或者语音信号失真等问题。这些现象出现的主要原因是现有方法设计的相关控制策略未考虑语音信号的一些先验特性,导致广义旁瓣消除器的更新没有得到有效地控制。基于自适应模态控制器(adaptation mode controller,amc)的aic更新方法是一类经典的更新控制机制。该类方法适用于任意阵型的阵列,且对于语音信号的保留程度较好。但是,基于amc的aic更新方法中包含太多需要仔细调节的模块与参数,且实际中其低频处理结果后的残留噪声相对较多。另一类常见的方法则是利用语音存在概率估计(spp,speech presenceprobability)对aic的更新进行控制。但是,基于spp的更新控制方法效果会直接受到spp估计效果的影响,而spp的估计效果在非稳态噪声下往往是会恶化的。此外,还有一些考虑信号独立性的aic更新控制方法,但是这些方法的在线化实现往往需要大量的数据进行相关参数的估计,难以应用于一些实际在线处理的系统中。
技术实现思路
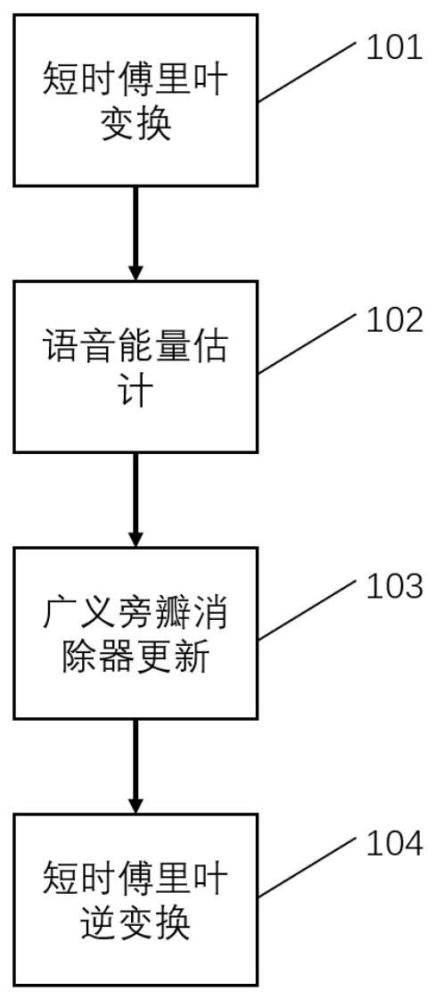
1、本发明的目的在于,克服现有语音增强技术中,广义旁瓣消除器中自适应干扰消除器更新控制较难导致的语音失真或语音噪声残留的问题,从而提供一种基于语音信号先验概率特性的语音信号增强方法及系统,本发明基于语音先验概率特性,利用语音信号能量估计值对广义旁瓣消除器进行更新,克服了广义旁瓣消除器中自适应干扰消除器更新控制较难的问题,提高了广义旁瓣消除器更新的稳健性。为解决上述技术问题,本发明的技术方案所提供的基于语音信号先验概率特性的语音信号增强方法,包括以下步骤:
2、步骤1)对传声器阵列采集的多通道的时域采集信号进行短时傅里叶变换,得到多通道的时频域采集信号;
3、步骤2)利用多通道信息,初步估计语音信号能量,以获得语音信号能量初步估计值;
4、步骤3)基于语音先验概率特性,利用语音信号能量初步估计值对广义旁瓣消除器进行更新;利用更新后的广义旁瓣消除器对多通道的时频域采集信号进行空间滤波,以去除噪音并得到估计的时频域语音信号;利用估计的时频域语音信号二次估计语音信号能量,获得语音信号能量二次估计值,以保证时频域语音信号的鲁棒性;
5、步骤4)对估计的时频域语音信号进行短时傅里叶逆变换,得到估计的时域语音信号。
6、作为上述方法的一种改进,所述步骤1)具体包括:
7、对传声器阵列采集的m个通道的时域采集信号进行短时傅里叶变换,得到m个通道的时频域采集信号;其中,第m通道在时刻n采集的时域采集信号为ym(n),第m通道对应的时频域采集信号为ym(l,k);l为时频域的帧索引,k为时频域的频率索引,且1≤k≤k,1≤l≤l;k为短时傅里叶变换的点数,l为短时傅里叶变换后的帧数。
8、作为上述方法的一种改进,所述步骤2)具体包括:
9、步骤201)计算当前l帧瞬时语音信号能量估计值其中,l为时频域的帧索引,k为时频域的频率索引;
10、步骤202)利用当前l帧瞬时语音信号能量估计值与历史l-1帧语音信号能量估计值初步估计当前l帧的语音信号能量,以获得语音信号能量初步估计值
11、作为上述方法的一种改进,所述步骤201)具体包括:
12、计算当前l帧瞬时语音信号能量估计值
13、
14、其中,l为时频域的帧索引,k为时频域的频率索引;上标h代表共轭转置,为hgsc(l-1,k)的共轭转置,hgsc(l-1,k)为l-1帧的广义旁瓣消除器对应的波束形成器向量;
15、y(l,k)为多通道的时频域采集信号,其中,
16、y(l,k)=[y1(l,k),...,ym(l,k)]t;
17、y1(l,k)为第1个传声器采集的带噪音的时频域信号,ym(l,k)为第m个传声器采集的带噪音的时频域信号,上标t代表向量转置;
18、步骤202)具体包括:利用当前l帧瞬时语音信号能量估计值与历史l-1帧语音信号能量估计值初步估计语音信号能量,以获得的语音信号能量初步估计值
19、
20、其中,α为能量的平滑因子。
21、作为上述方法的一种改进,所述步骤3)具体包括:
22、步骤301)计算当前l帧的阻塞矩阵输出信号的协方差矩阵ψ(l,k):
23、
24、其中,γ是遗忘因子,ψ(l-1,k)是l-1时刻的阻塞矩阵输出信号的协方差矩阵,是语音信号能量初步估计值,u(l,k)是当前l帧的阻塞矩阵的输出信号,上标h为向量转置,uh(l,k)是u(l,k)的向量转置;
25、计算当前l帧的阻塞矩阵输出信号与固定波束形成器滤波后信号的互相关向量p(l,k):
26、
27、其中,p(l-1,k)是l-1帧的阻塞矩阵输出信号与固定波束形成器滤波后信号的互相关向量,是期望信号提取滤波器的输出yd(l,k)的共轭,其中上标*表示共轭操作;
28、u(l,k)=bh(k)y(l,k);
29、bh(k)是广义旁瓣消除器中的阻塞矩阵,y(l,k)是多通道的时频域采集信号;
30、
31、为广义旁瓣消除器中的期望信号提取滤波器;
32、步骤302)当前l帧的阻塞矩阵输出信号的协方差矩阵ψ(l,k)与当前l帧的阻塞矩阵输出信号与固定波束形成器滤波后信号的互相关向量p(l,k),计算广义旁瓣消除器的自适应干扰消除器系数wa(l,k):
33、wa(l,k)=ψ-1(l,k)p(l,k);
34、其中,上标-1代表矩阵的逆,ψ-1(l,k)为当前l帧的阻塞矩阵输出信号的协方差矩阵ψ(l,k)矩阵的逆矩阵;
35、步骤302)利用广义旁瓣消除器的自适应干扰消除器系数wa(l,k)对广义旁瓣消除器的滤波器系数hgsc(l,k)进行更新:
36、hgsc(l,k)=wq(k)-b(k)wa(l,k);
37、其中,hgsc(l,k)表示广义旁瓣消除器的滤波器系数,wq(k)表示广义旁瓣消除器的固定波束形成器系数,b(k)表示广义旁瓣消除器的阻塞矩阵系数,wa(l,k)表示广义旁瓣消除器的自适应干扰消除器系数;
38、步骤303)利用更新后的广义旁瓣消除器对多通道的时频域采集信号进行空间滤波,以去除噪音并得到估计的时频域语音信号
39、
40、其中,上标h代表共轭转置,为广义旁瓣消除器的滤波器系数hgsc(l,k)的共轭转置;
41、步骤304)利用估计的时频域语音信号与历史l-1帧语音信号能量估计值二次估计语音信号能量,获得语音信号能量二次估计值以保证时频域语音信号的鲁棒性;其中,语音信号能量二次估计值为:
42、
43、其中,α为能量的平滑因子。
44、为实现本发明的再一目的,本发明还提供一种基于语音信号先验概率特性的语音信号增强系统,所述系统包括:
45、短时傅里叶变换模块,用于对传声器阵列采集的多通道的时域采集信号进行短时傅里叶变换,得到多通道的时频域采集信号;
46、语音信号能量估计模块,用于初步估计语音信号能量,以获得语音信号能量初步估计值;还用于利用估计的时频域语音信号二次估计语音信号能量,获得语音信号能量二次估计值,以保证时频域语音信号的鲁棒性;
47、广义旁瓣消除器更新模块,基于语音先验概率特性,用于利用语音信号能量初步估计值对广义旁瓣消除器进行更新,使更新后的广义旁瓣消除器对多通道的时频域采集信号进行空间滤波,以去除噪音并得到估计的时频域语音信号;和,
48、短时傅里叶逆变换模块,用于对估计的时频域语音信号进行短时傅里叶逆变换,得到估计的时域语音信号。
49、为实现本发明的再一目的,本发明还提供一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的基于语音信号先验概率特性的语音信号增强方法。
50、为实现本发明的再一目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行以实现所述处理器执行如上所述的基于语音信号先验概率特性的语音信号增强方法。
51、本发明提供的基于语音先验概率特性的稳健广义旁瓣对消方法及装置,包括以下优点:
52、1、本发明方法通过利用语音信号的先验统计概率信息改进了传统算法的代价函数,基于此代价函数的广义旁瓣消除器的更新将更为稳健。
53、2、本发明方法采用的更新方法可以在降噪性能不损失的情况下有效的减缓语音失真问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20963.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表