一种基于上下文线索的语音事件抽取方法
- 国知局
- 2024-06-21 10:39:08
本发明属于计算机自然语言处理领域,具体涉及一种基于上下文线索的语音事件抽取方法。
背景技术:
1、语音在日常对话中是主要的交流方式,例如在会议和采访中广泛使用。直接从语音中提取事件信息是一个重要但研究不足的问题。一种常见的处理方法是通过级联自动语音识别(asr)系统和基于文本的事件抽取系统来执行这一任务。在这个过程中,asr系统将语音转录为文本,然后事件抽取系统从转录的文本中提取事件信息。然而,这种流水线式的方法存在一个问题,即asr系统中的错误可能会传播到下游的事件抽取系统中,从而影响整体性能,这一现象被称为错误传播。
2、与基于文本的事件抽取不同,直接从语音中提取事件信息涉及处理连续的语音信号作为输入。这带来了额外的挑战,原因如下:首先,语音是一种连续信号,没有明确的单词边界,因此识别事件元素变得更加复杂。其次,语音和文本之间存在固有的差异,这使得将语音映射到文本变得更加困难。另外,语义事件通常比声音事件更加复杂。声音事件是可以直接识别的,比如狗叫或门摔,而语义事件涉及对这些声音事件的进一步解释。例如,汽车鸣笛的声音可能表示“交通堵塞”,理解这种语义事件通常需要考虑额外的上下文信息,如时间、空间信息以及相关人员。这些因素使得从语音中直接抽取事件变得更加具有挑战性。
技术实现思路
1、发明目的:为了克服现有技术中存在的不足,提供一种能够高效准确地进行基于语音的事件抽取的方法。通过将语音信号转录为文本作为上下文线索,协调语音和文本之间的信息,以提高事件抽取的质量和整体性能。
2、技术方案:为实现上述目的,本发明提供一种基于上下文线索的语音事件抽取方法,包括以下步骤:
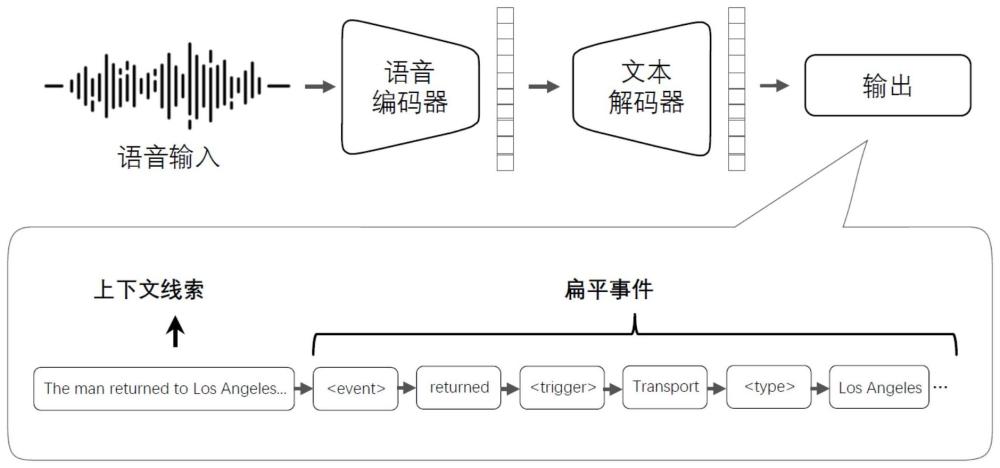
3、s1:构建基于上下文线索的语音事件抽取模型。该模型旨在利用语音信号中的上下文信息,使得事件抽取更为准确和精细。首先,针对语音事件抽取任务,构建一个基于上下文线索的深度神经网络模型。该模型的设计旨在充分利用语音信号中的上下文信息,以实现准确的事件抽取。该模型包括语音编码器和文本解码器两个主要组件,用于实现语音信号到事件标签的映射。
4、s2:实现语音编码器。语音编码器采用深度神经网络,将输入的语音信号转换为高维特征表示。通过捕捉语音信号的时频特性,语音编码器生成适用于后续事件抽取的语音特征。语音编码器采用深度神经网络,其结构包括多层卷积神经网络和位置编码器。卷积神经网络用于从输入的语音信号中提取高维特征表示,这些特征将在后续的事件抽取过程中发挥关键作用。位置编码器用于增强特征的位置信息,以帮助模型理解语音信号的时序特性。
5、s3:实现文本解码器。文本解码器采用注意力机制技术,将语音编码器生成的特征表示映射到文本事件序列。在利用上下文信息的指导下,文本解码器将语音特征逐帧地解码为对应的事件标签,从而实现对语音事件的抽取。文本解码器采用注意力机制技术,将语音编码器生成的高维特征表示映射到文本事件序列。在解码过程中,模型能够根据上下文信息逐帧地将语音特征解码为对应的事件标签。注意力机制允许模型根据输入的不同部分分配不同的注意力权重,从而更好地捕捉语音和文本之间的关联关系。
6、s4:训练语音事件抽取模型。在训练阶段,使用带有标注的语音数据,通过最小化负对数似然损失函数来优化语音事件抽取模型的参数。训练过程使模型能够准确地预测每一帧语音对应的事件标签。在训练阶段,使用带有标注的语音数据对模型进行训练。通过最小化负对数似然损失函数,优化语音事件抽取模型的参数,使其能够准确地预测每一帧语音对应的事件标签。训练数据包括语音信号以及其对应的事件标签,以及用于模型优化的相关参数
7、s5:测试语音事件抽取模型。在推理阶段,将待抽取事件的语音信号输入已训练好的模型,经过特征提取和解码,预测每一帧语音对应的事件标签,实现对输入语音事件的抽取。
8、作为本发明的一种改进,所述步骤s1中面向语音的事件抽取任务具体为:
9、考虑到由三个子集构成的数据集d,这些子集包括训练集dtrn、验证集dval以及测试集dtest。在这个数据集中,每个实例被表示为一个元组{(xi,yi)},其中第i个实例由包含来自语音的m个数字信号序列的输入xi∈rm组成,并包含了输出标记序列yi=(t1,w1,…,tj,wj,…,tn,wn)。
10、其中,tj代表了特殊标记,用于表示事件元素,比如“事件类型”或“角色”,而wj则表示从语音中提取出的各种内容,包括触发词和论元。
11、作为本发明的一种改进,所述步骤s1中基于上下文线索的语音事件抽取模型具体为:由一个语音编码器和一个文本解码器组成,转录文本被用作上下文线索来指导事件生成。在条件生成的激励下,利用automaticspeechrecognition(asr)输出作为后续文本解码器的上下文线索。
12、作为本发明的一种改进,所述步骤s2中语音编码器具体为:
13、首先,对于语音输入x,特征提取模块执行初始下采样操作,其中x表示为80通道对数幅度梅尔谱图的表征形式。这些表示经过两个卷积层的处理,每一层都使用宽度为3的滤波器,并应用gelu激活函数以进行非线性映射。同时,为了加强位置信息的表示,将正弦位置嵌入结合到生成的特征表示中,形成表示向量f=[f1,f2,…,fx]。
14、接着,通过多层transformer编码器计算上下文表示向量h=encoder(f1,f2,…,fx)。这个编码器由多个transformer块组成,每个块包括两个主要组件,即自我注意力层和前馈神经网络。这些组件协同工作,有助于捕捉输入数据的上下文信息和特征表示,以生成上下文表示。
15、作为本发明的一种改进,所述步骤s3中文本解码器具体为:
16、解码器使用自回归方式逐个生成目标文本中的单词。在这个生成过程中,每个单词的产生都受到前面已生成的单词以及输入语音的编码表示的影响。具体来说,生成过程可以表示为
17、其中,decoder(·)的每一层都包含自注意力机制,用于处理解码器当前状态并且还包含交叉注意力机制,用于考虑编码器状态h。这些注意力机制有助于解码器根据先前生成的内容和语音编码信息来选择下一个要生成的单词。
18、作为本发明的一种改进,所述步骤s4中最小化负对数似然损失函数具体为:
19、
20、其中d是训练集,θ*表示最佳参数,x是输入语音,y是生成的转录文本与预测事件结构的序列。
21、作为本发明的一种改进,所述步骤s4中似然函数具体为:
22、
23、其中pθ(y|x)定义为pθ(yt|y<t,x)的累积,yt是输出序列y中的第t个标记。
24、作为本发明的一种改进,所述步骤s4中训练过程包括以下步骤:
25、4-1:数据预处理,所述数据预处理包括语音信号的特征提取、事件标签的转换等,用于为模型训练提供合适的输入;
26、4-2:模型初始化,所述模型初始化阶段对语音编码器和文本解码器进行初始化设置,为后续训练做准备。
27、4-3:迭代训练,所述迭代训练阶段通过多轮迭代,使用训练数据对模型进行训练,不断优化模型参数,提高语音事件抽取的准确性和鲁棒性。
28、作为本发明的一种改进,所述步骤s5中推理过程包括以下步骤:
29、5-1:语音输入,所述语音输入为待抽取事件的语音信号。
30、5-2:特征提取,所述特征提取阶段对所述语音输入进行预处理,提取语音特征表示。
31、5-3:事件抽取,所述事件抽取阶段利用经过训练的语音事件抽取模型,对特征表示进行解码,预测语音对应的事件标签,从而实现对输入语音事件的抽取。
32、作为本发明的一种改进,所述模型在语音编码器和文本解码器之间采用注意力机制进行信息传递,以提高语音事件抽取的效果和准确性。
33、有益效果:本发明与现有技术相比,将语音识别转录文本作为上下文线索引入到语音事件抽取模型中,有效缩小了文本和语音模态的差距。该方法在中英文数据集上带来了显著的改进,实现了10.7%的最大f1增益。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20938.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。