一种基于房间冲激响应估计模型的回声消除方法
- 国知局
- 2024-06-21 10:39:29
本发明涉及声学信号处理,具体是涉及一种基于房间冲激响应估计模型的回声消除方法。
背景技术:
1、在视频会议、语音通话等远程通信环境下,可以普遍地将两方的通话人分为远端语音和近端语音。远端麦克风接收远端语音并传输至近端扬声器,并经过扬声器散播在空间当中,形成带混响的回声,这个过程可以视为远端语音与房间冲激响应卷积,形成混响回声(近端回声由于经过房间反射得到,因此后文中混响回声和回声同义)。此时可分为三种情况,两方均不说话,此时无语音信号在系统中传输,因此没有回声;只有远端说话人说话,此时远端说话人会接收到远端说话人自己发出语音的回声;若两方通话人同时说话,近端麦克风接收到的语音相当于远端语音的混响回声叠加了近端说话人的语音,从而使得近端说话人的语音混杂了回声,难以理解具体说的话,影响通话质量。后两种情况需要应用声学回声消除方法。
2、目前常使用的方法有传统信号处理方法和深度学习方法。信号处理方法包括最小均方算法、归一化最小均方算法、频域自适应滤波器;深度学习方法则是构建网络来预测回声路径音频从而进行回声消除。
3、传统信号处理方法的劣势在于,在使用前需要使用一段音频进行预处理,相当于需要一段时间的“预热”,使得算法能够收敛,然后才能进行回声消除,且近端环境的变化会使得算法需要重新“预热”,对回声消除的效果有影响。因此,近来研究者们在使用深度学习的方法进行回声消除上进行了深入的研究。本发明属于基于深度学习进行回声消除方法,但相比于其他直接使用深度学习模型估计回声路径的方法,本发明所提出的基于房间冲激响应估计模型的回声消除方法,不直接估计回声路径,而估计帮助形成回声的房间冲激响应,因此具有更强的可解释性和广泛的适应性。
技术实现思路
1、本发明所要解决的技术问题是,提供一种新型的基于房间冲激响应估计模型的回声消除方法,通过直接估计房间冲激响应,从而估计出现的回声路径,从而实现回声消除,具有更强的可解释性和广泛的适用范围。
2、本发明解决其技术问题采用的技术方案是:一种基于房间冲激响应估计模型的回声消除方法,包括以下步骤:
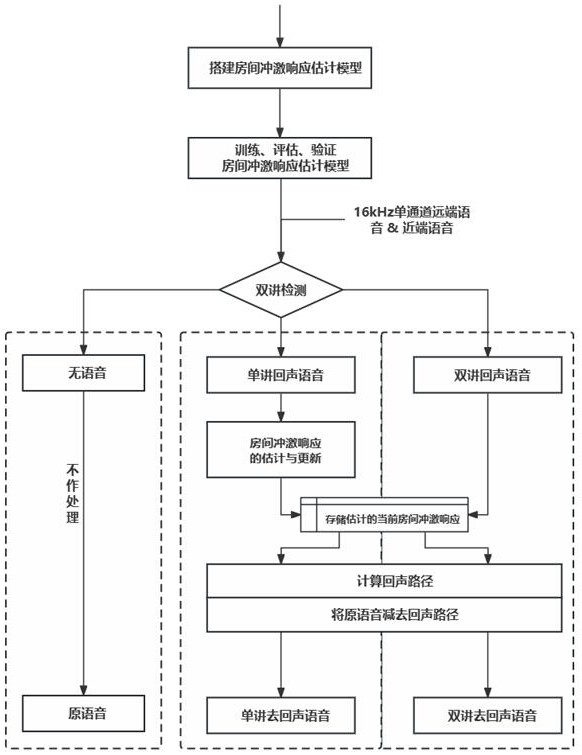
3、步骤s1. 搭建房间冲激响应估计模型;
4、步骤s2. 训练、评估、验证房间冲激响应估计模型;
5、步骤s3. 双讲检测;
6、步骤s4. 根据检测结果可以得出无语音、单讲回声语音、双讲回声语音,根据不同的路径对其进行回声消除。
7、进一步,步骤s1中,搭建房间冲激响应估计模型的过程如下:
8、步骤s1-1. 数据集的收集和合成,所需数据集为清晰语音数据集(timit)和冲激响应数据集(air数据集、ace数据集),用以合成混响语音数据集,所需清晰语音数据集和冲激响应数据集的来源为互联网开源数据集;
9、步骤s1-2. 搭建模型,模型包括编码器层和解码器层;
10、编码器层包括两层残差卷积层,每层残差卷积层是由一层二维卷积层、一层批归一化层、一层relu激活层、一层二维卷积层、一层批归一化层、一层relu激活层组成,之后接一层平均池化层和一层全连接层;全连接层,将特征输出,最终提取出的特征能表征房间冲激响应所需的基本参数,以便合成房间冲激响应;
11、解码器层包括一层一维反卷积层,一层批归一化层,一层relu激活层,接着一层一维反卷积层,最后连接全连接层,将其映射成完整的波形。
12、进一步,步骤s2中,训练、评估、验证房间冲激响应估计模型的过程如下:
13、步骤s2-1. 训练所采用的损失函数采用sdr损失函数,计算方式为计算真实冲激响应减去预测冲激响应的l2归一化值,接着除以真实冲激响应的l2归一化值,单位为db;
14、步骤s2-2. 模型的评估方法采用均方根误差进行评判,通过计算实际的房间冲激响应与预测的房间冲激响应之间的距离从而可以得出预测的准确性,从而判断模型的效果;
15、步骤s2-3. 应用过程中,所能拿到的语音只有清晰的远端语音以及带回声的近端语音,而其房间冲激响应未知,所做的就是估计房间冲激响应,因此模拟应用场景,使用少量真实的数据集,包括带回声的近端语音以及对应的真实已知的房间冲激响应,将带回声的近端语音投入模型,获得估计的房间冲激响应,并和对应的真实房间冲激响应比较,验证其基本的有效性,肉眼观察,若波形较为相似,即可认为基本有效;
16、步骤s2-4. 经过训练、评估、验证后的模型具有相当的预测准确度,允许的均方根误差的偏差范围需要小于0.01,用于保障后续的回声消除的效果。
17、进一步,步骤s3中,双讲检测的过程如下:
18、使用能量检测的方式,判断远端语音、近端语音是否有语音存在,计算远端语音、近端语音的平均能量,若大于阈值te,则说明该端语音存在,此时能判断是否存在语音,但无法判断单讲还是双讲,因为在远端单讲的情况下,近端存在回声,会导致系统认为近端存在语音,从而将单讲发生误判,此时使用回声回波增强(erle)进行判断,计算方式为使用远端信号的能量比近端信号的能量,当远端单讲时,回声回波增强(erle)会比较大,而双讲时,回声回波增强(erle)会较小,此时设置阈值terle,当大于该阈值时判断为单讲,当小于等于该阈值时判断为双讲。
19、进一步,步骤s4中,根据检测结果可以得出无语音、单讲回声语音、双讲回声语音,根据不同的路径对其进行回声消除;
20、步骤s4-1. 若无语音在系统中传输,显然不需要进行回声消除,因此直接返回;
21、步骤s4-2. 若当前语音为单讲回声语音,则近端语音只包含远端语音的混响回声,这段语音可以通过房间冲激响应估计模型估计当前的房间冲激响应,当近端扬声器和房间布置固定时,此时房间冲激响应有且只有一份;为了保证系统存有且只有一份当前环境的房间冲激响应,若是第一次进行房间冲激响应估计,则内部直接存储估计出的房间冲激响应;若系统内部已存储有当前环境的房间冲激响应,则将重新估计的房间冲激响应并与上一份估计的房间冲激响应进行平均,从而更新系统存有的冲激响应,这是为了保障变化的平滑,获得当前的房间冲激响应后,将清晰的远端语音与房间冲激响应进行卷积,所得语音为估计的回声路径,将带回声的近端语音减去这部分回声路径,得到单讲去回声的音频,完成回声消除;
22、步骤s4-3. 若当前语音为双讲回声语音,此时近端回声语音包含有回声和近端说话人的语音,由于存在两个声源,而所提出的模型只能用于单声源的房间冲激响应估计,因此在这种情景下,不进行冲激响应的估计与更新,直接利用单讲中所估计的房间冲激响应,进行去回声操作,此方法的可行性在于,在不改变扬声器与房间布置的情况下,房间冲激响应在单讲和双讲中应是保持不变的,且在语音视频通话中,单讲总是占据了绝大多数时间,一般是一个人说话一个人听,因此能保障总是存单讲中估计出来的房间冲激响应,最后,通过将远端语音与冲激响应进行卷积,所得语音为估计的回声路径,将近端带回声的语音减去这部分回声路径,得到双讲去回声的音频。
23、与现有技术相比,本发明的优点如下:
24、(1)相比于传统回声消除,本方法不需要“预热”的动作,当接收到单讲、双讲时,能够直接通过本方法进行回声消除,并且具有一致的性能;本方法不依赖于环境和信号,相关回声消除的性能依赖于冲激响应估计模型的性能;
25、(2)相比于其他使用深度学习网络进行回声消除的方法,优势在于:其一,通过估计房间冲激响应进行回声消除,能够完整的估计回声路径,具有更好的可解释性;其二,通过估计房间冲激响应,能够获得更多的房间的声学信息,帮助判断算法调用的情景,例如在房间混响较小的情况下,回声非常微弱,此时可以不调用算法,节约计算资源。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20996.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表