一种基于异构多专家的单通道语音增强方法及系统
- 国知局
- 2024-06-21 10:41:47
本发明属于语音信号降噪领域,具体是一种基于异构多专家的单通道语音增强方法及系统。
背景技术:
1、随着信息技术和通讯领域的快速发展,语音成为人们日常交流和机器交互的主要方式。在此背景下,语音增强技术逐渐显露出其在语音研究领域中的至关重要地位。语音,作为人类最重要的交流工具,其清晰度和质量对于保障交流的效果至关重要。不幸的是,实际应用中的语音经常受到各种环境噪声的干扰,这大大降低了语音的质量和可懂度。
2、在不同的实际应用场景中,如自动语音识别(asr)、远程会议、助听器以及其他与语音相关的应用,噪声都成为了一个棘手的问题。为了解决这一问题,研究者们开发了多种语音增强技术,其核心目标都是在保留语音信息的同时,最大限度地抑制背景噪声。
3、早期的语音增强方法多基于数字信号处理技术,例如频谱减法和各种滤波技术。在频谱减法中,靠着静态加性噪声模型从噪声语音频谱中减去估计的噪声部分,期望得到清晰的语音信号。滤波技术,如维纳滤波,也被广泛应用于语音降噪中。
4、随着深度学习技术的崛起,基于深度学习的语音增强方法逐渐赢得了研究者的关注,并逐步取代传统方法,成为当前的研究热点。这些基于深度学习的方法旨在模拟复杂的语音和噪声关系,并优化模型来实现更好的降噪效果。
5、然而,尽管已有的深度学习方法取得了不错的效果,但它们仍然面临着一些挑战。传统的语音增强方法,无论是基于传统数字信号处理技术还是基于深度学习的技术,都往往采取一种“一刀切”的策略,即使用单一的模型来处理各种噪声。显然,这种方法在处理多种噪声场景时可能会遭遇瓶颈。已有的混合专家网络虽然试图解决这一问题,但由于多数专家网络结构和处理策略过于相似,模型间缺乏多样性,使得其在某些特定噪声环境下的效果并不理想。
6、综上所述,随着语音增强技术的持续发展和深入研究,针对多种噪声环境,寻找一种更为灵活、更具多样性的语音增强方法显得尤为迫切。
技术实现思路
1、针对现有技术存在的不足,本发明目的是提供一种基于异构多专家的单通道语音增强方法及系统。
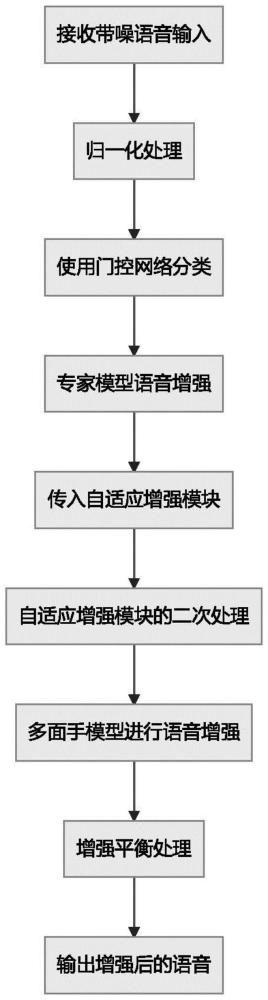
2、作为本公开实施例的一个方面,本公开实施例提供一种基于异构多专家的单通道语音增强方法,包括以下步骤:
3、a.接收带噪语音输入;
4、b.对所述带噪语音进行归一化处理;
5、c.使用门控网络对归一化后的所述带噪语音进行分类,确定最适合的专家模型;
6、d.根据所述门控网络的分类结果,将所述带噪语音的复谱传递给所确定的所述专家模型进行语音增强;
7、e.将所述带噪语音复谱和所述专家模型语音增强的结果一同传入自适应增强模块中;
8、f.使用所述自适应增强模块对所述专家模型增强后的语音进行二次处理,以补充由于所述专家模型选择错误而遗失的增强信息;
9、g.在所述自适应增强模块中,所述带噪语音的复谱传递给多面手模型进行语音增强,将所述多面手模型得到的增强结果和所述专家模型得到的增强结果分别乘以增强平衡矩阵,然后相加得到最终增强结果;
10、h.输出所述最终增强结果后的语音。
11、进一步地,所述门控网络的结构包括注意力层、长短记忆时网络和概率分布转化层,能够根据输入所述带噪语音的复杂频谱特征进行分类,并输出不同类别的概率向量,以指导选择所述专家模型。
12、进一步地,所述专家模型包括至少两种不同的深度神经网络结构,每种所述深度神经网络结构都经过优化,以处理特定类型的噪声或信噪比范围。
13、进一步地,包括两种结构的专家模型,即基于卷积注意力的生成对抗网络的cmgan网络结构和双路注意力机制网络的dbaiat网络结构;其中,使用男性说话人带噪语音训练的所述cmgan网络结构得到cmgan男性专家模型,用于处理高信噪比的男性带噪语音,使用女性说话人带噪语音训练的所述cmgan网络结构得到cmgan女性专家模型,用于处理高信噪比的女性带噪语音;使用男性说话人带噪语音训练的所述dbaiat网络结构得到dbaiat男性专家模型,用于处理低信噪比的男性带噪语音,使用女性说话人带噪语音训练的所述dbaiat网络结构得到dbaiat女性专家模型,用于处理低信噪比的女性带噪语音。
14、进一步地,所述自适应增强模块至少包括一个多面手模型,所述多面手模型使用完整的训练数据集,包括男性与女性说话语音去训练单个模型,并使用所述增强平衡矩阵对增强的语音通过权重来调整在最后的结果中所占比例,以实现更高的增强效果。
15、进一步地,所述增强平衡矩阵是一个可学习可训练且可以利用反向传播算法更新参数的权重矩阵,用于动态调整所述多面手模型和所述专家模型之间的输出权重,当所述门控网络分类错误的时候,则需要调大所述多面手模型的输出所占的比重。
16、进一步地,所述步骤进一步还包括将所述带噪语音分段并随机选取所述带噪语音中连续的一秒作为最小训练单位,并对每个片段进行归一化处理。
17、一种基于异构多专家的单通道语音增强系统,包括:
18、一个输入模块,用于接收和预处理带噪语音;
19、一个门控网络,包含注意力层、长短记忆时网络和概率分布转化层,用于对预处理后的所述带噪语音进行分类;
20、若干个专家模型,每个所述专家模型都具有不同的深度神经网络结构,并针对特定类型的噪声或信噪比范围进行优化;
21、一个自适应增强模块,包括多面手模型和增强平衡矩阵,用于对由所述专家模型增强后的语音进行二次处理;
22、一个输出模块,用于输出所述最终增强结果后的语音。
23、进一步地,还包括数据预处理模块,所述数据预处理模块进一步包括分段器和归一化器,用于将所述带噪语音通过随机选取其中连续的1秒将其进行分段,并对每个片段进行归一化限定在0到1范围内的处理。
24、进一步地,每个所述专家模型进一步包括编码以及解码器,并且所述编码器和所述解码器都由密集连接扩张卷积块构成,所述编码器用于通过卷积操作对所述带噪语音进行特征提取,所述解码器用于通过上采样卷积对提取的特征还原成增强后的语音。
25、与现有技术相比,本申请实施例提供的一种基于异构多专家的单通道语音增强方法及系统,通过利用多种深度神经网络结构为每种噪声环境或信噪比条件提供专门的处理,从而实现更高效、更多样的语音增强效果。这不仅提高了对不同噪声类型的处理能力,还通过自适应增强模块克服了传统门控网络中的潜在分类错误,确保了更高的增强性能和系统稳定性。
技术特征:1.一种基于异构多专家的单通道语音增强方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,所述门控网络的结构包括注意力层、长短记忆时网络和概率分布转化层,能够根据输入所述带噪语音的复杂频谱特征进行分类,并输出不同类别的概率向量,以指导选择所述专家模型。
3.根据权利要求1所述的方法,其特征在于,所述专家模型包括至少两种不同的深度神经网络结构,每种所述深度神经网络结构都经过优化,以处理特定类型的噪声或信噪比范围。
4.根据权利要求3所述的方法,其特征在于,包括两种结构的专家模型,即基于卷积注意力的生成对抗网络的cmgan网络结构和双路注意力机制网络的dbaiat网络结构;其中,使用男性说话人带噪语音训练的所述cmgan网络结构得到cmgan男性专家模型,用于处理高信噪比的男性带噪语音,使用女性说话人带噪语音训练的所述cmgan网络结构得到cmgan女性专家模型,用于处理高信噪比的女性带噪语音;使用男性说话人带噪语音训练的所述dbaiat网络结构得到dbaiat男性专家模型,用于处理低信噪比的男性带噪语音,使用女性说话人带噪语音训练的所述dbaiat网络结构得到dbaiat女性专家模型,用于处理低信噪比的女性带噪语音。
5.根据权利要求1所述的方法,其特征在于,所述自适应增强模块至少包括一个多面手模型,所述多面手模型使用完整的训练数据集,包括男性与女性说话语音去训练单个模型,并使用所述增强平衡矩阵对增强的语音通过权重来调整在最后的结果中所占比例,以实现更高的增强效果。
6.根据权利要求5所述的方法,其特征在于,所述增强平衡矩阵是一个可学习可训练且可以利用反向传播算法更新参数的权重矩阵,用于动态调整所述多面手模型和所述专家模型之间的输出权重,当所述门控网络分类错误的时候,则需要调大所述多面手模型的输出所占的比重。
7.根据权利要求1所述的方法,其特征在于,所述步骤进一步还包括将所述带噪语音分段并随机选取所述带噪语音中连续的一秒作为最小训练单位,并对每个片段进行归一化处理。
8.一种基于异构多专家的单通道语音增强系统,其实现如权利要求1至7任意一项所述的基于异构多专家的单通道语音增强方法,其特征在于,包括:
9.根据权利要求8所述的系统,其特征在于,还包括数据预处理模块,所述数据预处理模块进一步包括分段器和归一化器,用于将所述带噪语音通过随机选取其中连续的1秒将其进行分段,并对每个片段进行归一化限定在0到1范围内的处理。
10.根据权利要求9所述的系统,其特征在于,每个所述专家模型进一步包括编码以及解码器,并且所述编码器和所述解码器都由密集连接扩张卷积块构成,所述编码器用于通过卷积操作对所述带噪语音进行特征提取,所述解码器用于通过上采样卷积对提取的特征还原成增强后的语音。
技术总结本发明公开了一种基于异构多专家的单通道语音增强方法及系统,包括一个输入模块,用于接收和预处理带噪语音;一个门控网络;若干个专家模型,每个模型都具有不同的深度神经网络结构,并针对特定类型的噪声或信噪比范围进行优化;一个自适应增强模块;一个输出模块。本发明通过利用多种深度神经网络结构为每种噪声环境或信噪比条件提供专门的处理,从而实现更高效、更多样的语音增强效果。这不仅提高了对不同噪声类型的处理能力,还通过自适应增强模块克服了传统门控网络中的潜在分类错误,确保了更高的增强性能和系统稳定性。技术研发人员:王俊松,丁淳,靳小鹏受保护的技术使用者:深圳技术大学技术研发日:技术公布日:2024/2/1本文地址:https://www.jishuxx.com/zhuanli/20240618/21270.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表