一种虚拟数字人的交互方法及系统与流程
- 国知局
- 2024-06-21 10:41:54
本发明涉及交互领域,尤其涉及一种虚拟数字人的交互方法及系统。
背景技术:
1、虚拟数字人技术在交互领域的应用越来越广泛,可以帮助交互系统及时、高效地分析指令,实现文本的分析和对话。目前,指令信息量庞大、种类多样、信息密度大等特点,交互方法存在较多的不确定因素,导致交互方法存在较大的不确定性。虽然已经发明了一些虚拟数字人的交互方法与系统,但是仍不能有效解决交互方法的不确定问题。
技术实现思路
1、本发明的目的是要提供一种虚拟数字人的交互方法。
2、为达到上述目的,本发明是按照以下技术方案实施的:
3、本发明包括以下步骤:
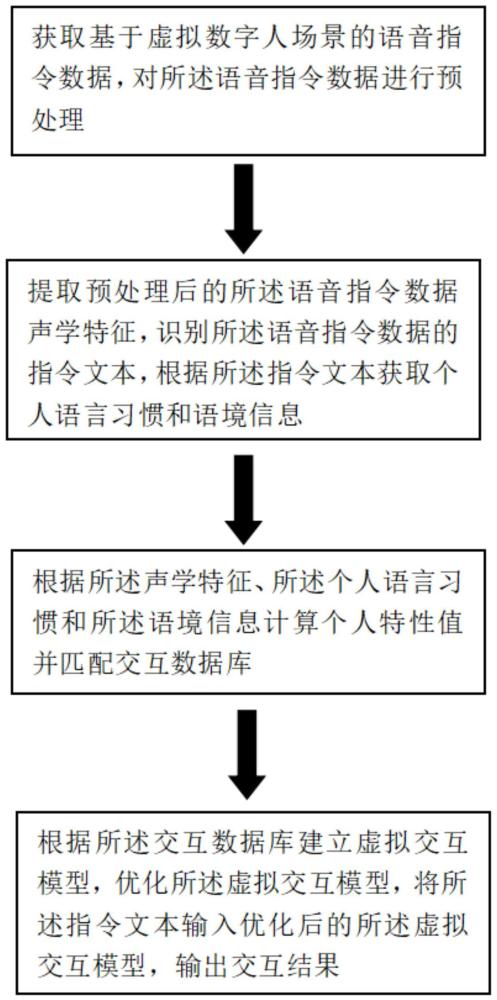
4、a获取基于虚拟数字人场景的语音指令数据,对所述语音指令数据进行预处理;
5、b提取预处理后的所述语音指令数据声学特征,识别所述语音指令数据的指令文本,根据所述指令文本获取个人语言习惯和语境信息;
6、c根据所述声学特征、所述个人语言习惯和所述语境信息计算个人特性值并匹配交互数据库,所述个人特征值表征所述声学特征、所述个人语言习惯、所述语境信息与所述历史数据库的匹配程度;
7、根据所述声学特征、所述个人语言习惯和所述语境信息计算个人特性值并匹配交互数据库的方法,包括:
8、计算个人特性值:
9、
10、其中第e个交互数据库数据的特性集合为ae,指令文本的声学特征集合为b,声学特征的权重为ω1,指令文本的个人语言习惯集合为c,个人习惯的权重为ω2,指令文本的语境信息集合为d,语境信息的权重为ω3,特性集合ae的数值为|ae|,指令文本的数值大小为|ω1b+ω2c+ω3d|,交互匹配因子为ρ;
11、当个人特性值小于0.5时,指令文本与交互数据库数据不匹配,更换交互数据库数据,直到个人特性值大于等于0.5,将第e个交互数据库数据与指令文本关联;
12、当个人特征值大于等于0.5时,将第e个交互数据库数据与指令文本关联;
13、更换指令文本匹配交互数据库数据,直到遍历完所有的指令文本;
14、d根据所述交互数据库建立虚拟交互模型,优化所述虚拟交互模型,将所述指令文本输入优化后的所述虚拟交互模型,输出交互结果。
15、进一步的,步骤a中所述预处理包括预加重、分帧、加窗、端点检测和去噪。
16、进一步的,提取预处理后的所述语音指令数据声学特征的方法,包括:
17、对预处理后的所述语音指令数据进行傅里叶变换,将语音指令数据转换到频域,计算功率谱密度:
18、
19、其中第v帧第t个序列的功率谱密度为g(v,t),每帧长度为m,第v帧第t个序列的频域表示为h(v,t),傅里叶变换的点数为t,给定滤波器的频率响应:
20、
21、其中第i个滤波器中心频率为h(i),第i个滤波器第v帧的频率响应为wi(v),将功率谱密度利用三角滤波器组映射到梅尔频率尺度上,计算梅尔频率功率谱密度:
22、
23、其中三角滤波器的数量为i,第i个滤波器第v帧的梅尔频率功率谱密度为qv(v,i),对梅尔频率功率谱密度进行离散余弦变换,得到梅尔频率倒谱系数,梅尔频率倒谱系数的计算公式为:
24、
25、其中梅尔频率倒谱系数的维数为j,第v帧第j维的梅尔频率倒谱系数为e(v,j),计算梅尔频率倒谱系数的一阶差分:
26、
27、其中差分计算的帧数范围为l,第v+1帧第j维的梅尔频率倒谱系数函数为ej(v+1),第v-1帧第j维的梅尔频率倒谱系数函数为ej(v-1),第j维第v帧的梅尔频率倒谱系数一阶差分为δej(v),计算梅尔频率倒谱系数的二阶差分:
28、
29、其中第j维第v帧的梅尔频率倒谱系数二阶差分为δδej(v),第j维第v-1帧的梅尔频率倒谱系数一阶差分为δej(v-1),梅尔频率倒谱系数特征为静态特征,梅尔频率倒谱系数的一阶差分、梅尔频率倒谱系数的二阶差分特征为动态特征,输出声学特征。
30、进一步的,根据所述指令文本获取个人语言习惯的方法,包括:
31、将所述指令文本构造成指令文本数据库,计算数据库中事务项的支持度:
32、
33、其中总事务项的数量为n,包含特定项m的事务数为cm,事务项m的支持度为sm,对指令文本数据库中所有的项进行支持度统计,将支持度低于阈值的项从语音指令数据中删除,得到长度为1的前缀;
34、找出前缀所对应的投影数据库,如果语音指令数据为空,则递归返回;
35、统计对应投影数据库中各项的支持度计数,如果所有项的支持度计数都低于阈值,则递归返回;
36、将满足支持度计数单项和当前的前缀进行合并,得到新的前缀;
37、令长度加一,前缀为合并单项后的前缀,分别递归,返回判断各项支持度计数是否低于阈值;
38、重复对长度满足支持度要求的前缀进行递归挖掘,直到挖掘不出新的前缀为止,将前缀输出为个人语言习惯。
39、进一步的,获取所述语境信息的方法,包括:
40、将指令文本分为主语、谓语、宾语、定语、状语、补语六个成分;以词或词组作为划分成分的基本单位;
41、根据六个成分的搭配排列按层次顺序确定指令文本的格局,根据指令文本的格局理解指令文本的语义,将指令文本的语义输出为语境信息。
42、进一步的,根据所述交互数据库建立虚拟交互模型的方法,包括
43、所述虚拟交互模型包括文本预处理分部、自然语言理解分部、对话管理分部和自然语言分部,将指令文本输入文本预处理分部获取预处理文本,将预处理文本输入自然语言理解分部获得理解信息,将理解信息输入对话管理分部获得初始交互文本,将初始交互文本输入自然语言分部输出交互结果;
44、文本预处理分部用于对指令文本进行分词、去停用词、命名实体识别、词义消歧、大小写转换和文本转换;
45、自然语言理解分部用于对预处理文本进行语义解析,识别出文本的实体和意图,并将语义解析转化为机器语言;
46、对话管理分部用于根据理解信息的状态和用户生成系统响应,决策下一步行动,更新对话的状态;
47、自然语言分部用于将初始交互文本转化为人类可读文本。
48、进一步的,根据所述交互数据库优化所述虚拟交互模型的方法,包括:
49、将所述交互数据库按照8:2随机划分成训练数据集和测试数据集;
50、令隐含层节点为一,随机给定交互超参数向量集,初始化参数,将训练数据集分组进行滚动验证;
51、选取训练数据集分组作为训练数据获得循环神经网络的初始权重;
52、给定非线性约束二次函数优化表达式:
53、
54、其中输入变量与第l个隐含层节点上一时刻对第j个节点当前时刻的循环权重为γlj,第n个交互结果为xn,隐含层与输出层的偏置为z0,输入与第j个隐含层的偏置为zj,激活函数为f(·)和w(·),时延步长为β,隐含层节点数量为p,候选输入变量i的数量为q,隐含层的数量为t,时刻为m,交互参数为θ,第i个候选输入变量为ai,第i个压缩参数为si,第b个压缩参数为sb,m时刻的隐含层的状态为ym(·),第i个变量第j个隐含层的输入权重为eij,第j个隐含层节点与输出之间的权重为uj;
55、求解非线性约束二次函数优化表达式得到压缩系数,更新网络权重,更新网络权重的计算公式为:
56、e′ij=sieij
57、s′b=sbγlj
58、其中更新的输入权重为e′ij,更新的循环权重s′b。
59、第二方面,一种数字虚拟人的交互系统,包括:
60、预处理模块:获取基于虚拟数字人场景的语音指令数据,对所述语音指令数据进行预处理;
61、提取模块:提取预处理后的所述语音指令数据声学特征,识别所述语音指令数据的指令文本,根据所述指令文本获取个人语言习惯和语境信息;
62、数据库匹配模块:根据所述声学特征、所述个人语言习惯和所述语境信息计算个人特性值并匹配交互数据库,所述个人特征值表征所述声学特征、所述个人语言习惯、所述语境信息与所述历史数据库的匹配程度;
63、根据所述声学特征、所述个人语言习惯和所述语境信息计算个人特性值并匹配交互数据库的方法,包括:
64、计算个人特性值:
65、
66、其中第e个交互数据库数据的特性集合为ae,指令文本的声学特征集合为b,声学特征的权重为ω1,指令文本的个人语言习惯集合为c,个人习惯的权重为ω2,指令文本的语境信息集合为d,语境信息的权重为ω3,特性集合ae的数值为|ae|,指令文本的数值大小为|ω1b+ω2c+ω3d|,交互匹配因子为ρ;
67、当个人特性值小于0.5时,指令文本与交互数据库数据不匹配,更换交互数据库数据,直到个人特性值大于等于0.5,将第e个交互数据库数据与指令文本关联;
68、当个人特征值大于等于0.5时,将第e个交互数据库数据与指令文本关联;
69、更换指令文本匹配交互数据库数据,直到遍历完所有的指令文本;
70、交互模块:根据所述交互数据库建立虚拟交互模型,优化所述虚拟交互模型,将所述指令文本输入优化后的所述虚拟交互模型,输出交互结果。
71、本发明的有益效果是:
72、本发明是一种虚拟数字人的交互方法,与现有技术相比,本发明具有以下技术效果:
73、本发明通过预处理、特征提取、匹配数据库、构建模型、模型优化和虚拟交互步骤,可以提高虚拟数字人的交互的准确性,从而提高虚拟数字人的交互的精度,将虚拟数字人的交互优化,可以大大节省资源,提高工作效率,可以实现对交互的自动分析和优化,实时对语音指令数据进行特征提取和匹配数据库,对虚拟数字人的交互具有重要意义,可以适应不同标准的虚拟数字人的交互、不同系统的虚拟数字人的交互,具有一定的普适性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21289.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。