一种结合人脸识别的屏幕定向发声方法
- 国知局
- 2024-06-21 10:41:48
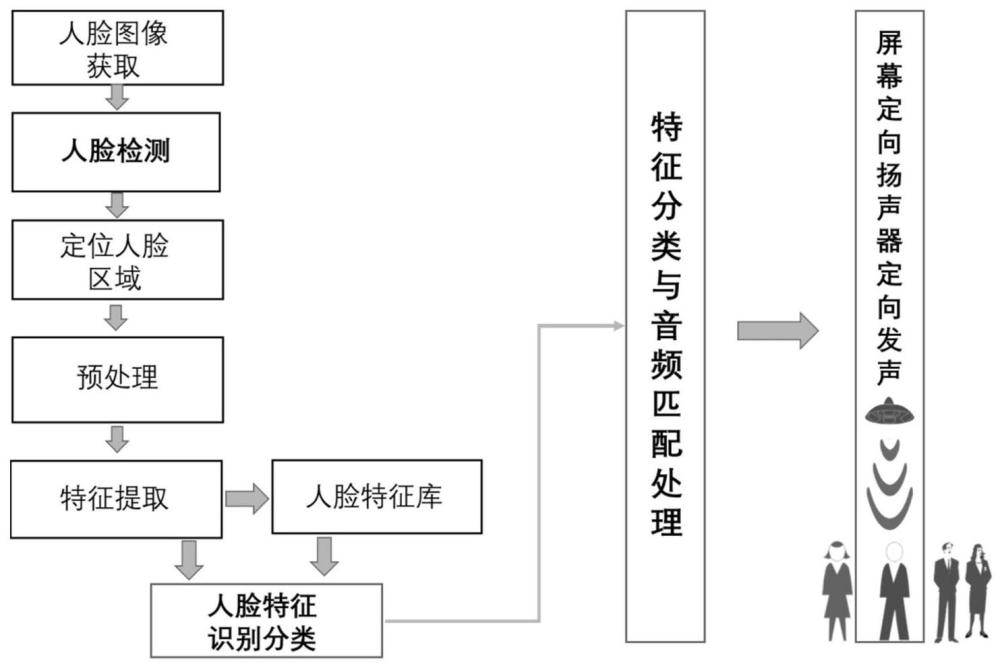
本发明涉及一种屏幕定向发声方法,尤其涉及一种结合人脸识别的屏幕定向发声方法。
背景技术:
1、随着生活水平的提高,在使用手机等多媒体设备时,人们除了对音质有高的要求之外,还逐渐重视隐私的保护以及多媒体设备对环境产生的噪声影响。传统扬声器体积大,且发出的声音不具备指向性,声音向空间各个方向传播,使用设备时,声音的交叉影响是让人难以接受的。目前解决音质问题的一个方案是外接分体式音箱,通过有线或者蓝牙等手段将音频信号传输至外接音箱产生高音质的可听声。但是,这种方式的局限之处太多,便携性等问题随之而来,所以适用场景很少。解决多媒体设备外放泄露隐私和噪音影响的方式为有线耳机或蓝牙耳机。使用耳机是目前比较普及的解决此类问题的手段,但是长时间使用耳机会对人耳产生不可逆的伤害,并且佩戴耳机也会产生不舒适感。
2、将具有良好指向性的参量阵扬声器和屏幕发声技术相结合就能得到一种解决上述问题的方案。与传统扬声器相比,屏幕参量阵定向扬声器的基本原理是直接利用屏幕后阵元带动屏幕发声,屏幕将兼具显示和发声的功能,所以无需再内置扬声器。但目前屏幕定向扬声器无法做到识别听众特征,给不同听众分类,进而选择性地播放与听众对应的内容,进一步提高隐私性,提供智能化服务。
技术实现思路
1、本发明的目的是提供一种利用屏幕定向扬声器结合人脸识别技术根据人脸特征选择性播放声音的方法,以解决多媒体设备对环境的噪声影响以及隐私性问题。
2、本发明的目的是通过以下技术方案加以实现的:一种结合人脸识别的屏幕定向发声方法,包括下列步骤:
3、步骤1:进行人脸检测;首先获取摄像头视频单帧人脸图像x,提取图像的haar特征,检测人脸范围区域;然后判断图像中是否存在人脸区域,如果不存在人脸区域,则重新进行图像人脸检测;如果存在人脸区域,则定位出人脸区域;
4、步骤2:进行人脸属性识别;将人脸数据库里的样本图像预处理后放入人脸分类器中进行训练,得到人脸分类器模型,然后使用人脸分类器模型对人脸图像x进行人脸属性识别,得到多个属性值;
5、步骤3:经过人脸识别得到不同的属性值后,再获得预设好的各属性值对应的音频集合,每个属性值都对应着适合该属性的一定数量的音频文件,且一个音频文件可以对应多个属性值,确保各种属性值对应的音频集合有共同的音频文件;找出所识别人脸对应属性值的各个音频集合的共同音频文件,再随机选择一个音频文件作为输出;
6、步骤4:音频文件输出给参量阵屏幕定向扬声器系统,系统中根据不同人脸属性值定向传送对应类型的音频。
7、本发明根据人脸识别技术对人脸特征进行分类,利用其结果实现屏幕定向扬声器选择性播放对应内容,从而提出了一种结合人脸识别的屏幕定向发声方法。利用声参量技术生成指向性的低频声波,可以使声波信号获得定向传播的能力,从而减少声音干扰;利用人脸属性识别,屏幕定向扬声器可以根据属性结果对不同的观众选择性播放不同内容,提升隐私性,更好地提供智能化服务。
8、综上,本发明的优点在于可以定向对观众播放与之匹配的内容,显著提高扬声器的利用率、极大提高播放内容与受众匹配程度。
技术特征:1.一种结合人脸识别的屏幕定向发声方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种结合人脸识别的屏幕定向发声方法,其特征在于,所述预处理工作包括缩放人脸图像、降噪、灰度转换、归一化、图像增强;归一化包括几何归一化和灰度归一化。
3.根据权利要求2所述的一种结合人脸识别的屏幕定向发声方法,其特征在于,所述人脸数据库为caltech faces人脸数据库。
4.根据权利要求3所述的一种结合人脸识别的屏幕定向发声方法,其特征在于,人脸属性识别的具体步骤如下:
5.根据权利要求4所述的一种结合人脸识别的屏幕定向发声方法,其特征在于,所述属性值包括性别、年龄段、肤色、表情。
6.根据权利要求5所述的一种结合人脸识别的屏幕定向发声方法,其特征在于,所述参量阵屏幕定向扬声器系统包括模数转换模块、数模转换模块、滤波器模块、功率放大器、fpga和屏幕换能器,具体流程为:模数转换模块对输入系统的音频信号进行采样,采样后的数据传给fpga,在fpga内对音频信号进行处理得到数字信号,然后由数模转换模块将超声频段的数字信号变为模拟信号,再由滤波器模块使信号满足系统参数,信号由功率放大器加到屏幕换能器上,屏幕换能器发出的超声经空气的自解调,得到高指向性的可听声。
技术总结本发明公开了一种结合人脸识别的屏幕定向发声方法。利用人脸识别技术对人脸特征属性进行分类识别,根据分类结果实现对目标对象定向播放与类别对应内容。利用声参量技术生成指向性的低频声波,可以使声波信号获得定向传播的能力,从而减少声音干扰;利用人脸属性识别,屏幕定向扬声器可以根据属性结果对不同的观众选择性播放不同内容,提升隐私性,更好地提供智能化服务。本发明的优点在于可以定向对观众播放与之匹配的内容,显著提高定向扬声器的利用率、极大提高播放内容与受众匹配程度。技术研发人员:李学生,赵晓瑶,彭旭,陈敏,徐利梅,谢晓梅,魏明珠,吴雨冲,马忠慧,杨敏,冉宇受保护的技术使用者:电子科技大学技术研发日:技术公布日:2024/2/1本文地址:https://www.jishuxx.com/zhuanli/20240618/21273.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表