一种环境噪声识别方法、系统、设备和介质与流程
- 国知局
- 2024-06-21 10:42:09
本发明涉及声音识别,特别是涉及一种环境噪声识别方法、系统、设备和介质。
背景技术:
1、声音作为信息的主要载体,是人们感知周围环境的重要途径之一,也是反映生物行为的重要特征。声音信号的处理一直备受研究学者的关注,研究重点主要有人声和环境声音两类,由此衍生出的主要研究方向为自动语音识别和环境声音分类(environmentalsound classification, esc)。
2、自动语音识别的任务是把平稳的人类语音信号转换为文本信息,而esc则是将各类非平稳的环境声音信号进行准确的分类。由于esc 的研究重点是自然界中的非平稳声信号,并且受环境因素的影响,现实中常会存在复杂的背景噪声,因此其研究难度相对较大。
3、由于esc任务的标记数据相对稀缺,因此当前卷积神经网络在esc任务上存在难以扩展模型深度问题,机器学习与深度学习模型正是依赖于海量数据,不断训练与更新模型,逐步提升模型的性能。虽然我们可以通过网络等多媒体获得海量数据,但是这些数据一般是初级的原始形态,大多都缺乏正确的人工标注。同时,根据应用的不同,所需的数据类型,数据标注样式也会有变化。因此,需要利用已知的数据标记设计有效的环境声音分类方法。
技术实现思路
1、本发明的目的是解决现有环境噪声分类技术中缺乏大规模标签数据集导致的声音分类不准确的问题。
2、为了实现上述目的,第一方面,本发明提供一种环境噪声识别方法,所述方法包括:
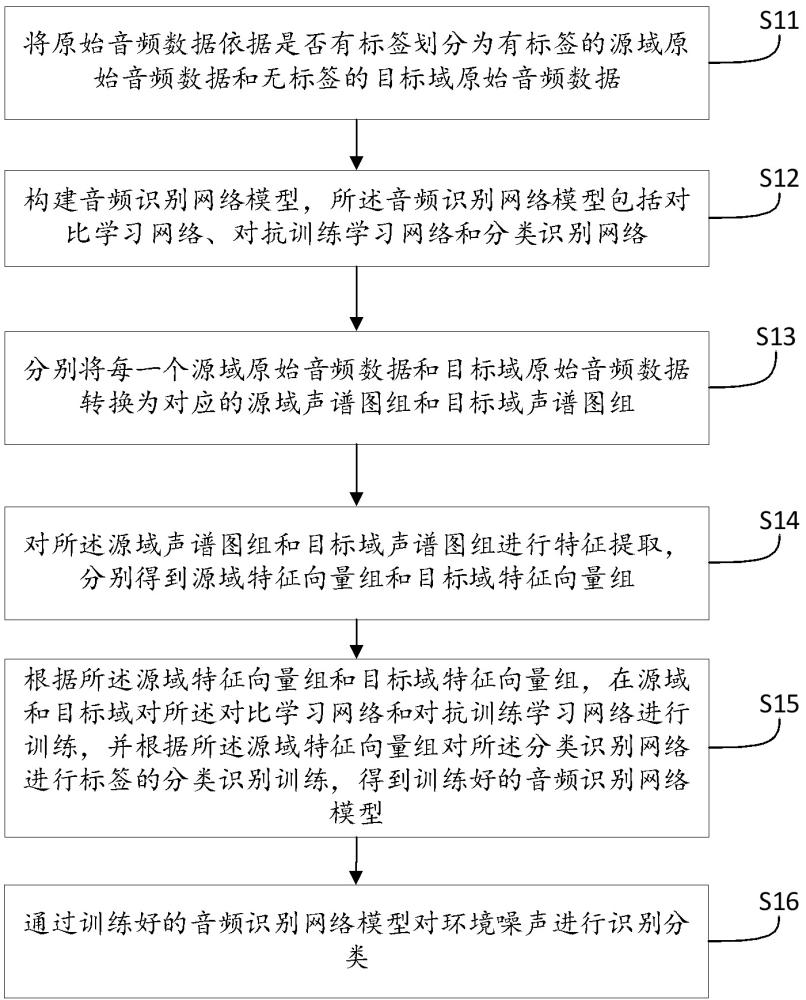
3、将原始音频数据依据是否有标签划分为有标签的源域原始音频数据和无标签的目标域原始音频数据;
4、构建音频识别网络模型,所述音频识别网络模型包括对比学习网络、对抗训练学习网络和分类识别网络;
5、分别将每一个源域原始音频数据和目标域原始音频数据转换为对应的源域声谱图组和目标域声谱图组;
6、对所述源域声谱图组和目标域声谱图组进行特征提取,分别得到源域特征向量组和目标域特征向量组;
7、根据所述源域特征向量组和目标域特征向量组,在源域和目标域对所述对比学习网络和对抗训练学习网络进行训练,并根据所述源域特征向量组对所述分类识别网络进行标签的分类识别训练,得到训练好的音频识别网络模型;
8、通过训练好的音频识别网络模型对环境噪声进行识别分类。
9、进一步地,所述分别将每一个源域原始音频数据和目标域原始音频数据转换为对应的源域声谱图组和目标域声谱图组,包括:
10、使用连续小波变换将源域原始音频数据转换为源域声谱图;
11、使用离散小波变换将源域原始音频数据转换为源域数据增强声谱图,并将所述源域数据增强声谱图分别进行旋转、锐化、色彩调整和翻转得到源域数据增强声谱图组;
12、每个源域原始音频数据对应的源域声谱图和源域数据增强声谱图组构成一个源域声谱图组;
13、使用短时傅里叶变换将目标域原始音频数据转换为目标域声谱图;
14、使用离散小波变换将目标域原始音频数据转换为目标域数据增强声谱图,并将所述目标域数据增强声谱图分别进行旋转、锐化、色彩调整和翻转得到目标域数据增强声谱图组;
15、每个目标域原始音频数据对应的目标域声谱图和目标域数据增强声谱图组构成一个目标域声谱图组;
16、进一步地,所述根据所述源域特征向量组和目标域特征向量组,在源域和目标域对所述对比学习网络和对抗训练学习网络进行训练,包括:
17、分别在源域和目标域,以最小批处理的大小为单位,选取单位内一个音频对应的特征向量组作为正样本,单位内其他音频的特征向量组作为负样本,通过对比学习网络进行对比学习,分别产生多个源域正负样本对和目标域正负样本对,并分别存储进源域样本队列和目标域样本队列中;
18、从所述源域样本队列和目标域样本队列选取数据输入对抗训练学习网络进行对抗训练学习,将源域的特征学习分类能力迁移到目标域中。
19、进一步地,所述通过对比学习网络进行对比学习,分别产生多个源域正负样本对和目标域正负样本对,包括:
20、分别在源域和目标域,对单位内每个特征向量组通过对比学习,拉近同一特征向量组内的特征向量之间的距离,拉远所述特征向量组内的特征向量与其他特征向量组内特征向量的距离,以形成正负样本对。
21、进一步地,从所述源域样本队列和目标域样本队列选取数据输入对抗训练学习网络进行对抗训练学习,将源域的特征学习分类能力迁移到目标域中,包括:
22、将源域样本队列和目标域样本队列中的数据进行梯度反转,提取时间序列,并创建相应的嵌入值,通过所述嵌入值,使用领域判别器进行对抗训练,根据源域和目标域的数据分布,预测目标域的数据所属的标签。
23、进一步地,所述音频识别网络模型训练过程中的总损失函数为:
24、
25、其中,为预测损失,为领域分类损失的权重系数,取值范围为(0,1),为领域分类损失,为对比损失的权重系数,取值范围为(0,1),为源域的对比损失,为目标域的对比损失。
26、进一步地,所述短时傅里叶变换将原始音频数据的音频信号分解为一系列时间窗口,对每个时间窗口应用傅里叶变换,得到音频信号在时间和频率上的二维表示;
27、所述连续小波变换使用不同尺度的小波函数对原始音频数据的音频信号进行分解,得到声谱图在视频域上的连续小波变换表示;
28、所述离散小波变换将原始音频数据的音频信号分解为不同频带的多分辨率表示,得到多尺度域上的离散小波变换表示。
29、第二方面,本发明提供一种环境噪声识别系统,用于实现上述环境噪声识别方法,所述系统包括:
30、数据分类模块,用于将原始音频数据依据是否有标签划分为有标签的源域原始音频数据和无标签的目标域原始音频数据。
31、模型构建模块,用于构建音频识别网络模型,所述音频识别网络模型包括对比学习网络、对抗训练学习网络和分类识别网络。
32、声谱转换模块,用于分别将每一个源域原始音频数据和目标域原始音频数据转换为对应的源域声谱图组和目标域声谱图组。
33、特征提取模块,用于对所述源域声谱图组和目标域声谱图组进行特征提取,分别得到源域特征向量组和目标域特征向量组。
34、模型训练模块,用于根据所述源域特征向量组和目标域特征向量组,在源域和目标域对所述对比学习网络和对抗训练学习网络进行训练,并根据所述源域特征向量组对所述分类识别网络进行标签的分类识别训练,得到训练好的音频识别网络模型。
35、识别分类模块,用于通过训练好的音频识别网络模型对环境噪声进行识别分类。
36、第三方面,本发明提供一种计算机设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现如上所述的环境噪声识别方法。
37、第四方面,本发明提供一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序;其中,所述计算机程序在运行时控制所述计算机可读存储介质所在的设备执行如上所述的环境噪声识别方法。
38、本发明的一种环境噪声识别方法、系统、设备和介质,与现有技术相比,其有益效果在于:基于少量标签数据和大量无标签数据,充分利用无标签环境噪声分类数据集,避免了目前需要从头收集数据、花费大量人力物力标记的问题,降低了数据标记的成本;采用对抗学习的无监督域适应方法,将有标签域的音频分类能力,迁移到无标签域中,提高环境噪声分类的准确性,缓解了小样本数据的问题,提高了模型的泛化能力。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21330.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。