一种中文口音识别方法、装置、设备及介质
- 国知局
- 2024-06-21 10:42:06
本发明涉及口音识别,具体涉及一种中文口音识别方法、装置、设备及介质。
背景技术:
1、口音指个人或群体特有的发音方式,其反映了特定地区、社会群体或个人的语音特点和发音习惯;当前常见的口音类型有个人口音、地域口音、社会群体口音和第二语言口音。研究非母语学习者口音的价值在于推动文化多样性的尊重与认可、改进语言教育和技术应用、了解语言的历史演变和身份认同等方面。口音识别本质上是对口音类型的分类,而口音语音识别本质上是生成口音语音对应的文本,二者虽可单独研究,但口音识别经常以先行步骤融合到口音语音识别研究中。现市面上,单独研究口音识别的技术以分类算法为框架,集中于特征研究,侧重口音自身特征信息的挖掘,具有更高的口音分辨能力。
2、当前市面上的非母语的中文口音识别技术面临的一些现状在于:第一,口音的种类多样、复杂,缺少合适的口音数据集,非母语学习者的中文口音识别是一个典型的低资源问题;第二,由于群体内说话者的口音之间差异从而影响到口音识别的类区分性;第三,专门针对非母语的中文口音识别研究鲜有涉及;同时,尽管当前已经有很多口音识别的研究工作和成果,但是这些方案一般都是面向英语口音的,而中文口音识别研究主要集中在方言分类领域。
3、有鉴于此,提出本技术。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种中文口音识别方法、装置、设备及介质,能够有效解决现有技术中的非母语的中文口音识别技术面临的口音的种类多样、复杂,缺少合适的口音数据集,非母语学习者的中文口音识别是一个典型的低资源;第二,由于群体内说话者的口音之间差异从而影响到口音识别的类区分性;第三,专门针对非母语的中文口音识别研究鲜有涉及;同时,尽管当前已经有很多口音识别的研究工作和成果,但是这些方案一般都是面向英语口音的,而中文口音识别研究主要集中在方言分类领域的问题。
2、本发明公开了一种中文口音识别方法,包括:
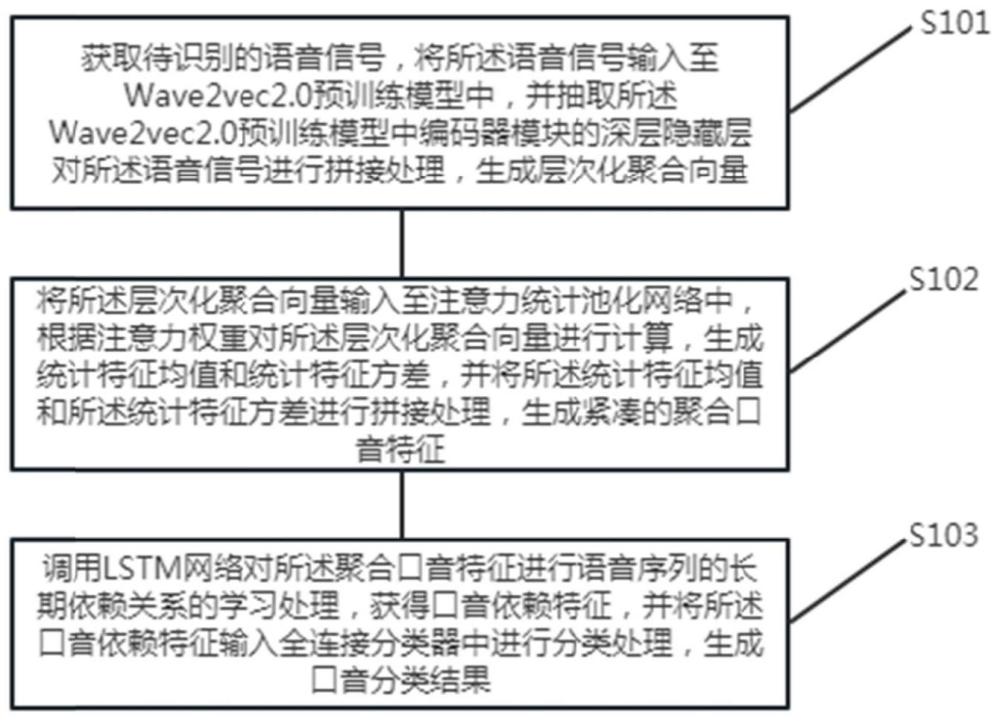
3、获取待识别的语音信号,将所述语音信号输入至wave2vec2.0预训练模型中,并抽取所述wave2vec2.0预训练模型中编码器模块的深层隐藏层对所述语音信号进行拼接处理,生成层次化聚合向;
4、所述层次化聚合向量输入至注意力统计池化网络中,根据注意力权重对所述层次化聚合向量进行计算,生成统计特征均值和统计特征方差,并将所述统计特征均值和所述统计特征方差进行拼接处理,生成紧凑的聚合口音特征;
5、调用lstm网络对所述聚合口音特征进行语音序列的长期依赖关系的学习处理,获得口音依赖特征,并将所述口音依赖特征输入全连接分类器中进行分类处理,生成口音分类结果。
6、优选地,获取待识别的语音信号,将所述语音信号输入至wave2vec2.0预训练模型中,并抽取所述wave2vec2.0预训练模型中编码器模块的深层隐藏层对所述语音信号进行拼接处理,生成层次化聚合向量,具体为:
7、获取待识别的语音信号x,将所述语音信号x输入至wave2vec2.0预训练模型中,其中,所述wave2vec2.0预训练模型包括cnns特征提取模块、transformer编码器模块、量化模块和对比损失模块;
8、抽取所述transformer编码器模块中所有编码层的隐藏状态,生成隐藏层向量列表,公式为:
9、h1,h2,…,hl,…hl=wav2vec2.0transformer(x)
10、其中,hl为所述transformer模块第l层隐藏向量,l表示总层数;
11、对所述隐藏层向量列表中的每个元素进行使用层归一化处理,生成归一化隐藏状态列表,公式为:
12、
13、其中,是序列向量,其序列长度等于所述语音信号x的语音帧数量;融合不同层的所述归一化隐藏状态列表中的归一化隐藏状态向量生成层次化聚合特征向量计算公式为:
14、
15、其中,s为常数,s∈{1,2,…,l}。
16、优选地,将所述层次化聚合向量输入至注意力统计池化网络中,根据注意力权重对所述层次化聚合向量进行计算,生成统计特征均值和统计特征方差,并将所述统计特征均值和所述统计特征方差进行拼接处理,生成紧凑的聚合口音特征,具体为:
17、调用注意力统计池化层将所述层次化聚合向量聚合成一个固定维度的话语级别的特征向量,生成口音聚合向量;
18、对所述层次化聚合特征向量进行自注意力变换处理,得到所述语音信号x每个帧的注意力权重α,注意力权重α通过全连接层和softmax函数计算,计算公式为:
19、
20、其中,是第t帧的特征向量,wα和bα是全连接层的参数,at是第t帧的注意力权重,t是所述语音信号x的帧数量;
21、利用所述注意力权重α对所述语音信号x序列的所述层次化聚合特征向量进行加权平均和加权标准差计算处理,生成两个话语级别的特征向量,得到相对应的统计特征均值m和方差s,计算公式为:
22、
23、
24、其中,t是所述语音信号x的帧数量,是第t帧的层次化聚合特征向量;
25、将统计特征均值m和方差s进行拼接处理,生成聚合口音嵌入c,计算公式为:c=concat(m,s)。
26、优选地,调用lstm网络对所述聚合口音特征进行语音序列的长期依赖关系的学习处理,获得口音依赖特征,并将所述口音依赖特征输入全连接分类器中进行分类处理,生成口音分类结果,具体为:
27、将所述聚合口音嵌入c传入口音分类网络中进行预处理,其中,所述口音分类网络由一个lstm层和一个全连接层ffc组成,lstm层用于学习所述聚合口音嵌入c的时序依赖关系,其输出是时序特征向量flstm,全连接层ffc用于实现类别分类,其输出为k个口音类别的对数得分向量sc,公式为:
28、sc=ffc(flstm)=wflstm+b
29、其中,w和b是全连接层的参数;
30、计算center-loss损失函数lc,公式为:
31、
32、其中,b是批量更新的batch样本数,fi是第i个语音信号x的时序特征向量,是第i个语音信号x所属类别的中心向量;
33、计算交叉熵损失函数ls,公式为:
34、
35、其中,tij是第i个样本对应第j个类别的真实标签,如果第j个类别是真实类别,则tik为1,否则为0,yij为第i个语音信号x对应第j个类别的预测概率;
36、计算总损失函数l,公式为:
37、l=lc+λls
38、其中,λ是一个平衡因子,用于控制两个损失函数之间的权重;
39、使用梯度下降法来优化总损失函数,直至总损失函数l至预设的阈值为止,从而生成口音分类结果。
40、本发明还公开了一种中文口音识别装置,包括:
41、层次化聚合向量生成单元,用于获取待识别的语音信号,将所述语音信号输入至wave2vec2.0预训练模型中,并抽取所述wave2vec2.0预训练模型中编码器模块的深层隐藏层对所述语音信号进行拼接处理,生成层次化聚合向量;
42、聚合口音特征生成单元,用于将所述层次化聚合向量输入至注意力统计池化网络中,根据注意力权重对所述层次化聚合向量进行计算,生成统计特征均值和统计特征方差,并将所述统计特征均值和所述统计特征方差进行拼接处理,生成紧凑的聚合口音特征;
43、口音分类结果生成单元,用于调用lstm网络对所述聚合口音特征进行语音序列的长期依赖关系的学习处理,获得口音依赖特征,并将所述口音依赖特征输入全连接分类器中进行分类处理,生成口音分类结果。
44、优选地,所述层次化聚合向量生成单元具体用于:
45、获取待识别的语音信号x,将所述语音信号x输入至wave2vec2.0预训练模型中,其中,所述wave2vec2.0预训练模型包括cnns特征提取模块、transformer编码器模块、量化模块和对比损失模块;
46、抽取所述transformer编码器模块中所有编码层的隐藏状态,生成隐藏层向量列表,公式为:
47、h1,h2,…,hl,…hl=wav2vec2.0transformer(x)
48、其中,hl为所述transformer模块第l层隐藏向量,l表示总层数;
49、对所述隐藏层向量列表中的每个元素进行使用层归一化处理,生成归一化隐藏状态列表,公式为:
50、
51、其中,是序列向量,其序列长度等于所述语音信号x的语音帧数量;
52、融合不同层的所述归一化隐藏状态列表中的归一化隐藏状态向量生成层次化聚合特征向量计算公式为:
53、
54、其中,s为常数,s∈{1,2,…,l}。
55、优选地,所述聚合口音特征生成单元具体用于:
56、调用注意力统计池化层将所述层次化聚合向量聚合成一个固定维度的话语级别的特征向量,生成口音聚合向量;
57、对所述层次化聚合特征向量进行自注意力变换处理,得到所述语音信号x每个帧的注意力权重α,注意力权重α通过全连接层和softmax函数计算,计算公式为:
58、
59、其中,是第t帧的特征向量,wα和bα是全连接层的参数,at是第t帧的注意力权重,t是所述语音信号x的帧数量;
60、利用所述注意力权重α对所述语音信号x序列的所述层次化聚合特征向量进行加权平均和加权标准差计算处理,生成两个话语级别的特征向量,得到相对应的统计特征均值m和方差s,计算公式为:
61、
62、
63、其中,t是所述语音信号x的帧数量,是第t帧的层次化聚合特征向量;
64、将统计特征均值m和方差s进行拼接处理,生成聚合口音嵌入c,计算公式为:c=concat(m,s)。
65、优选地,所述口音分类结果生成单元具体用于:
66、将所述聚合口音嵌入c传入口音分类网络中进行预处理,其中,所述口音分类网络由一个lstm层和一个全连接层ffc组成,lstm层用于学习所述聚合口音嵌入c的时序依赖关系,其输出是时序特征向量flstm,全连接层ffc用于实现类别分类,其输出为k个口音类别的对数得分向量sc,公式为:
67、sc=ffc(flstm)=wflstm+b
68、其中,w和b是全连接层的参数;
69、计算center-loss损失函数lc,公式为:
70、
71、其中,b是批量更新的batch样本数,fi是第i个语音信号x的时序特征向量,是第i个语音信号x所属类别的中心向量;
72、计算交叉熵损失函数ls,公式为:
73、
74、其中,tij是第i个样本对应第j个类别的真实标签,如果第j个类别是真实类别,则tij为1,否则为0,yij为第i个语音信号x对应第j个类别的预测概率;
75、计算总损失函数l,公式为:
76、l=lc+λls
77、其中,λ是一个平衡因子,用于控制两个损失函数之间的权重;
78、使用梯度下降法来优化总损失函数,直至总损失函数l至预设的阈值为止,从而生成口音分类结果。
79、本发明还公开了一种中文口音识别设备,包括处理器、存储器以及存储在所述存储器中且被配置由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如上任意一项所述的一种中文口音识别方法。
80、本发明还公开了一种可读存储介质,存储有计算机程序,所述计算机程序能够被该存储介质所在设备的处理器执行,以实现如上任意一项所述的一种中文口音识别方法。
81、综上所述,本实施例提供的一种中文口音识别方法、装置、设备及介质,能够识别非母语人群的口音。首先,语音信号输入wave2vec2.0预训练模型抽取编码器的深层隐藏层进行拼接,得到层次化聚合向量。然后,将层次化聚合向量输入到注意力统计池化网络,根据注意力权重计算统计特征均值和统计特征方差,两者拼接得到紧凑的聚合口音特征。最后,聚合口音特征输入到lstm网络中学习语音序列的长期依赖关系,获得口音依赖特征,将口音依赖特征输入全连接分类器实现口音分类。所述中文口音识别方法利用语音预训练模型提取更高层次的语义信息,并利用注意力统计池化捕捉语音特征在时间上的变化和分布,有效地提取口音特征并增强口音特征的判别性。从而解决现有技术中的非母语的中文口音识别技术面临的口音的种类多样、复杂,缺少合适的口音数据集,非母语学习者的中文口音识别是一个典型的低资源;第二,由于群体内说话者的口音之间差异从而影响到口音识别的类区分性;第三,专门针对非母语的中文口音识别研究鲜有涉及;同时,尽管当前已经有很多口音识别的研究工作和成果,但是这些方案一般都是面向英语口音的,而中文口音识别研究主要集中在方言分类领域的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21321.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。