一种具有视听感知能力的实时对话型数字分身生成方法
- 国知局
- 2024-06-21 10:42:05
本发明属于图像语音生成领域,尤其涉及一种具有视听感知能力的实时对话型数字分身的生成方法。
背景技术:
1、数字分身指形象与真人原型高度相似、具有交互能力的虚拟人系统。实时对话型数字分身生成任务是指在对话场景中,数字分身通过感知用户的语音、动作等交互输入,实时地合成回复的语音内容,并生成形象真实、唇形动作与语音内容同步、肢体动作符合语义信息的虚拟人形象图像序列,输出音视频内容,以实现数字分身与真人的实时对话。在人工智能、虚拟现实等技术浪潮的带动下,数字分身生成越来越受到关注,并广泛应用于人机交互、影视制作、虚拟主播、智能员工等领域。具有视听感知能力的实时对话型数字分身技术侧重于用户服务功能,以情景对话的形式为用户奉上贴心服务,具有一定的民生意义。
2、然而,受限于人脸结构的复杂性、唇部运动的多样性、肢体动作的复杂性,具有感知功能的对话型数字分身生成成为计算机视听感知领域研究的重点和难点之一。目前,实时对话型数字分身生成存在以下几个问题:1)感知能力弱:强而准确的感知能力是数字分身具有良好交互体验的保障,现有的数字分身方案通常只具有文字感知或简单的视听感知,单一或不准确的感知能力将严重影响数字分身的交互效率和体验。例如,视听感知要求准确定位用户在摄像头前的位置,并快速识别用户的基本手势动作,而用户位置的随意性以及手势动作的多样性,给视听感知带来了一定的挑战,现有简单的视听感知并不能准确地进行用户定位和动作识别;2)形象真实感低:数字分身形象的保真度和清晰度是影响用户体验的重要因素,现有的数字分身方案普遍存在画面清晰度差、保真度低的问题,降低了形象的真实感,十分影响用户体验,限制了数字分身的服务领域和用途;3)数字分身手势动作单一、僵硬:手势动作是人在说话时自然而然会产生的动作,手势动作种类较多,也更生动,但是现有的数字分身生成方案中,所允许的数字分身手势动作单一,很容易失去用户的吸引力,并且不同动作之间所允许的最小时间间隔较大,比较僵硬,不够自然;4)语音与唇部运动不一致:在数字分身生成中,音频和视频的多模态特征建模匹配不准确,极易引起唇部运动与语音不匹配;5)实时性较差:对话型数字分身要求接收到用户的指令后,能够在较短的时间内做出包括语音、手势动作以及视频图像等多方面的回应,对实时性要求较高,而现有系统往往存在较高的延迟,用户体验感较差。
技术实现思路
1、本技术提供了一种数字分身生成方法,用于解决实时对话型数字分身生成任务中存在的感知能力弱、手势动作单一、语音与唇部运动不一致以及实时性较差的问题。本发明采用的技术方案流程如下:
2、一种具有视听感知能力的实时对话型数字分身生成方法,其特征在于包括如下步骤:
3、在训练和预处理阶段录制音视频素材并进行预处理,使用音视频素材训练语音合成模型、唇形生成模型和面部增强模型;
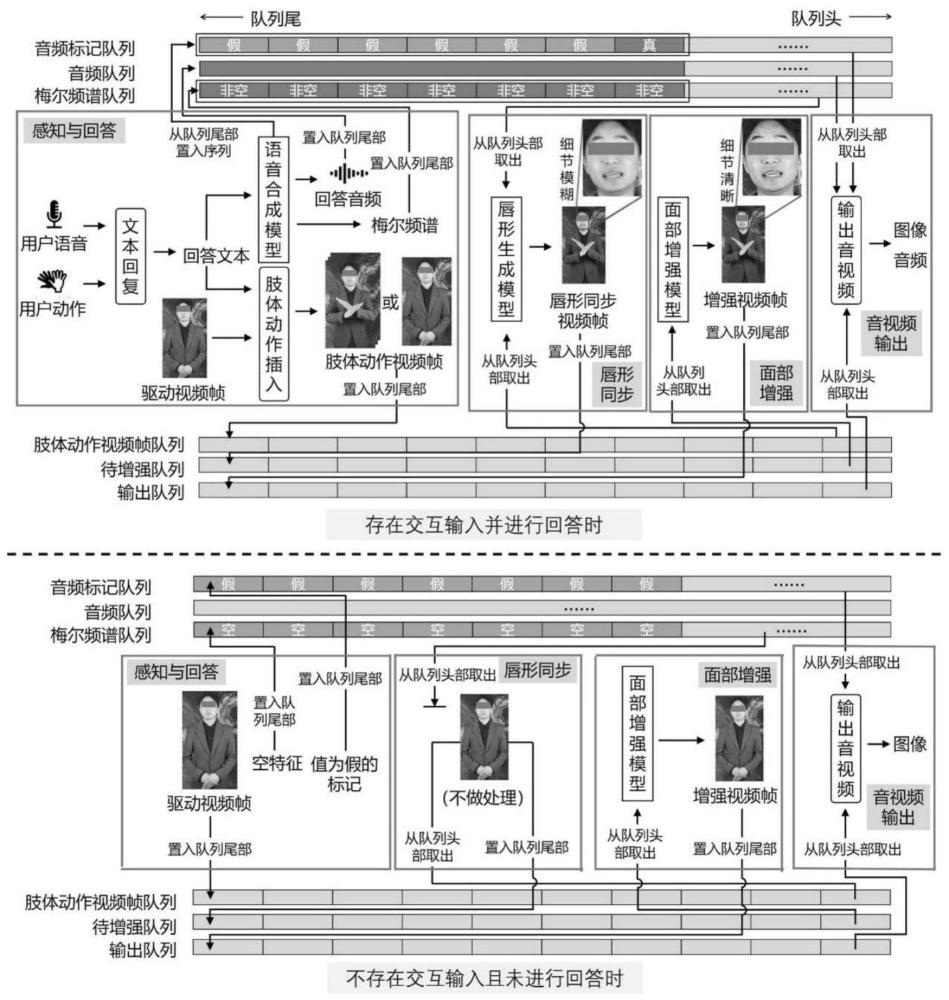
4、在数字分身生成阶段建立缓冲区,经过感知与回答、唇形同步、面部增强和音视频输出四个步骤,生成实时对话的数字分身。
5、如上所述的方法,其特征在于,在训练和预处理阶段,录制音视频素材并进行预处理,包括:
6、在相同的硬件条件和环境下录制数字分身的真人原型人物的音视频素材,包括语音音频、驱动视频、动作视频和训练音视频,其中,所述语音音频为一段该真人原型朗读预先准备的文本语料的音频内容,驱动视频为一段该真人原型人物在自然状态下无大幅度面部动作且双手保持在身体指定位置的视频,所述动作视频为多段所述真人原型人物表现各种手势动作的视频,其中的手势动作将作为动作插入时的预置动作,每段动作的开始和结束时刻该人物的双手均需保持在所述驱动视频中双手保持的指定位置处,以便于与驱动视频过渡,所述训练音视频为一段或多段该真人原型人物在自然状态下进行朗读的音视频;
7、预处理包括:
8、指定视频帧率,并将所有视频素材调整至该帧率;
9、使用现有的插帧模型,以驱动视频的最后一帧为起始帧,驱动视频的第一帧为终止帧进行插帧,获得一组由插帧模型合成的、能够使驱动视频首尾自然过渡的合成帧,并按时间顺序置入驱动视频的尾部,具体地,假设驱动视频的最后一帧为第n帧,则将起始帧至终止帧间插帧得到的共k帧合成帧依次视为第n+1至n+k帧;
10、定义一组肢体动作的触发关键词,确定各个关键词所对应的动作视频;
11、定义一组动作-回答关系,确定当数字分身系统接收到用户各种肢体动作交互输入时,所对应的固定回答的语音的文本。
12、如上所述的方法,其特征在于,在训练和预处理阶段,使用音视频素材训练语音合成模型、唇形生成模型和面部增强模型,包括:
13、使用所述语音音频和所述文本语料对现有的经公开大型语音数据集预训练的语音合成模型进行微调,得到所述语音合成模型,该语音合成模型的输入为文本,输出为文本对应的音频和音频的梅尔频谱;
14、提取训练音视频的音频,将该音频转化为帧率与所述视频帧率相同的梅尔频谱特征,使用所述训练音视频的rgb帧和训练音视频中音频的梅尔频谱特征对现有的经公开的大量音视频数据预训练的音频驱动的唇形同步模型进行微调,得到所述唇形生成模型;
15、将所述训练音视频中音频的梅尔频谱和驱动视频输入所述唇形生成模型,得到低分辨率、与训练音视频中音频同步的合成视频,使用该合成视频和训练音视频中的视频,分别作为源数据和目标数据训练现有的人脸替换网络,得到所述面部增强模型。
16、如上所述的方法,其特征在于,在数字分身生成阶段建立缓冲区,包括:
17、提取驱动视频的所有rgb帧,并按时间先后顺序从小到大标记序号;
18、建立肢体动作视频帧队列、待增强队列、音频队列、梅尔频谱队列、音频标记队列和输出队列作为缓冲区,其中肢体动作视频帧队列存放肢体动作视频帧,待增强队列存放待进行面部增强的视频帧,音频队列存放待播放的音频,梅尔频谱队列存放待播放音频的梅尔频谱特征,音频标记队列用于存放指示是否应开始播放音频的布尔标记,输出队列存放经面部增强后用于最终输出的视频帧。
19、如上所述的方法,其特征在于,在数字分身生成阶段的感知与回答步骤的具体过程,包括:
20、监听获取实时的音频数据,摄像头采集用户的视频数据,根据音频响度判断音频数据中是否存在语音交互信息,根据现有的人体关键点识别模型判断视频数据中是否存在交互动作及识别交互动作的种类:
21、1)若存在所述语音交互信息或交互动作:
22、根据语音交互信息或交互动作进行文本回复,获得数字分身的回答文本;
23、将所述回答文本输入经训练得到的所述语音合成模型,合成回答的音频和音频的梅尔频谱,将所合成的回答音频置入音频队列,按照所述视频帧率切分得到与驱动视频帧长相同的音频帧,将各音频帧的梅尔频谱特征依次置入梅尔频谱队列,建立音频标记序列,序列长度为音频帧的帧数,其中首个标记的值为真,用于表示该标记所对应的时刻为音频起始时刻,其余标记的值为假,将序列中的音频标记依次置入音频标记队列;
24、使用现有的分词模型对所述回答文本进行分词,根据分词结果进行肢体动作插入,获得肢体动作视频帧序列,将肢体动作视频帧序列依次置入肢体动作视频帧队列;
25、2)若不存在所述语音交互信息或交互动作,则代表数字分身不需要生成回答或肢体动作,取用最长时间未被使用的且序号最小的一帧驱动视频帧,将该驱动视频帧置入肢体动作视频帧队列,在音频标记队列中置入一个值为假的标记,在梅尔频谱队列中置入一个值为空的特征,用于表示该时间段内无音频内容。
26、如上所述的方法,其特征在于,在数字分身生成阶段的唇形同步步骤的具体过程,包括:
27、从梅尔频谱队列中取出队列头部的梅尔频谱特征,从肢体动作视频帧队列中取出队列头部的肢体动作视频帧,对梅尔频谱特征进行判断:
28、1)若该梅尔频谱特征不为空,则将梅尔频谱特征与肢体动作视频帧输入所述唇形生成模型,合成与该梅尔频谱特征所对应的音频帧同步的唇形同步视频帧,将该唇形同步视频帧置入待增强队列;
29、2)若该梅尔频谱特征为空,则代表不需要进行唇形同步,直接将该肢体动作视频帧置入待增强队列。
30、如上所述的方法,其特征在于,在数字分身生成阶段的面部增强步骤的具体过程,包括:
31、从待增强队列中取出队列头部的待增强视频帧,将待增强视频帧输入所述面部增强模型,获得面部清晰度更高的增强视频帧,将增强视频帧置入输出队列。
32、所述音视频输出,包括:
33、从输出队列中取出队列头部的增强视频帧,显示增强视频帧,并根据所述视频帧率确定显示持续时间,从音频标记队列中取出头部的音频标记,并进行判断:
34、若音频标记值为真,则从音频队列中取出队列头部的音频,开始异步播放该音频,实现音画同步;
35、若音频标记值为假,则不进行额外操作。
36、如上所述的方法,其特征在于,在感知与回答步骤中,根据语音交互信息或交互动作进行文本回复,获得数字分身的回答文本,包括:
37、若存在语音交互信息,则使用现有的语音识别模型将语音实时转化为文本,将所转化的文本输入已有的问答语言模型,得到所述回答文本;
38、若只存在交互动作,则使用现有的动作识别模型识别该动作,并按照所述动作-回答关系进行匹配,得到所述回答文本。
39、如上所述的方法,其特征在于,在感知与回答步骤中,根据分词结果进行肢体动作插入,获得肢体动作视频帧序列,包括:
40、取最长时间未被使用的且序号最小的一帧驱动视频帧作为待使用驱动视频帧,使用所述触发关键词对所述分词结果进行匹配;
41、若匹配成功,则使用现有的插帧模型,分别以肢体动作视频帧队列的最后一帧和被匹配的关键词所对应的动作视频的第一帧作为起始帧和终止帧进行插帧,以该动作视频的最后一帧和所述待使用驱动视频帧作为起始帧和终止帧进行插帧,实现已在肢体动作视频帧队列中的肢体动作视频帧、被匹配的关键词所对应的动作视频帧、待使用驱动视频帧间的不连续的图像内容的平滑过渡,将插帧模型生成的帧、动作视频帧和所获得的驱动视频帧按时间顺序组合成为肢体动作视频帧序列;
42、若无关键词匹配成功,则将所述待使用驱动视频帧作为长度为1的肢体动作视频帧序列。
43、与现有技术相比,本发明具有如下优点:
44、1.具备视觉与听觉两类感知能力,能识别真人的话语与手势并做出自然的回应;
45、2.数字分身表现渠道丰富,具有声音、表情和手势;
46、3.计算资源占用少且响应时延低,能在消费级家用pc机上部署并满足实时对话需求;
47、4.能同时应对开放式对话场景与专项业务场景的对话需求。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21318.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表