讲话者识别方法、讲话者识别装置以及讲话者识别程序与流程
- 国知局
- 2024-06-21 10:42:02
本公开涉及识别不特定讲话者的技术。
背景技术:
1、专利文献1公开了如下的技术:对输入模式的发生内容和标准模式的发生内容进行声音识别,基于得到的发生内容信息,求出输入模式和预先注册的多个注册讲话者的标准模式的发生内容一致的一致区间,求出该一致区间内的输入模式与标准模式的差异度,并基于求出的差异度识别产生输入声音的讲话者。
2、非专利文献1公开了通过对多个注册讲话者所发出的预先决定的固定关键词的声音的特征量和不特定讲话者发出的固定关键词的特征量进行比较来识别不特定讲话者的技术。
3、然而,在上述以往技术中,在不特定讲话者的发声与预先注册的注册讲话者的发声内容不一致的情况下,不能识别不特定讲话者,因而需要进一步的改善。
4、在先技术文献
5、专利文献
6、专利文献1:jp专利第3075250号公报
7、非专利文献
8、非专利文献1:hiroshi fujimura,ning ding,daichi hayakawa and takehikokagoshima“simultaneous flexible keyword detection and text-dependent speakerrecognition for low-resource devices”proceedings of the 9th internationalconference on pattern recognition applications and methods(icpram 2020),pages297-307
技术实现思路
1、本公开是为了解决上述的课题而完成的,其目的在于,提供即便在不特定讲话者的发声内容与预先注册的注册讲话者的发声内容不一致,也能够识别不特定讲话者的技术。
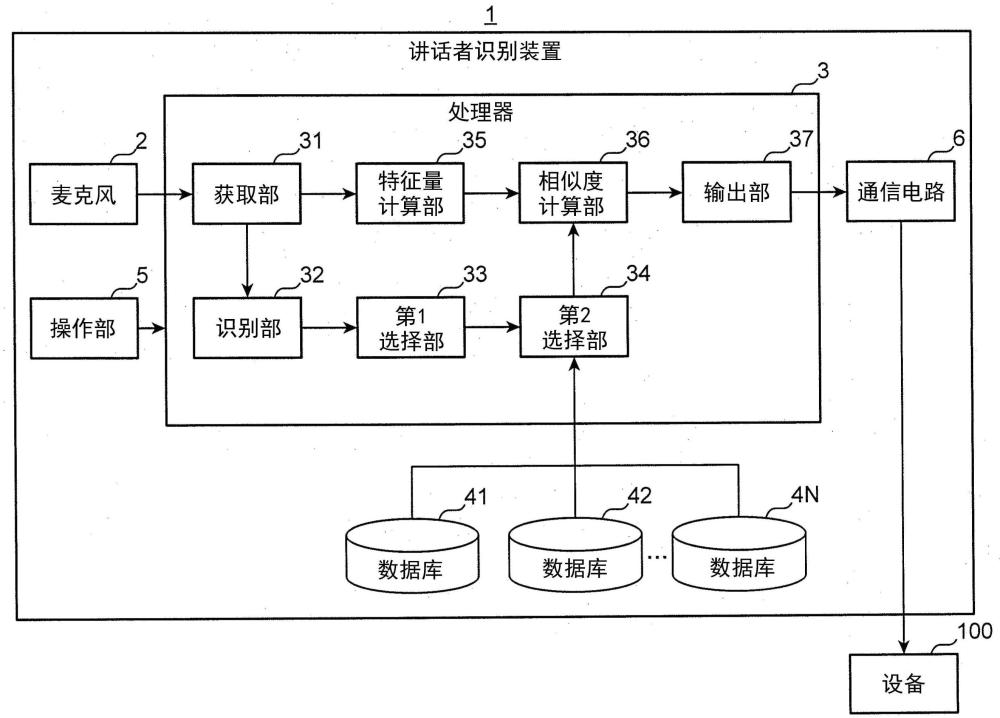
2、本公开的一方式中的讲话者识别方法是识别不特定讲话者的讲话者识别装置中的讲话者识别方法,所述讲话者识别方法包括:获取作为不特定讲话者发出的发声数据的输入发声数据,对所述输入发声数据进行声音识别,从预先决定的多个注册发声内容之中,选择与所述声音识别的结果表示的识别发声内容最接近的注册发声内容作为选择发声内容,从与所述多个注册发声内容对应的多个数据库之中,选择与所述选择发声内容对应的数据库,各数据库存储注册讲话者发出注册发声内容时的所述发声数据的特征量,计算所述输入发声数据的特征量与存储在所选择的数据库的特征量的相似度,基于所述相似度来识别所述不特定讲话者,并输出识别结果。
3、根据本公开,即便不特定讲话者的发声内容与预先注册的注册讲话者的发声内容不一致,也能够识别不特定讲话者。
技术特征:1.一种讲话者识别方法,为讲话者识别装置中的讲话者识别方法,所述讲话者识别方法中,
2.根据权利要求1所述的讲话者识别方法,其中,
3.根据权利要求1或2所述的讲话者识别方法,其中,
4.根据权利要求1所述的讲话者识别方法,其中,
5.根据权利要求1所述的讲话者识别方法,其中,
6.根据权利要求4或5所述的讲话者识别方法,其中,
7.根据权利要求4或5所述的讲话者识别方法,其中,
8.根据权利要求4或5所述的讲话者识别方法,其中,
9.根据权利要求5所述的讲话者识别方法,其中,
10.根据权利要求9所述的讲话者识别方法,其中,
11.一种讲话者识别装置,具备:
12.一种讲话者识别程序,使计算机作为讲话者识别装置发挥功能,所述讲话者识别程序使所述计算机执行以下处理:
技术总结讲话者识别装置(1)对输入发声数据进行声音识别,从预先决定的多个注册发声内容之中,选择与声音识别的结果表示的识别发声内容最接近的注册发声内容作为选择发声内容,从与多个注册发声内容对应的多个数据库(41、42、……、4N)之中选择与选择发声内容对应的数据库,计算输入发声数据的特征量与存储在所选择的数据库(4)的特征量的相似度,基于相似度来识别所述不特定讲话者,并输出识别结果。技术研发人员:釜井孝浩,土井美沙贵,大毛胜统,板仓光佑受保护的技术使用者:松下电器(美国)知识产权公司技术研发日:技术公布日:2024/2/1本文地址:https://www.jishuxx.com/zhuanli/20240618/21311.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。