基于语音全局声学特征和局部频谱特征的情绪识别方法
- 国知局
- 2024-06-21 10:41:59
本发明属于驾驶员情绪识别,特别是涉及到一种基于语音的全局声学特征与局部频谱特征融合的驾驶员情绪识别方法。
背景技术:
1、驾驶车辆是一项复杂的任务,驾驶员必须应对不同的任务,每一项任务又是一个复杂的认知过程;情绪是一个影响认知功能的关键因素,而驾驶员无法控制情绪已被确定为事故的主要原因之一。驾驶员的情绪影响驾驶性能,与交通事故密切相关。负面情绪驾驶不仅会影响正常的道路交通秩序,还会威胁驾驶员和其他交通参与者的身心健康和人身安全,亟需提出一套实时监测驾驶员的情绪识别方法,能够实时准确的识别驾驶员情绪,对提升我国的道路安全状况具有重要的意义。
2、目前,驾驶员的情绪识别主要通过分析驾驶员的生理信号、面部表情、身体姿势、语音信号等情绪表情来实现。驾驶员面部表情情绪识别,需要装载车端摄像头采取驾驶员面部表情数据,对视频数据进行图像识别,进而判别驾驶员的情绪,但是此方法易受光照、面部遮挡以及驾驶员自身掩饰的影响,导致识别的可靠性难以保证。通过驾驶员的生理信号进行情绪识别,采集信号稳定性差,且往往需要佩戴侵入式设备进行数据采集,影响驾驶员的正常驾驶行为。相比之下,驾驶员语音信号具有易于采集、低入侵、不易侵犯隐私等优点。且目前对于驾驶员的语音情绪识别研究较少,较多都是纯理论层面,并未考虑实际驾驶环境的复杂性。此外,随着人机交互的迅速普及,通过驾驶员的声音识别情绪,具有广泛的应用潜力。
3、因此,现有技术亟需一种新的技术方案来解决上述问题。
技术实现思路
1、本发明所要解决的技术问题是:提供基于语音全局声学特征和局部频谱特征的情绪识别方法,通过全局声学特征和局部频谱特征的融合来实时识别驾驶员的情绪;解决了单一模态语音下驾驶员情绪识别准确率不够精准、对于驾驶环境下语音嘈杂缺乏有效区分的问题。
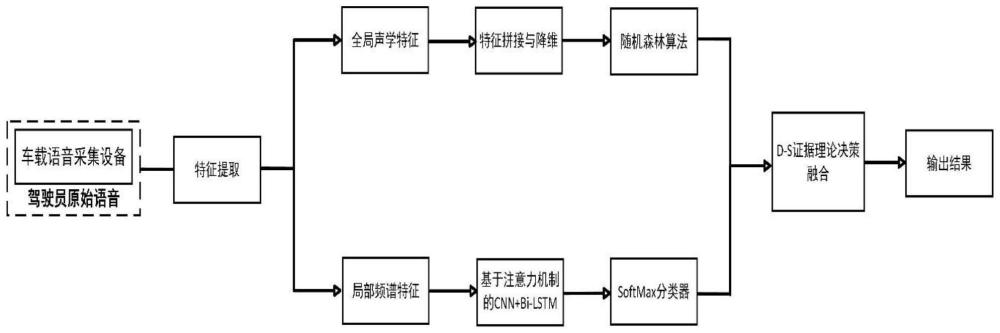
2、基于语音全局声学特征和局部频谱特征的情绪识别方法,包括以下步骤,且以下步骤顺次进行:
3、步骤一、采用车载语音收集设备实时采集驾驶员的原始音频,通过音频降噪模块与音频切割模块对原始音频进行语音降噪、语音切割,获得用于模型输入的目标音频;
4、步骤二、将所述步骤一获得的目标音频进行预处理,包括对目标音频进行预加重、分帧加窗以及端点检测;
5、步骤三、对预处理后的目标音频进行特征提取,提取全局声学特征和局部频谱特征;
6、步骤四、将提取的全局声学特征进行拼接融合,特征降维后,利用随机森林算法进行情绪识别,输出情绪种类的概率;
7、步骤五、将提取的局部频谱特征输入到融合注意力机制的bi-lstm双向长短时记忆网络和卷积神经网络模型中,利用softmax分离器输出情绪种类的概率;
8、步骤六、将随机森林分类器和softmax分离器输出的情绪种类的概率利用d-s证据理论进行决策融合,输出驾驶员的最终情绪状态。
9、所述步骤一音频降噪模块采用小波变换法去除语音信号中的环境噪声,保留原始语音。
10、所述步骤一音频切割模块采用2s窗口截断整个语音,将其划分为一系列的音频片段,并在每个子段之间设置1s重叠,不足2s的音频用零填充。
11、所述步骤二采用一阶fir高通数字滤波器实现目标音频预加重;采用可移动的有限长度窗口进行加权的方法实现分帧加窗;采用基于短时能量ste和短时平均过零率zcr双门限法进行语音信号的端点检测。
12、所述步骤三全局声学特征包括:mfcc系数、共振峰参数、短时平均能量、短时平均过零率以及基频。
13、所述步骤四随机森林模型将数据集划分为训练集和测试集,通过交叉验证依次选择随机森林的criterion参数、决策树的个数、决策树的最大深度、分割内部节点所需要的最小样本数、每棵树用到的最大特征数,对所获得的参数附近进行小范围网格搜索,排除各个参数之间的相互影响,得到最优的模型参数组合;构建高识别性能的基于语音的全局声学特征与局部频谱特征融合的驾驶员情绪识别模型,模型输出驾驶员的情绪种类概率。
14、所述步骤五提取的局部频谱特征为对数梅尔频谱图,作为bi-lstm的输入层,将图像解析为输入张量矩阵。
15、所述步骤六d-s证据理论进行决策融合的规则为:
16、
17、式中,m1(a)表示随机森林分类器对命题a的支持程度,即基本概率数;m2(a)表示softmax分类器对命题a的支持程度;
18、k表示归一化常数:
19、
20、式中,a表示合成后输出结果,b表示随机森林分类器输出的结果,c表示softmax分类器输出结果。
21、通过上述设计方案,本发明可以带来如下有益效果:
22、1、本发明提出的基于语音的全局声学特征与局部频谱特征融合的驾驶员情绪识别模型,可以对驾驶环境下驾驶员的情绪进行精准识别,对于驾驶安全的风险预警和安全决策具有重要意义;
23、2、基于全局声学特征与局部频谱特征融合的方法,这是两种不同类型的特征,它们位于各自的特征空间之中,从不同的方面描述了语音信号中包含的情绪信息。因此,这两种特征之间存在着一定的互补性,更加充分地挖掘语音中的情绪信息,解决了单一模态语音下驾驶员情绪识别准确率不够精准、对于驾驶环境下语音嘈杂缺乏有效区分的问题,通过驾驶员语音实时监测驾驶员的情绪,并准确的识别驾驶员情绪提供重要的理论和技术支持。
技术特征:1.基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:包括以下步骤,且以下步骤顺次进行:
2.根据权利要求1所述的基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:所述步骤一音频降噪模块采用小波变换法去除语音信号中的环境噪声,保留原始语音。
3.根据权利要求1所述的基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:所述步骤一音频切割模块采用2s窗口截断整个语音,将其划分为一系列的音频片段,并在每个子段之间设置1s重叠,不足2s的音频用零填充。
4.根据权利要求1所述的基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:所述步骤二采用一阶fir高通数字滤波器实现目标音频预加重;采用可移动的有限长度窗口进行加权的方法实现分帧加窗;采用基于短时能量ste和短时平均过零率zcr双门限法进行语音信号的端点检测。
5.根据权利要求1所述的基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:所述步骤三全局声学特征包括:mfcc系数、共振峰参数、短时平均能量、短时平均过零率以及基频。
6.根据权利要求1所述的基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:所述步骤四随机森林模型将数据集划分为训练集和测试集,通过交叉验证依次选择随机森林的criterion参数、决策树的个数、决策树的最大深度、分割内部节点所需要的最小样本数、每棵树用到的最大特征数,对所获得的参数附近进行小范围网格搜索,排除各个参数之间的相互影响,得到最优的模型参数组合;构建高识别性能的基于语音的全局声学特征与局部频谱特征融合的驾驶员情绪识别模型,模型输出驾驶员的情绪种类概率。
7.根据权利要求1所述的基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:所述步骤五提取的局部频谱特征为对数梅尔频谱图,作为bi-lstm的输入层,将图像解析为输入张量矩阵。
8.根据权利要求1所述的基于语音全局声学特征和局部频谱特征的情绪识别方法,其特征是:所述步骤六d-s证据理论进行决策融合的规则为:
技术总结基于语音全局声学特征和局部频谱特征的情绪识别方法,属于驾驶员情绪识别技术领域,通过车载语音收集设备获取驾驶员的原始音频,对原始音频进行语音降噪、语音切割后预处理,提取全局声学特征和局部频谱特征,并进行拼接融合,特征降维,利用随机森林算法进行全局声学特征情绪识别,输出情绪种类的概率;利用SoftMax分离器输出局部频谱特征情绪种类的概率;将两种情绪种类的概率利进行决策融合,最终输出驾驶员的情绪状态。本发明解决了单一模态语音下驾驶员情绪识别准确率不够精准、对于驾驶环境下语音嘈杂缺乏有效区分的问题,通过驾驶员语音实时监测驾驶员的情绪,并准确的识别驾驶员情绪提供重要的理论和技术支持。技术研发人员:孙文财,江威,李世武,刘雨薇,王鑫,刘馨泽,马慧慧受保护的技术使用者:吉林大学技术研发日:技术公布日:2024/2/1本文地址:https://www.jishuxx.com/zhuanli/20240618/21301.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表