基于LORA微调辅助的语音唤醒快速自适应方法与流程
- 国知局
- 2024-06-21 10:41:49
本发明涉及语音识别,具体是涉及一种基于lora微调辅助的语音唤醒快速自适应方法。
背景技术:
1、语音唤醒(kws,keyword spotting),指通过语音(指定词语),唤醒设备。这里的“唤醒”指的是,让设备从待机状态进入工作状态,开始对用户的话语进行监听、识别与回应。现有的语音唤醒系统基本具备了在轻量级设备上实现较高水平的唤醒率与较低水平的误唤醒率,然而面对客户端定制的唤醒词与较为复杂的唤醒场景,现有的语音唤醒模型仍然需要针对性地使用目标数据进行全量数据的微调以达到实际应用的标准。
技术实现思路
1、本发明要解决的技术问题是在语音唤醒领域,针对特定的唤醒词与唤醒场景,现有的语音唤醒解决方案往往采用目标数据进行针对性地全参数微调训练,需要较高的时间与数据成本。
2、为解决上述技术问题,本发明的技术方案如下:基于lora微调辅助的语音唤醒快速自适应方法,包括以下步骤:
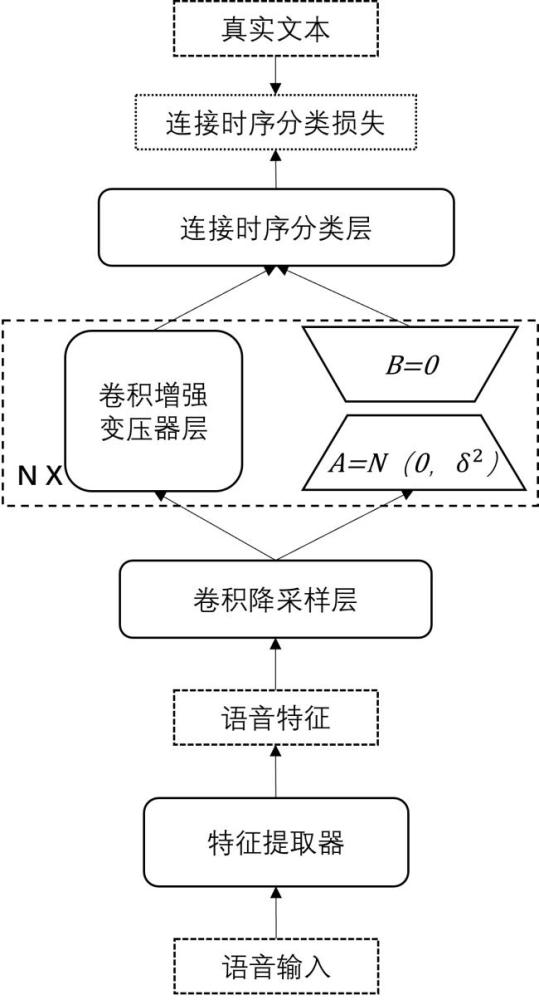
3、s1使用大量通用的语音识别数据训练得到一个通用的音素识别模型,通过所述音素识别模型对输入音频可以进行初步的音素序列分类。
4、进一步地,所述步骤s1中音素识别模型包括:特征提取器、音频编码模块、映射层;
5、所述音频编码模块包括卷积降采样层、卷积增强变压器层(conformer layer)、连接时序分类层(connectionist temporal classification,ctc);
6、所述卷积降采样层是由两层卷积神经网络(convolutional neural network,cnn)模块组成;
7、所述卷积增强变压器层(conformer layer)为多层结构,每一层包括前馈神经网络、多头自注意力模块、卷积模块。
8、语音信号以音素为建模单元,经过音频编码模块的卷积降采样层进行降采样编码并送入到若干层卷积增强变压器层(conformer layer)中进行编码,再将卷积增强变压器层(conformer layer)的输出输入到连接时序分类层(connectionist temporalclassification,ctc)中并输入数据标签来计算连接时序分类层(connectionisttemporal classification,ctc)的损失,最终初步得到识别音素序列的音素序列识别器。
9、s2构建常用的唤醒词数据库,唤醒词数据库覆盖大部分汉语发音,使唤醒词数据混合一定比例s1步骤中的语音识别数据后对音素识别模型进行微调,提高识别模型的唤醒词识别能力,使得语音唤醒模型在常用的短唤醒词领域得以有效提高识别效果。在通用音素识别模型的基础上得到针对唤醒词识别性能较好的唤醒词基础模型。
10、s3基于客户提供的目标唤醒词语料,使用lora训练s2中唤醒词基础模型并进行部分参数微调,使得模型输出快速提高目标关键词唤醒的自适应能力。
11、进一步地,所述使用lora训练的方案进行模型的一部分参数微调的步骤为:
12、s3-1从s2中得到的唤醒词基础模型中提取卷积增强变压器层的权重矩阵;
13、s3-2从中初始化lora模型参数,基于提取低秩分解矩阵来表示参数更新,即:
14、
15、其中,a为降维矩阵,b为升维矩阵,;lora模型训练初始化时,a采用高斯分布初始化,b初始化为全0,保证训练开始时旁路为0矩阵;
16、s3-3使用少量客户指定的目标唤醒词语料进行lora模型训练,在训练过程中数据经过卷积降采样层降采样后分别与原有的卷积增强变压器层、lora模块的参数矩阵相乘,相乘后的两组矩阵重新相加在一起输入下一个训练模块,其中卷积增强变压器层的参数完全冻结,视任务情况选取lora矩阵的秩(r=1,2,4,8),在计算训练损失后仅更新降维矩阵a和升维矩阵b的参数;
17、s3-4完成lora模块训练后,在实际的推理过程中实际数据同样经过卷积降采样层降采样后分别与原有的卷积增强变压器层、已训练的lora模块的参数矩阵相乘,相乘后的两组矩阵重新相加在一起输入至下一个推理模块并最终完成唤醒词的预测与判定。
18、步骤s3中基于客户的唤醒需求,利用客户提供的少量唤醒语料,构建一个lora模型,具体表现为: 对s1步骤中的音频编码模块中的卷积增强变压器层注入低秩分解矩阵:训练时,原模型固定,只训练低秩分解矩阵的降维矩阵a和升维矩阵b;推理时,将b、a加到原参数上,不引入额外的推理延迟。
19、s4根据客户提供的目标唤醒词语料中列表,构建处理识别结果的热词模块,使用热词增强唤醒词匹配,进一步提高目标关键词唤醒的准确率。
20、与现有技术相比,本发明的有益效果体现在:本发明的方法通过利用lora辅助训练的方法帮助语音唤醒模型在现有唤醒水平的基础上依照客户的具体唤醒词与唤醒环境的需求,利用少量的目标域数据进行快速高效的模型微调训练,使得模型可以在短时间内适应目标域的实际应用场景,在短时间低成本内实现唤醒模型的实际应用效果的提升。
技术特征:1.基于lora微调辅助的语音唤醒快速自适应方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于lora微调辅助的语音唤醒快速自适应方法,其特征在于,所述步骤s1中音素识别模型包括:特征提取器、音频编码模块、映射层;
3.根据权利要求1所述的基于lora微调辅助的语音唤醒快速自适应方法,其特征在于,所述步骤s4具体如下:
技术总结本发明公开了基于LORA微调辅助的语音唤醒快速自适应方法,通过训练得到一个通用的音素识别模型,对输入音频进行初步的音素序列分类;并在唤醒词通用训练集上对音素识别模型进行微调,快速提高识别模型的唤醒词识别能力;进一步地,基于客户提供的目标唤醒词语料,使用LORA训练的方法进行模型的部分参数微调,使得模型快速提高目标关键词唤醒的自适应能力。本发明在现有唤醒水平的基础上依照客户的具体唤醒词与唤醒环境的需求,利用少量的目标域数据进行快速高效的模型微调训练,使得模型可以在短时间内适应目标域的实际应用场景,在短时间低成本内实现唤醒模型的实际应用效果的提升。技术研发人员:张昭,王宇光,王龙标受保护的技术使用者:慧言科技(天津)有限公司技术研发日:技术公布日:2024/2/1本文地址:https://www.jishuxx.com/zhuanli/20240618/21275.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表