一种段落语音合成建模及段落语音合成方法
- 国知局
- 2024-06-21 10:43:47
本发明涉及语音合成领域,尤其是一种段落语音合成建模及段落语音合成方法。
背景技术:
1、语音合成(text-to-speech,tts)是一种将文字转换为人类所说的语音的技术手段,被广泛的应用在有声读物、虚拟形象、户外语音播报、各种智能语音助手等场景中。
2、得益于神经网络的发展,目前的tts模型大大提高了单句合成语音的自然度。然而,在有声读物等某些领域,需要表达段落中句与句之间的情感和风格变化,以生成自然和富有表现力的高质量段落语音,带来良好的听觉体验。
3、但当前文本到语音合成研究很少关注段落语音合成。对于单句表现力语音合成研究,为了获得声学特征一致且连续的语音,早期的一些工作将语音片段拼接在一起,并对音高、时长和能量进行后期调整。例如,masked speech通过前后的mel谱特征预测当前句子的mel谱特征。这样做的好处是最终拼接的单句语音在声学特征上是一致的,但推理中不可见的未来信息导致了训练和推理之间的不匹配。另一项工作para tts利用上下文信息预测了整个段落的语音风格,从而合成出具有连贯特征的段落语音。然而,这种方法只在音素层添加了条件,忽略了情感和风格变化。
4、一些研究如hiertts表明,以语法结构的形式引入语言信息比直接引入语言信息更有助于对情感和风格进行建模。然而,这些研究要么需要提取额外的先验特征,要么受限于分层变异自动编码器(hvae)的后验崩溃问题。
技术实现思路
1、有鉴于此,本发明的主要目的在于提供一种段落语音合成建模及段落语音合成方法,使得模型能更好地捕获段落和句子级别的语音信息,进而实现在单次推理中生成自然和富有表现力的高质量段落语音。
2、为达到上述目的,一方面,本申请提供了一种段落语音合成建模方法,包括:
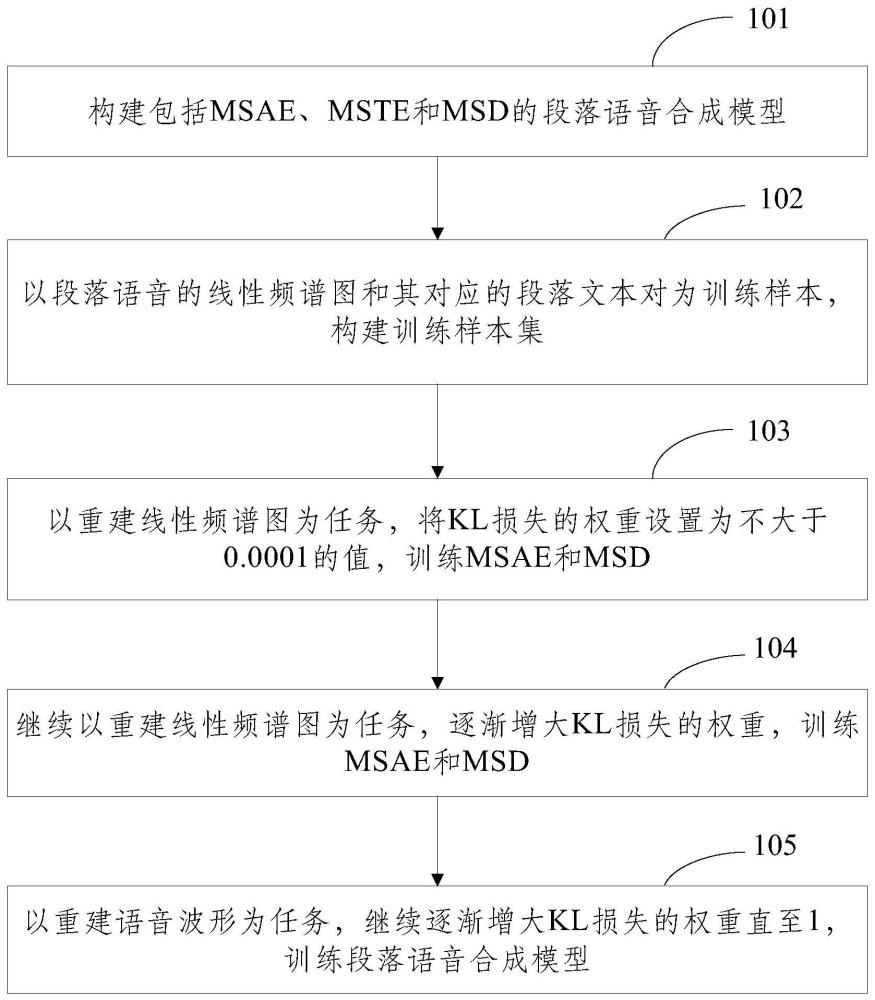
3、构建包括多步骤后验编码器msae、多步骤先验编码器mste和多步骤解码器msd的段落语音合成模型;
4、以段落语音的线性频谱图和其对应的段落文本对为训练样本,构建训练样本集;
5、以重建线性频谱图为任务,将kl损失的权重设置为不大于0.0001的值,训练msae和msd;
6、继续以重建线性频谱图为任务,逐渐增大kl损失的权重,训练msae和msd;
7、以重建语音波形为任务,继续逐渐增大kl损失的权重直至1,训练段落语音合成模型。
8、在一个可能的实现中,所述训练为采用多周期判别器和多分辨率判别器进行对抗性训练,训练的总损失表示为:
9、ltot=αglg+αs1ls1+αs2ls2+ckllkl+αald
10、其中,lg为对抗训练的损失,αg为lg的权重;ls1为线性频谱图的重建损失,αs1为ls1的权重;ls2为语音波形重建损失,αs2为ls2的权重;ld为计算真实的音素持续时间和预测的音素持续时间之间的均方误差,αd为ld的权重;lkl为kl损失,αkl为lkl的权重。
11、在另一个可能的实现中,所述以重建线性频谱图为任务训练,总损失中,αg=0,αs2=0。
12、在另一个可能的实现中,所述以重建语音波形为任务训练,总损失中,αs1=0。
13、在另一个可能的实现中,对任一对训练样本,包括:
14、msae,对段落语音的线性频谱图逐步下采样,获得各语法层级的包含情感和风格信息的音频信息,分别编码成各语法层级的后验潜在变量;
15、mste,由高语法层级至低语法层级,通过前一语法层级的后验潜在变量和先验潜在变量,以及本语法层级的段落文本信息,预测本语法层级的先验潜在变量的均值和方差;
16、msd,上采样前一语法层级的隐变量,与本语法层级先验潜在变量组合,作为本语法层级的隐变量;依据帧级的隐变量分别重构线性频谱图和语音波形。
17、在另一个可能的实现中,所述语法层级由低至高分别为:帧层、音素层、词层、句子层和段落层;帧层的段落文本信息为空值;音素层的段落文本信息,为从段落文本的音素序列提取的音素级表征;词层的段落文本信息,为从段落文本提取的语义向量表征,以及下采样音素级表征获得的词级表征的组合;句子层和段落层的段落文本信息,均通过下采样前一语法层级的段落文本信息获得。
18、在另一个可能的实现中,所述kl损失为各语法层级先验潜在变量和后验潜在变量之间的kl距离的加权和,由低语法层级至高语法层级权重逐层减小。
19、另一方面,本申请还提供了一种段落语音合成方法,包括:
20、将待合成的段落文本输入段落语音合成模型;
21、由高语法层级至低语法层级,通过前一语法层级的先验潜在变量,以及本语法层级的段落文本信息,预测本语法层级的先验潜在变量的均值和方差;
22、上采样前一语法层级的隐变量,与本语法层级先验潜在变量组合,作为本语法层级的隐变量;依据帧级隐变量重构语音波形。
23、基于上述,本发明提供的一种段落语音合成建模及段落语音合成方法,具有以下优点和特点:
24、1、本申请的训练策略,能够解决以语法结构的形式引入语言信息的语音合成模型,训练时存在的后验崩溃(posterior collapse)问题,使得模型能更好地捕获段落和句子级别的语音信息,还使用了权重退火策略(weight annealing),以确保模型有足够的时间在不受文本约束的情况下从音频中提取信息,进而使得模型能够在单次推理中生成自然和富有表现力的高质量段落语音;
25、2、上采样前一语法层级的先验潜在变量,与本语法层级先验潜在变量组合,作为本语法层级的先验潜在变量,使得帧级特征包含了预测的各语法层级的声学特征,即使用各语法层级特征的组合来生成段落语音,解决了对于语法层次较深的段落语音,递归预测导致的累积误差增加,且高层信息对语音的控制力减弱的问题,进一步提高段落语音合成的质量和表达能力。
技术特征:1.一种段落语音合成建模方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述训练为采用多周期判别器和多分辨率判别器进行对抗性训练,训练的总损失表示为:
3.根据权利要求2所述的方法,其特征在于,所述以重建线性频谱图为任务训练,总损失中,αg=0,αs2=0。
4.根据权利要求2所述的方法,其特征在于,所述以重建语音波形为任务训练,总损失中,αs1=0。
5.根据权利要求1所述的方法,其特征在于,对任一对训练样本,包括:
6.根据权利要求5所述的方法,其特征在于,所述语法层级由低至高分别为:帧层、音素层、词层、句子层和段落层;帧层的段落文本信息为空值;音素层的段落文本信息,为从段落文本的音素序列提取的音素级表征;词层的段落文本信息,为从段落文本提取的语义向量表征,以及下采样音素级表征获得的词级表征的组合;句子层和段落层的段落文本信息,均通过下采样前一语法层级的段落文本信息获得。
7.根据权利要求5所述的方法,其特征在于,所述kl损失为各语法层级先验潜在变量和后验潜在变量之间的kl距离的加权和,由低语法层级至高语法层级权重逐层减小。
8.一种段落语音合成方法,其特征在于,包括:
技术总结本发明涉及一种段落语音合成建模方法,所述方法包括:构建包括MSAE、MSTE和MSD的段落语音合成模型;以段落语音的线性频谱图和其对应的段落文本对为训练样本,构建训练样本集;以重建线性频谱图为任务,将KL损失的权重设置为不大于0.0001的值,训练MSAE和MSD;继续以重建线性频谱图为任务,逐渐增大KL损失的权重,训练MSAE和MSD;以重建语音波形为任务,继续逐渐增大KL损失的权重直至1,训练段落语音合成模型。还涉及了一种段落语音合成方法。本发明的方法,能够在单次推理中生成自然和富有表现力的高质量段落语音。技术研发人员:尚增强,李绪源,王丽,张鹏远受保护的技术使用者:中国科学院声学研究所技术研发日:技术公布日:2024/2/1本文地址:https://www.jishuxx.com/zhuanli/20240618/21380.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表