一种实时连麦环境下的动态声音过滤和分类系统、方法及存储介质与流程
- 国知局
- 2024-06-21 11:31:28
本发明涉及动态声音过滤和分类,主要涉及一种实时连麦环境下的动态声音过滤和分类系统、方法及存储介质。
背景技术:
1、实时连麦(real-timeco-broadcasting)技术通常允许多个用户同时进行在线语音或视频通话,这是多人交互直播环境的基础。然而,在这种环境下,背景噪音和多用户声音的混合往往造成识别和交流困难。因此,动态声音过滤(dynamic audio filtering)和声纹识别(voiceprint recognition)的技术应用变得尤为关键。动态声音过滤能实时剔除或降低不需要的背景噪音或其他干扰因素,以优化用户体验。声纹识别则通过分析每个用户的声学特征(acoustic features)进行身份识别和声音分离。
2、目前,现有的解决方案可采用一种多人实时语音通讯系统,该系统主要依赖于高斯混合模型(gaussian mixture model,gmm)和快速傅里叶变换(fast fouriertransform,fft)为核心算法进行操作。在这个系统中,高斯混合模型用于声纹识别,其工作原理是对每个参与者的声音进行特征提取,并通过训练一个高斯混合模型来进行声纹匹配,从而区分不同的语音来源。此外,该系统还使用快速傅里叶变换进行噪声消除,其主要思路是通过在频域对声音信号进行分析,筛选出主要的语音频率,而抑制噪声频率。这一系列操作在一定程度上实现了在多人实时语音通讯环境中对各参与者的声音进行区分和过滤,以便提供一个相对清晰的语音通讯环境。但是,在现有技术体系中,虽然采用了高斯混合模型和快速傅里叶变换以实现多人实时语音通讯环境中的声纹识别和噪声过滤,尽管该方案在基本的应用场景中表现得相对可靠,但它存在几个明显的缺点和局限性:
3、首先,该方案主要依赖于传统的声纹识别和噪声消除算法,对于实时、动态变化的声音环境适应性较弱;特别是在多人连麦、高噪环境或者多声源重叠的情况下,其声纹识别的准确性和噪声过滤的效果都明显受到影响。
4、其次,该方案的计算复杂度相对较高,特别是在需要快速、实时处理的场景下,无法满足性能要求。另外,高斯混合模型对于训练数据的质量和量都有较高的要求,这在多样化和多变的实际应用环境中是一大制约因素。
5、此外,现有方案也没有充分利用现代深度学习或其他先进的机器学习算法,这意味着它在处理复杂语音模式和动态环境时的性能较为有限。例如,现有方案在处理不同口音、语速或者人声混合时,往往会出现识别错误或漏检,影响用户体验。
6、综上所述,现有技术方案在多人实时语音通讯环境中表现出准确性不足、适应性差和计算效率低下等多个方面的缺点。因此,有必要提出一种新的解决方案,通过引入更先进的声学模型和机器学习算法,以提高声纹识别的准确性和系统的整体性能,特别是在复杂和动态变化的声音环境中。
7、需要说明的是,上述内容属于发明人的技术认知范畴,由于本领域的技术内容浩如烟海、过于庞杂,因此本技术的上述内容并不必然构成现有技术。
技术实现思路
1、本发明提供一种实时连麦环境下的动态声音过滤和分类系统、方法及存储介质,用以解决现有技术方案在多人实时语音通讯环境中表现出准确性不足、适应性差和计算效率低下等多个方面的缺点。
2、为了实现上述目的,本发明采用以下技术方案:本发明的一种实时连麦环境下的动态声音过滤和分类系统,包括
3、声音输入捕获模块,用于进行声音捕获,收集音频数据;
4、多通道缓冲模块,用于对收集到的音频数据流进行时间戳标记和缓冲,高效地管理来自多个用户或音频源的音频数据;
5、音频预处理模块,通过综合使用低通、高通和带通滤波器,对进入系统的音频数据进行初步清理,滤除不需要的噪声和干扰;
6、动态声音分类模块,用于识别基础的声音事件并对其进行细分,提供高精度的声音分类;
7、环境噪音剔除模块,通过突出来自目标方向的声音,而减小其他方向的声音和噪音,用于高效地剔除来自多方向的复杂环境噪音;
8、语音识别与优化模块,通过对语音信号的不同频率成分进行不同程度的增强或衰减,有效地提取和增强语音中的关键特性;
9、多用户语音合成模块,用于处理和合成多个语音信号,将多个用户的处理后的音频合成为一个统一的音频流;
10、音频输出编码模块,用于进行音频编码,优化音频流的质量,可在不同网络环境和设备限制下提供最优的音频质量;
11、实时传输与播放模块,通过动态调度和缓冲区优化,用于进行音频传输和播放;
12、用户反馈与自适应调整模块,用于捕捉用户的反馈,系统根据用户反馈和实时环境对自身实时地进行适应化调整。
13、优选的,所述声音输入捕获模块的算法公式如下:
14、
15、其中,ttotal是整个音频捕获和缓冲过程的总时间,n是用户或音频源的数量,tcapture,i是第i个音频源的音频捕获时间,tbuffer,i是第i个音频源的音频缓冲时间;
16、在实时多用户环境下,每个用户端都装备有一套高精度的麦克风阵列和声音捕获单元,这些单元能够以高采样率和高位深进行声音捕获;
17、所述多通道缓冲模块的算法公式如下:
18、
19、其中,balloc是分配给整个缓冲池的总内存大小,binit是初始缓冲区大小,n是音频源数量,ri是第i个音频源的数据流速率,ti是该音频源产生的最长延迟时间;
20、算法首先根据预设参数和实时网络状况动态计算出每个音频源需要的缓冲区大小,并据此初始化循环缓冲池;当音频数据流进入系统后,首先进行时间戳标记和缓冲;然后数据被路由到对应的循环缓冲区中,每当缓冲区达到一定填充程度,缓冲管理算法就会触发,动态重新分配缓冲区空间,以适应的数据峰值或网络波动;
21、所述音频预处理模块的算法公式如下:
22、h(f)=hlpf(f)×hhpf(f)×hbpf(f)
23、其中,h(f)是总的滤波函数,hlpf(f)、hhpf(f)和hbpf(f)分别是低通、高通和带通滤波器的传递函数,这些传递函数的具体形式和参数由音频的实时特性动态调整;
24、算法首先是通过快速傅里叶变换对音频信号进行频谱分析;接下来基于声音场景的先验知识和实时声音特性,算法动态调整每个滤波器的参数;经过参数调整后,音频数据流通过低通、高通和带通滤波器进行处理;最后,处理过的音频数据被送到后续模块进行更进一步的处理。
25、优选的,所述动态声音分类模块采用了一种基于预先训练的深度学习模型的创新算法——“实时声音事件识别和多级分类器”,其算法公式如下:
26、p(y∣x)=softmax(w×relu(h×x+b1)+b2)
27、其中,x为音频特征向量,p(y∣x)是给定输入x时,声音事件y的条件概率,w和h是网络权重矩阵,b1和b2是偏置向量,relu是激活函数;
28、模型第一层是一系列卷积层和池化层,用于提取音频数据的时频特性;这些特性然后被输入到一个或多个长短时记忆层中,以捕捉声音事件的时间依赖性;这些长短时记忆层的输出被用作全连接层和softmax分类器的输入,后者最终输出声音事件的预测标签及其相应的概率分布。
29、优选的,所述环境噪音剔除模块采用了一种先进的自适应降噪算法——“实时复杂环境降噪引擎”,该算法基于波束成形和谱减法,能有效地剔除来自多方向的复杂环境噪音,其算法公式如下:
30、
31、y(f)=x(f)-α·n(f)
32、其中,x(f)表示各个方向加权后的混合音频信号在频域的表示,wn(f)是第n个方向上的加权系数,sn(f)是第n个方向上的音频信号,y(f)是降噪后的音频信号,n(f)是估计的噪音信号,α是谱减法中的一个系数;
33、算法首先使用一组多个麦克风捕获环境音频,然后通过一个波束成形器将这些多通道音频数据进行方向性加权和,以便突出来自目标方向的声音,而减小其他方向的声音和噪音;波束成形后的音频数据然后被送入一个谱减法模块,该模块用于准确地估算和剔除残留的背景噪音。
34、优选的,所述语音识别与优化模块采用了一种“语音特性提取与平衡引擎”的先进算法,该算法基于谱分解和动态范围压缩技术,其算法公式如下:
35、vout(f)=γ(f)·vin(f)
36、
37、其中,vout(f)和vin(f)分别代表处理后和处理前的人声信号在频域上的表示,γ(f)是一个频率响应因子,k是控制曲线斜率的常数,μ是平衡点;
38、算法首先通过一个傅里叶变换模块将时域上的人声信号转换到频域;然后,通过一个动态范围压缩模块对这个频域信号进行处理,在各个频段内分别压缩动态范围,以便增强语音的某些关键特性;即通过适应性地调整γ(f)参数,对语音信号的不同频率成分进行不同程度的增强或衰减;最后,处理后的频域信号通过一个逆傅里叶变换模块转换回时域,然后输出到实时连麦环境中。
39、优选的,所述多用户语音合成模块采用了一种多维自适应权重合成算法,其算法公式如下:
40、
41、
42、其中,sout(t)是输出音频流的时域表示,是第i个用户的输入音频流,αi(t)是第i个用户的时变权重系数,xi(t)是第i个用户的音频特性向量,β是一个用于控制权重分布的参数;
43、算法首先提取每个用户音频流的特性向量xi(t),然后,通过一个基于深度学习的权重生成器,计算每个用户在不同时间t下的权重系数αi(t);最后,这些权重系数用于加权合成各个用户的音频流,生成最终的输出音频流sout(t)。
44、优选的,所述音频输出编码模块的算法公式如下:
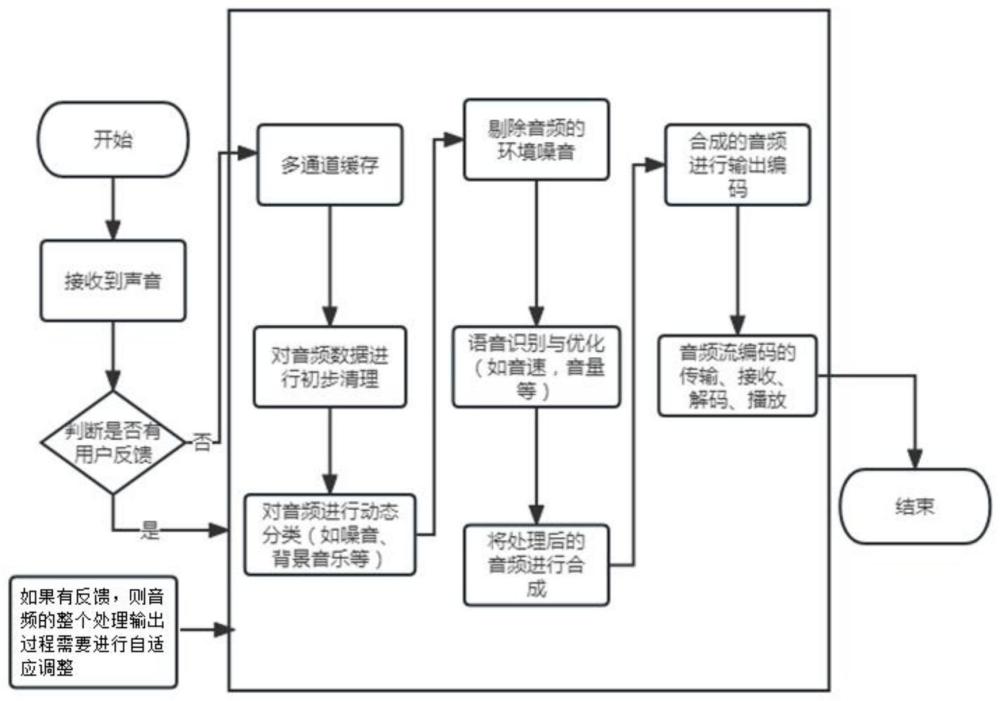
45、eout=f(sout,λ,q)
46、其中,eout为编码输出流,f是编码函数,sout是合成后的音频流,λ是自适应参数向量,q是质量控制参数;
47、在运行时,算法通过检测当前的网络带宽和设备限制,以及通过用户行为分析来收集的用户偏好,实时地调整λ,这样,编码函数f可以根据λ的变化自适应地调整编码比特率、编码层次和其他参数;
48、所述实时传输与播放模块的算法公式如下:
49、ttrans=f(eout,d,b,l)
50、其中,ttrans表示音频数据包从发送端到接收端的总传输时间,f是总体的传输函数,eout是编码后的音频输出流,d是网络延迟,b是客户端缓冲区大小,而l是音频流的总长度;
51、该算法的核心之处在于动态调度和缓冲区优化,动态调度主要通过深度学习模型来预测网络延迟d,然后根据预测结果动态地调整数据包的发送速度和编码率;缓冲区优化则是通过智能地管理客户端缓冲区b来实现的,会根据实时的网络状态和用户行为动态地调整缓冲区大小,以便在不牺牲播放流畅性的前提下,尽减少缓冲和加载时间。
52、优选的,所述用户反馈与自适应调整模块采用了一种基于强化学习与模糊逻辑的自适应优化算法——“用户反馈强化自适应机制”,其算法公式如下:
53、usi=w1·psmooth+w2·qaudio+w3·bbuffer
54、其中,usi为“用户满意度指标”的量化参数,是一个介于0和1之间的值;w1,w2,w3是权重系数,而psmooth,qaudio,bbuffer分别是播放流畅度、音质和缓冲次数的量化值;
55、该算法使用了一个强化学习模型来实时地优化各个参数和设置;该模型以usi作为奖励信号,以各种的动作作为状态空间,并使用q-learning算法来找出最优策略;这一机制允许系统根据用户反馈和实时环境自动地进行调整,以最大化usi;另外还引入了模糊逻辑来处理不确定和模糊的用户反馈,模糊逻辑可用于将用户的主观反馈转换为可量化的usi子指标;通过综合应用强化学习和模糊逻辑,该算法不仅能准确地捕捉并量化用户体验,还能实时地进行自适应优化。
56、本发明的一种实时连麦环境下的动态声音过滤和分类方法,所述方法应用于上述的实时连麦环境下的动态声音过滤和分类系统,所述实时连麦环境下的动态声音过滤和分类方法的步骤如下:
57、系统接收到声音后,首先判断是否有用户的反馈;
58、若没有检测到用户的反馈,系统将按照正常的处理流程对接收到的音频进行处理;先将音频数据进行多通道缓存,并对音频数据进行初步清理,接着对音频进行动态分类,再剔除音频的环境杂音,并对音频进行语音识别与优化,然后将处理后的音频进行合成,将合成的音频进行输出编码,最后进行音频流编码的传输、接收、解码、播放;
59、若有检测到用户的反馈,系统将反馈转换成用户满意度指标usi的子指标;接着,系统根据这些指标对自身进行适应化调整,以改善识别的问题;调整完成后,系统再继续按照正常的处理流程对接收的音频进行处理。
60、本发明的一种存储介质,所述存储介质上存储有计算机程序,该计算机程序被处理器执行时,实现上述的实时连麦环境下的动态声音过滤和分类方法。
61、与现有技术相比,本发明的有益效果是:
62、本发明采用了先进的声纹识别算法、噪声过滤机制以及整体架构设计,通过设置动态声音分类、环境噪音剔除、语音识别与优化、多用户语音合成以及用户反馈与自适应调整等多个模块,从提升声音分类的准确性、优化噪音剔除效率、增强语音识别与处理的质量以及实现系统的自适应性能等方面对方案整体进行优化,其相较于现有技术,具有以下明显的技术优点:
63、一、通过深度神经网络,我们能更精确地进行声纹识别,即使在复杂的声音环境中也能保持高准确率。
64、二、基于注意力机制的噪声过滤和分类算法能适应各种声音环境,无需预先训练或者手动调整参数。
65、三、与基于高斯混合模型和快速傅里叶变换的方案相比,本提案的计算复杂度更低,更适合实时处理。
66、四、本提案的各个组件都设计为模块化,易于与现有的语音通讯平台或应用进行整合。
67、五、由于采用了现代的机器学习算法,本提案具有良好的扩展性,未来可以方便地添加更多的功能或进行性能优化。通过以上改进,不仅解决了现有技术中存在的多个问题,而且在准确性、适应性、计算效率等方面具有明显优势。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22038.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表