基于命令词识别的语音控制方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 11:31:24
本申请涉及语音识别,尤其涉及一种基于命令词识别的语音控制方法、装置、设备及存储介质。
背景技术:
1、命令词识别是语音识别技术的重要方向之一,其一般应用于终端设备的控制或唤醒。命令词识别模型在输入语音较为复杂的情况下,命令词识别模型会出现误识别现象。误识别现象一般包括非命令词误识别为命令词,不同含义的命令词之间的误识别,命令词误识别为非命令词。
2、在现有技术中为避免命令词识别模型出现误识别现象,在命令词识别模型训练时可将损失函数设置为最小化同分类距离与最大化不同分类距离。该损失函数配合距离普通样本较远的正样本和距离普通样本较近的负样本的精选三元组,可有效提高模型在复杂语音场景下的识别准确率。但由于精选三元组的收集过程较为麻烦,需要较长时间才能收集到用于训练模型的样本数据,导致模型的训练效率较低。
技术实现思路
1、本申请提供一种基于命令词识别的语音控制方法、装置、设备及存储介质,以通过普通样本训练模型也可以达到优化模型性能的训练效果,保证模型在复杂语音场景的识别准确率的同时提高模型训练效率,以解决现有技术中模型训练效率低的问题。
2、第一方面,本申请提供了一种基于命令词识别的语音控制方法,包括:
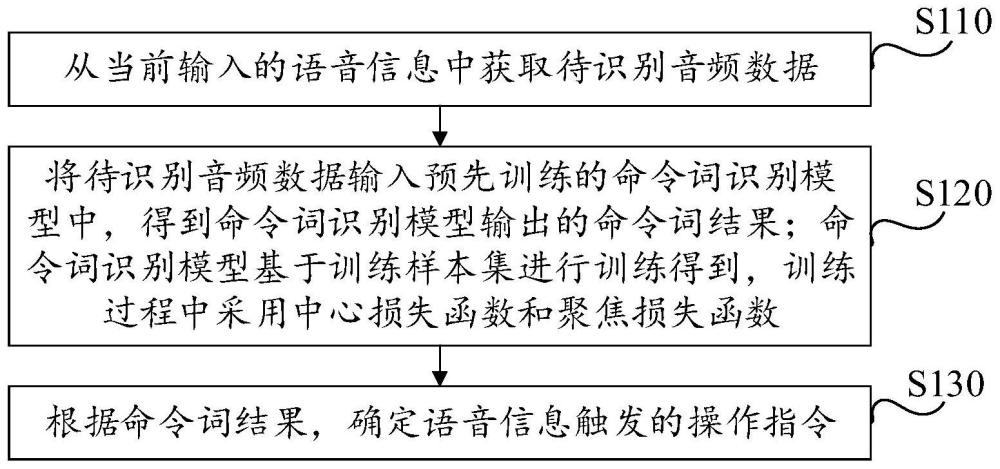
3、从当前输入的语音信息中获取待识别音频数据;
4、将所述待识别音频数据输入预先训练的命令词识别模型中,得到所述命令词识别模型输出的命令词结果;所述命令词识别模型基于训练样本集进行训练得到,训练过程中采用中心损失函数和聚焦损失函数;
5、根据所述命令词结果,确定所述语音信息触发的操作指令。
6、第二方面,本申请提供了一种基于命令词识别的语音控制装置,包括:
7、音频获取模块,被配置为从当前输入的语音信息中获取待识别音频数据;
8、命令词识别模块,被配置为将所述待识别音频数据输入预先训练的命令词识别模型中,得到所述命令词识别模型输出的命令词结果;所述命令词识别模型基于训练样本集进行训练得到,训练过程中采用中心损失函数和聚焦损失函数;
9、操作触发模块,被配置为根据所述命令词结果,确定所述语音信息触发的操作指令。
10、第三方面,本申请提供了一种基于命令词识别的语音控制设备,包括:
11、一个或多个处理器;存储装置,存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的基于命令词识别的语音控制方法。
12、第四方面,本申请提供了一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行如第一方面所述的基于命令词识别的语音控制方法。
13、本申请通过在命令词识别模型的训练过程中采用中心损失函数和聚焦损失函数。中心损失函数可以缩小同类命令词在特征空间的类内距离,因此变相增大了不同类命令词在特征空间的类间距离,使得不同类命令词的特征参数更有区分性,提高命令词识别模型的区分能力。对于一些区分性不明显的难训样本,聚焦损失函数对其赋予较大的权重,对于一些区分性明显的易训样本,聚焦损失函数对其赋予较小的权重,以使得模型训练时更能关注到难训样本的特征参数。聚焦损失函数和中心损失函数联合使用,可缩小包括难训样本在内的同类命令词在特征空间的类内距离,间接增大包括难训样本在内的不同类命令词在特征空间的类间距离,以增大难训样本的特征的区分性,提高命令词识别模型的区分能力,提高命令词识别模型的识别准确率,避免出现误识别现象。通过上述技术手段,训练命令词识别模型时采用普通样本也照样能达到优化模型性能的训练效果,保证模型在复杂语音场景的识别准确率的同时提高模型训练效率,解决了现有技术中模型训练效率低的问题。
技术特征:1.一种基于命令词识别的语音控制方法,其特征在于,包括:
2.根据权利要求1所述的基于命令词识别的语音控制方法,其特征在于,所述命令词识别模型由神经网络、池化层和线性变换层串联组成;
3.根据权利要求1所述的基于命令词识别的语音控制方法,其特征在于,所述命令词识别模型通过如下步骤训练得到:
4.根据权利要求3所述的基于命令词识别的语音控制方法,其特征在于,所述根据所述第一损失值和所述第二损失值,调整所述中心特征参数和所述第一神经网络模型的模型参数,包括:
5.根据权利要求3所述的基于命令词识别的语音控制方法,其特征在于,所述基于聚焦中心损失函数,根据各个所述样本音频数据的第二特征参数和各个命令词类别的中心特征参数,确定第二损失值,包括:
6.根据权利要求5所述的基于命令词识别的语音控制方法,其特征在于,所述基于所述聚焦损失函数,根据所述样本音频数据的第二特征参数和各个命令词类别的中心特征参数,确定所述第四损失值的权重系数,包括:
7.根据权利要求4所述的基于命令词识别的语音控制方法,其特征在于,所述基于正交化损失函数,根据各个所述命令词类别的中心特征参数,确定第三损失值,包括:
8.根据权利要求3所述的基于命令词识别的语音控制方法,其特征在于,在所述将所述训练样本集中的样本音频数据输入第一神经网络模型之前,还包括:
9.根据权利要求3所述的基于命令词识别的语音控制方法,其特征在于,在所述将所述训练样本集中的样本音频数据输入第一神经网络模型之前,还包括:
10.一种基于命令词识别的语音控制装置,其特征在于,包括:
11.一种基于命令词识别的语音控制设备,其特征在于,包括:一个或多个处理器;存储装置,存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如权利要求1-9任一所述的基于命令词识别的语音控制方法。
12.一种包含计算机可执行指令的存储介质,其特征在于,所述计算机可执行指令在由计算机处理器执行时用于执行如权利要求1-9任一所述的基于命令词识别的语音控制方法。
技术总结本申请公开了一种基于命令词识别的语音控制方法、装置、设备及存储介质,涉及语音识别技术领域。本申请提供的技术方案包括:从当前输入的语音信息中获取待识别音频数据;将待识别音频数据输入预先训练的命令词识别模型中,得到命令词识别模型输出的命令词结果;命令词识别模型基于训练样本集进行训练得到,训练过程中采用中心损失函数和聚焦损失函数;根据命令词结果,确定语音信息触发的操作指令。通过上述技术手段,以通过普通样本训练模型也可以达到优化模型性能的训练效果,保证模型在复杂语音场景的识别准确率的同时提高模型训练效率,以解决现有技术中模型训练效率低的问题。技术研发人员:叶珑,雷延强受保护的技术使用者:广州视源电子科技股份有限公司技术研发日:技术公布日:2024/3/4本文地址:https://www.jishuxx.com/zhuanli/20240618/22033.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表