一种音频数据采集和个性化语音训练及推理方法与流程
- 国知局
- 2024-06-21 11:32:25
本发明涉及语音合成,尤其涉及一种音频数据采集和个性化语音训练及推理方法。
背景技术:
1、随着人工智能技术的发展,语音合成尤其是个性化语音合成已取得很大进步。个性化语音合成目前已大量应用在数字人、智能客服和个性化语音导航等领域,为社会带来了很大的经济效益。但是个性化语音合成目前商用的居多,如果一家公司上百人或上千人都需要大量的个性化语音生成,势必会增加企业的经济负担。为了方便企业员工快速生成个人性化语音生成,本发明提供了一个可私有化部署、操作简单、节省gpu服务器资源和能大量进行个性化语音合成的方案。
2、个性化语音合成需要进行个人语音数据的采集,文本对齐、模型训练、模型推理等过程。个人语音数据采集可通过手机、电脑等录音设备进行收集,然后手动打包给到模型人员;也可根据厂商开发的app,用户只需按照给定的文字进行朗读,完毕后用户数据会自动给到厂商,但这样会带来数据泄露问题。文本对齐目前主要有两种方案:一是录音人员给定文本,用户根据文本进行朗读,这种文本与语音对应,忽略了用户可能朗读不准确、漏读或多读的情况,降低了数据质量;二是直接让用户提供30分钟左右的音频,然后使用语音识别算法来进行文字识别,但毕竟识别效果不是100%准确,所以也会造成数据误差,此外模型训练的时候往往需要对长音频进行切片,保持在20s以内,切片的时候也会造成一定的音节泄露。模型训练,可对单说话人和多说话人进行训练,常见的服务上多是单说话人进行训练,如果用户群里比较大,这种训练方式较耗资源。模型推理多是单说话人进行推理,本发明将单说话人推理和多说话人推理都融合进来,提升了个性化语音合成推理的自由度。
3、1个性化语音合成数据采集
4、目前方案缺点包括1)耗时耗力人工录制完语音后,打包发给模型开发人员进行质量检测,若不合格还需重新录制;2)有数据泄露风险通过厂商软件录制,可保证录音质量,但个人语音数据已造成泄露,有的即便录制好了,不会让用户进行导出。
5、本发明可通过在企业内部部署自己的数据采集系统及环境噪音检测系统,方便构建公司内部的语音数据库,并通过组织架构的形式将语音数据组织起来,方便部门内部或项目组内部同时进行个性化语音训练和生成。
6、录音与文本对齐
7、目前方案缺点:1)模板固定若给定提前准备的文本模板,让用户去读,往往会出现错读和漏读的现象,若没有一些纠正技术,很容易造成语言与文本不对齐的情况。或有的纠正技术限制太死,用户需要花费较长时间来纠正。2)文字识别不精确针对只让用户上传录音的情况,若录音质量不高,现有的语音识别算法不能100%将录音文字准确识别出来,会造成一定的文本错误。3)部分音节泄露针对只让用户上传录音的情况,若上传音频超过20s,则需要进行切片,在断点处,会造成一些音节音调泄露和失音的情况。
8、目前方案缺点:1)模型训练模式单一购买的模型服务往往只支持单人训练,不能多人同时训练,造成gpu资源大量长期占用和消耗较大磁盘空间。2)模型管理欠缺用户可能从事多个业务,每个业务条线要求的声音有区别,用户会进行不同形式的录音,来满足不同业务的要求,而现有方案不能很好地对个人语音合成模型进行管理,往往合成音色比较单一。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供克服上述问题或者至少部分地解决上述问题的一种音频数据采集和个性化语音训练及推理方法。
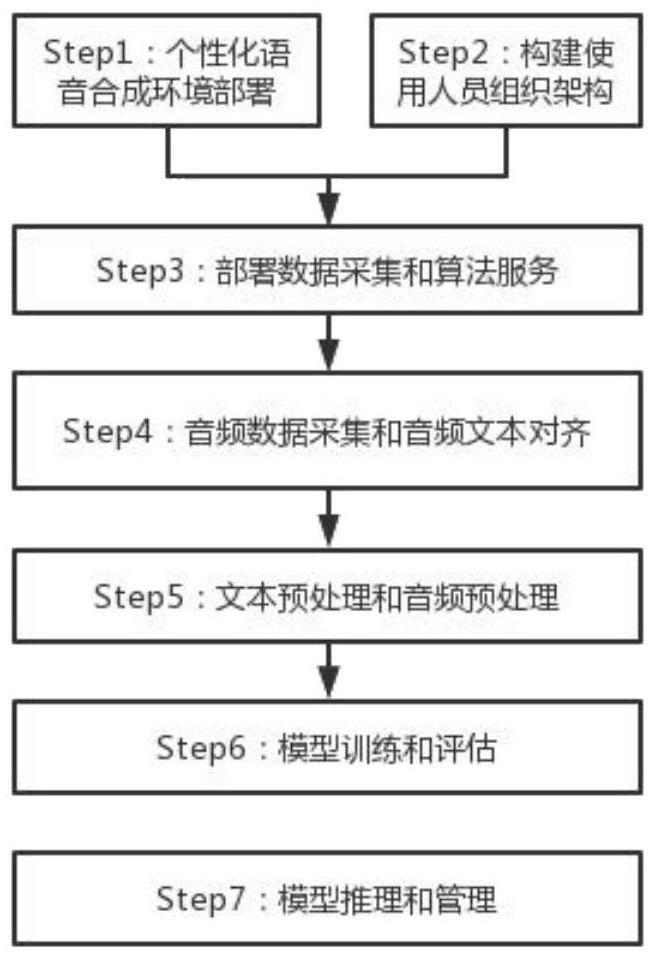
2、根据本发明的一个方面,提供了一种音频数据采集和个性化语音训练及推理方法,所述推理方法包括:
3、个性化语音合成环境部署;
4、构建使用人员组织架构;
5、部署数据采集和算法服务;
6、音频数据采集和音频文本对齐;
7、文本预处理和音频预处理;
8、模型训练和评估;
9、模型推理和管理。
10、可选的,所述个性化语音合成环境部署具体包括:
11、根据需求,配置不同的服务器用于模型训练和推理;
12、数据采集和算法服务需要软件环境,若算法基于python环境构建,安装特定的依赖包,针对语音安装ffmpeg,方便对音频进行采样和格式转化处理。
13、可选的,所述构建使用人员组织架构具体包括:
14、方便管理人员对使用成员进行权限管理,权限包括是否允许邀请他人组团进行多人个性化语音合成;
15、用户可录制不同的语音数据,来满足不同业务需求,共享进行使用。
16、可选的,所述部署数据采集和算法服务具体包括:
17、数据采集通过web形式在pc端和移动端进行采集,快速地通过python的gradio或streamlit前端应用包实现;
18、算法服务包括环境噪音检测、声音强度测量算法、语音识别、文本对比、语音合成技术;将所用算法服务部署上并测试调通。
19、可选的,所述音频数据采集和音频文本对齐具体包括:
20、进入数据采集页面,数据采集页面,在pc端和移动端进行操作;
21、环境噪音检测,用户进入采集页面后,先进行环境噪音检测,若超过噪音阈值,则需要用户寻找安静的环境进行录音;
22、选择采集模型,根据文字模板进行采集用户只需朗读给定的文字模板即可,比较简便,也推荐以这种方式进行音频采集;
23、文本比对和对齐,根据文字模板进行采集当用户根据一条文本朗读完后,此时会调用声音强度测量算法和语音识别算法;
24、声音强度测量算法用于判断用户录音是否满足需求,若声音太低,则会让用户提高音量;
25、语音识别算法,用于识别用户的读音与文本是否对齐,是否有漏读、错读和多读的现象,给用户指出来;
26、用户根据反馈的文本内容进行调整,也选择重复朗读来纠正之前的发音。
27、可选的,所述文本预处理和音频预处理具体包括:
28、文本在送入模型前会进行正则化、音素、音调、停顿转化;
29、音频预处理。
30、可选的,所述模型训练和评估具体包括:
31、用户可选择开源或自研模型进行模型训练;
32、注意训练模式是单说话人和多说话人,方便后续对模型进行管理;
33、对语音合成模型进行评估,使用主观mos指标进行评估;
34、对多音字、数字和英文发音的评估。
35、本发明提供的一种音频数据采集和个性化语音训练及推理方法,所述推理方法包括:个性化语音合成环境部署;构建使用人员组织架构;部署数据采集和算法服务;音频数据采集和音频文本对齐;文本预处理和音频预处理;模型训练和评估;模型推理和管理。避免数据泄露,提高用户录音效率,进一步提高数据质量。
36、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22101.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表