一种用于考试耳机的智能降噪方法及系统与流程
- 国知局
- 2024-06-21 11:37:13
本发明涉及音频信号处理,尤其涉及一种用于考试耳机的智能降噪方法及系统。
背景技术:
1、音频信号处理技术领域涉及处理和分析声音信号的方法,旨在提高声音质量、降低噪音、增强声音的可理解性以及改进声音相关应用的性能。这领域包括音频采集、编解码、增强、分析、合成等方面。
2、用于考试耳机的智能降噪方法是一种应用音频信号处理技术的方法,旨在为考试场景提供更清晰的声音环境,以帮助考生更好地专注于考试内容。其主要目的是降低环境噪音,包括背景谈话声、教室嘈杂声等,以确保考生能够清晰听到考试内容,提高考试效果。方法通常包括噪音检测、信号处理、音频增强和自适应调整等手段,以减少背景噪音,如谈话声和嘈杂声,确保考试内容清晰可闻,从而提高考试效果。
3、现有的降噪方法存在一些不足。首先,它们通常依赖于简单的噪音抑制技术,这在复杂或变化的噪音环境中效果有限,很难有效去除背景噪音而不损害原始音频质量。此外,传统方法往往忽略对多轨音频和远场噪音的深入处理,导致在音频质量和清晰度方面的不足。它们也缺乏有效的机制来预测和适应未来的噪音模式,这使得它们在动态环境中的表现不稳定。更重要的是,现有方法未能实现文本和语音的有效同步,这在需要精确语音识别和理解的应用场景中,如考试,导致理解错误和注意力分散。因此,这些局限性凸显了对更先进、更智能的降噪技术的迫切需求。
技术实现思路
1、本发明的目的是解决现有技术中存在的缺点,而提出的一种用于考试耳机的智能降噪方法及系统。
2、为了实现上述目的,本发明采用了如下技术方案:一种用于考试耳机的智能降噪方法,包括以下步骤:
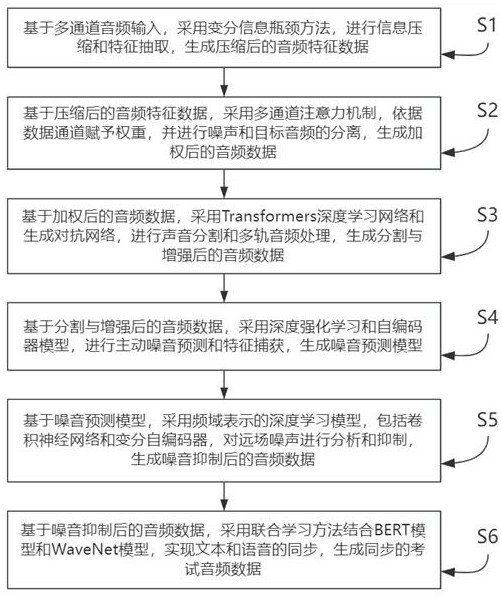
3、s1:基于多通道音频输入,采用变分信息瓶颈方法,进行信息压缩和特征抽取,生成压缩后的音频特征数据;
4、s2:基于所述压缩后的音频特征数据,采用多通道注意力机制,依据数据通道赋予权重,并进行噪声和目标音频的分离,生成加权后的音频数据;
5、s3:基于所述加权后的音频数据,采用transformers深度学习网络和生成对抗网络,进行声音分割和多轨音频处理,生成分割与增强后的音频数据;
6、s4:基于所述分割与增强后的音频数据,采用深度强化学习和自编码器模型,进行主动噪音预测和特征捕获,生成噪音预测模型;
7、s5:基于所述噪音预测模型,采用频域表示的深度学习模型,包括卷积神经网络和变分自编码器,对远场噪声进行分析和抑制,生成噪音抑制后的音频数据;
8、s6:基于所述噪音抑制后的音频数据,采用联合学习方法结合bert模型和wavenet模型,实现文本和语音的同步,生成同步的考试音频数据;
9、所述压缩后的音频特征数据具体为经过降维处理的音频信息,包括关键音频特征和噪声特征,所述加权后的音频数据具体指经过通道权重调整,优化后的目标音频与背景噪声的分离数据,所述分割与增强后的音频数据包括经过清晰度增强、噪声削弱的单一或多轨音频信号,所述噪音预测模型具体为用于识别潜在噪音模式并建立抑制策略的智能模型。
10、作为本发明的进一步方案,基于多通道音频输入,采用变分信息瓶颈方法,进行信息压缩和特征抽取,生成压缩后的音频特征数据的步骤具体为:
11、s101:基于多通道音频输入,采用快速傅里叶变换算法,对音频信号进行频域转换,并通过频率滤波,生成频域音频数据;
12、s102:基于所述频域音频数据,采用变分自编码器进行深度特征提取,并进行信息降维,生成降维音频特征;
13、s103:基于所述降维音频特征,采用卷积神经网络进行特征压缩,并进行最大池化,生成压缩音频特征数据;
14、s104:基于所述压缩音频特征数据,采用反向传播算法进行特征优化,生成优化后的音频特征数据;
15、所述频域音频数据具体为将时间域信号转化为频率成分的表示,所述降维音频特征包括主要的频率成分、音高和能量信息,所述压缩音频特征数据具体指降低数据维度后的核心音频信息。
16、作为本发明的进一步方案,基于所述压缩后的音频特征数据,采用多通道注意力机制,依据数据通道赋予权重,并进行噪声和目标音频的分离,生成加权后的音频数据的步骤具体为:
17、s201:基于所述优化后的音频特征数据,采用注意力机制模型对多通道数据进行分析,并进行自适应权重分配,生成通道权重数据;
18、s202:基于所述通道权重数据,采用长短期记忆网络分析音频时间序列特性,并进行音频前景与背景分离,生成分离后的音频数据;
19、s203:基于所述分离后的音频数据,采用深度可分离卷积神经网络进行特征加权,并进行噪声抑制,生成加权后的音频数据;
20、s204:基于所述加权后的音频数据,采用动态范围压缩进行音频调整,优化音频听感,生成动态调整后的音频数据。
21、作为本发明的进一步方案,基于所述加权后的音频数据,采用transformers深度学习网络和生成对抗网络,进行声音分割和多轨音频处理,生成分割与增强后的音频数据的步骤具体为:
22、s301:基于所述动态调整后的音频数据,采用transformers网络进行深度特征识别,并进行自注意力机制分析,生成深度特征音频数据;
23、s302:基于所述深度特征音频数据,采用生成对抗网络进行音频增强,并进行对抗训练,生成增强后的音频数据;
24、s303:基于所述增强后的音频数据,采用多轨混合算法进行音轨分割与重组,并进行空间特征分析,生成分割后的音频数据;
25、s304:基于所述分割后的音频数据,采用波束成形技术进行音轨方向调整,生成分割与增强后的音频数据;
26、所述深度特征音频数据包括音频的时域和频域详细特征。
27、作为本发明的进一步方案,基于所述分割与增强后的音频数据,采用深度强化学习和自编码器模型,进行主动噪音预测和特征捕获,生成噪音预测模型的步骤具体为:
28、s401:基于所述分割与增强后的音频数据,采用q-learning算法,进行数据特征的探索和优化,生成特征优化后的音频数据;
29、s402:基于所述特征优化后的音频数据,利用自编码器进行音频特征自动编码,生成自编码后的音频特征;
30、s403:基于所述自编码后的音频特征,采用递归神经网络进行噪音模式的识别,生成标识的噪音模式;
31、s404:基于所述标识的噪音模式,利用深度残差网络进行噪音特征的提取和预测,生成噪音预测模型;
32、所述自编码后的音频特征具体指对音频数据的主要成分和关键频段进行的编码,所述标识的噪音模式具体为包括车流、风声、人声的背景噪音模式,所述噪音预测模型具体为用于识别并预测出现的噪音模式的神经网络模型。
33、作为本发明的进一步方案,基于所述噪音预测模型,采用频域表示的深度学习模型,包括卷积神经网络和变分自编码器,对远场噪声进行分析和抑制,生成噪音抑制后的音频数据的步骤具体为:
34、s501:基于所述噪音预测模型,采用快速傅里叶变换进行频域转换,生成频域表示的音频数据;
35、s502:基于所述频域表示的音频数据,利用卷积神经网络进行频域特征提取,生成频域特征数据;
36、s503:基于所述频域特征数据,采用变分自编码器进行噪声特征深度编码,生成深度编码的噪声特征;
37、s504:基于所述深度编码的噪声特征,采用谱减法进行噪声抑制,生成噪音抑制后的音频数据;
38、所述频域表示的音频数据具体为将音频数据从时域转换到频域的结果,所述频域特征数据包括音频中的基频、谐波、噪声信息,所述深度编码的噪声特征具体为利用变分方法对噪声进行的编码,所述噪音抑制后的音频数据具体为滤除背景噪声后的音频数据。
39、作为本发明的进一步方案,基于所述噪音抑制后的音频数据,采用联合学习方法结合bert模型和wavenet模型,实现文本和语音的同步,生成同步的考试音频数据的步骤具体为:
40、s601:基于所述噪音抑制后的音频数据,利用bert模型进行深度文本特征提取,生成深度文本特征;
41、s602:基于所述深度文本特征,采用wavenet模型进行音频的深度特征提取,生成深度音频特征;
42、s603:基于所述深度音频特征和深度文本特征,采用多模态融合技术实现特征融合,生成融合后的文本和音频特征;
43、s604:基于所述融合后的文本和音频特征,利用动态时间规整进行文本和语音同步调整,生成同步的考试音频数据;
44、所述深度文本特征具体为通过bert模型获得的音频对应文本内容的向量表示,所述深度音频特征具体为音频数据中包括节奏、音高、音量的关键特性,所述融合后的文本和音频特征具体为文本和音频共同特性的集成表示。
45、一种用于考试耳机的智能降噪系统,所述用于考试耳机的智能降噪系统用于执行上述用于考试耳机的智能降噪方法,所述系统包括音频预处理模块、音频特征优化模块、噪音识别和预测模块、噪音抑制模块、文本和语音同步模块。
46、作为本发明的进一步方案,所述音频预处理模块基于多通道音频输入,采用快速傅里叶变换将音频信号由时域转换到频域以便进行分析和处理,并通过频率滤波消除无用频率成分,生成频域化音频数据;
47、所述音频特征优化模块基于频域化音频数据,采用变分自编码器和卷积神经网络,提取和优化音频特征,生成优化音频特征数据;
48、所述噪音识别和预测模块基于优化音频特征数据,采用q-learning算法和深度残差网络提取和预测噪音特征,进行噪音模式识别和特征预测,生成噪音预测模型;
49、所述噪音抑制模块基于噪音预测模型,采用变分自编码器和谱减法,进行噪声抑制,生成噪音抑制后的音频数据;
50、所述文本和语音同步模块基于噪音抑制后的音频数据,采用bert模型和wavenet模型配合多模态融合技术和动态时间规整方法,生成同步的考试音频数据;
51、所述快速傅里叶变换具体为将音频信号从时域转换到频域的算法,所述频率滤波包括高通滤波、低通滤波和带通滤波,所述频域化音频数据具体指经过快速傅里叶变换和频率滤波后的音频数据,所述变分自编码器具体为一种深度学习模型,用于从数据中学习并提取深层次的特征,所述卷积神经网络包括卷积层、池化层和全连接层,用于对输入的数据进行特征提取和优化,所述优化音频特征数据具体指经过变分自编码器和卷积神经网络处理后的音频特征数据,所述深度残差网络包括多组残差块,用于深度学习和提取数据特征,所述噪音预测模型具体指基于q-learning算法和深度残差网络学习得到的噪音模式预测模型,所述变分自编码器用于深度编码噪声特征,所述谱减法具体为一种基于频域的噪声抑制方法,通过减少噪声频谱来抑制噪声,所述噪音抑制后的音频数据具体指经过变分自编码器和谱减法处理后的音频数据,所述bert模型具体为一种深度学习模型,用于文本特征提取,所述wavenet模型具体为一种深度学习模型,用于音频特征提取,所述同步的考试音频数据具体指经过bert模型、wavenet模型、多模态融合技术和动态时间规整方法处理后,实现文本和语音同步的音频数据。
52、作为本发明的进一步方案,所述音频预处理模块包括第一频域转换子模块、频率滤波子模块;
53、所述音频特征优化模块包括深度特征提取子模块、特征压缩子模块、特征优化子模块;
54、所述噪音识别和预测模块包括特征探索和优化子模块、音频特征自动编码子模块、噪音模式识别子模块、噪音预测子模块;
55、所述噪音抑制模块包括第二频域转换子模块、频域特征提取子模块、噪声特征深度编码子模块、噪声抑制子模块;
56、所述文本和语音同步模块包括深度文本特征提取子模块、音频深度特征提取子模块、特征融合子模块、文本和语音同步调整子模块。
57、与现有技术相比,本发明的优点和积极效果在于:
58、本发明中,通过使用变分信息瓶颈方法,能更有效地压缩音频信息并精准提取关键音频特征,减少数据处理的复杂性,同时保持音频质量。多通道注意力机制的实施不仅提高了目标音频的聚焦度,还成功分离了噪声和目标音频,大大提高了音频清晰度和质量。transformers和生成对抗网络的应用使声音分割和多轨音频处理更加精细,提供了更清晰、更纯净的音频输出。深度强化学习和自编码器模型的结合使系统能够主动预测噪音并捕获更细微的音频特征,从而实现更有效的噪音抑制。通过结合bert模型和wavenet模型的联合学习方法,实现文本和语音的无缝同步,为考生提供一个更加集中和无干扰的测试体验。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22479.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表