一种基于数字人实时问答响应的优化系统及方法与流程
- 国知局
- 2024-06-21 11:37:04
本发明涉及计算机人工智能,具体涉及一种基于数字人实时问答响应的优化系统及方法。
背景技术:
1、数字人(digital human / meta human)是运用数字技术创造出来的与人类形象接近的数字化人物形象,存在于非物理世界中,由计算机手段创造及使用并具有多重人类特征(比如外貌特征、人类表演能力 交互能力等)的综合产物。数字人口型则是数字人说话或发音时的口部形状,比如说发某个声音时两唇的形状。随着数字人相关技术的不断发展,其运用门槛也相对降低,这也将数字人相较于真人的优势凸显了出来。由于数字人不需要饮食睡眠,也不会疲倦生病,可以做到24小时不间断地工作,因而数字人可以大幅减少人力成本。目前,数字人知识问答系统基于深度学习已经取得长足进展并逐步应用,但是由于数字人口型生成流程处理时间长,仍存在响应速度慢的问题,难以实现流畅的人机交互。
技术实现思路
1、本发明提供一种基于数字人实时问答响应的优化系统及方法,解决了现有技术响应速度慢的技术问题。
2、本发明提供的基础方案为:一种基于数字人实时问答响应的优化系统,包括:客户端,所述客户端用于用户进行提问;其特征在于,还包括:
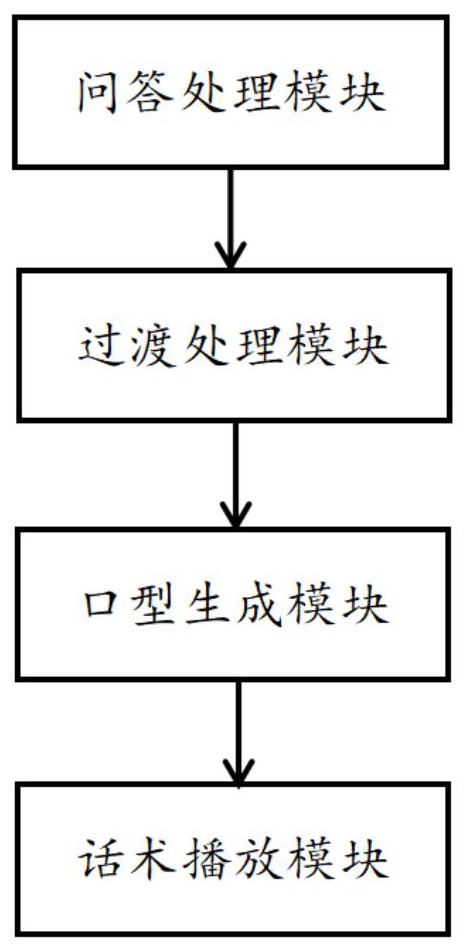
3、问答处理模块,所述问答处理模块用于接收客户端的提问,并发送客户端的提问到chatgpt获取相应的答案话术,调用语音合成算法将chatgpt获取的答案话术生成答案语音文件;
4、过渡处理模块,所述过渡处理模块用于获取当前时段播放的音频的后面一段音频,将后一段音频作为过渡语音文本;
5、口型合成模块,所述口型合成模块用于根据语音文件生成口型参数,语音文件包括答案语音文件、过渡语音文本,口型参数包括答案口型参数和过渡口型参数;
6、话术播放模块,话术播放模块用于结合口型参数的数字人画面形成与音频配合的数字人动画,将数字人动画与音频组合形成视频,通过话术播放模块播放该视频;
7、价值传递处理模块,所述价值传递处理模块用于获取整个视频中用于价值传递的音频,将价值传递的音频作为价值传递语音文本,价值传递语音文本经过口型合成模块生成价值传递口型。
8、本发明的工作原理及优点在于:
9、1.在本方案中,一方面根据语音文件生成答案话术口型,另一方面获取当前时段播放的音视频的后面一段音视频,根据后面一段音视频合成过渡话术口型,随后合成答案话术口型、过渡话术口型与价值传递口型得到合成口型,并根据合成口型播放过渡话术与答案话术,这样不需要利用深度学习算法,能够减少数字人口型生成流程处理时间,提高响应速度,有利于实现流畅的人机交互。
10、2.本方案应用chatgpt智能问答技术可以实现数字人的实时智能问答和回复,提高了数字人的实时问答响应优化能力,解决了数字人对话能力有限的问题;本方案应用chatgpt实现数字人实时智能问答,也可以通过websocket实时接收提问,实现数字人的实时问答交互。
11、本发明不需要利用深度学习算法,能够减少数字人口型生成流程处理时间,提高响应速度,有利于实现流畅的人机交互。
12、进一步,所述口型合成模块包括口型参数缓存单元,检查是否存在对应的口型参数,如果存在对应的口型参数,则直接读取口型参数,如没有匹配的口型参数,口型合成模块将语音文本转化为口型参数;将口型参数存储到参数缓存空间,以待匹配调用。
13、有益效果在于:每次将生成的过渡口型参数存储到参数缓存空间备用,可以快速生成答案话术口型。
14、进一步,所述口型合成模块还包括文本处理单元,文本处理单元在接收到语音文本时候,由时间顺序,将语音文本转化为字符流,并存储到字符流缓存队列中;从字符流缓存队列按顺序获取队列数据进行实时分析,识别语音的停顿信息与语气信息;在口型合成模块中根据语音的语气信息和停顿信息生成口型参数。
15、有益效果在于:可以根据语音的停顿信息与语气信息,快速生成过渡话术口型,并将生成的过渡口型参数存储到参数缓存空间备用。
16、进一步,所述文本处理单元识别形成的字符流是否有效,需要在语音文本转化字符流前对语音文本进行切分,其切分方式是将音频放慢,按照语音中超过100毫秒,音量低于-50进行切分,去除低于1秒语音段。
17、有益效果在于:这样可以在合成口型中充分体现语音的价值传递信息。
18、基于上述公开的一种基于数字人实时问答响应的优化系统,本发明还提供一种基于数字人实时问答响应的优化方法,包括步骤:
19、s1、问答处理模块接收客户端的提问,并发送客户端的提问到chatgpt获取相应的答案话术,调用语音合成算法将chatgpt获取的答案话术生成答案语音文件;
20、s2、过渡处理模块获取当前时段播放的音频的后面一段音频,将后一段音频作为过渡语音文本;
21、s3、口型合成模块根据语音文件生成口型参数,语音文件包括答案语音文件、过渡语音文本,口型参数包括答案口型参数和过渡口型参数;
22、s4、话术播放模块结合口型参数的数字人画面形成与音频配合的数字人动画,将数字人动画与音频组合形成视频,通过话术播放模块播放该视频。
23、本发明的工作原理及优点在于:本方案应用chatgpt智能问答技术可以实现数字人的实时智能问答和回复,提高了数字人的实时问答响应优化能力,解决了数字人对话能力有限的问题;本方案应用chatgpt实现数字人实时智能问答,也可以通过websocket实时接收提问,实现数字人的实时问答交互。
24、进一步,在s3中,价值传递处理模块用于获取整个视频中用于价值传递的音频,将价值传递的音频作为价值传递语音文本,价值传递语音文本经过口型合成模块生成价值传递口型。
25、有益效果在于:每次将生成的过渡口型参数存储到参数缓存空间备用,可以快速生成答案话术口型。
26、进一步,在s3中,口型参数缓存单元检查是否存在对应的口型参数,如果存在对应的口型参数则直接读取口型参数,如没有匹配的口型参数,口型合成模块将语音文本转化为口型参数;将口型参数存储到参数缓存空间,以待匹配调用。
27、有益效果在于:可以根据语音的停顿信息与语气信息,快速生成过渡话术口型,并将生成的过渡口型参数存储到参数缓存空间备用。
28、进一步,在s3中,文本处理单元在接收到语音文本时候,由时间顺序,将语音文本转化为字符流,并存储到字符流缓存队列中;从字符流缓存队列按顺序获取队列数据进行实时分析,识别语音的停顿信息与语气信息;在口型合成模块中根据语音的语气信息和停顿信息生成口型参数。
29、有益效果在于:这样可以在合成口型中充分体现语音的价值传递信息。
技术特征:1.一种基于数字人实时问答响应的优化系统,包括:客户端,所述客户端用于用户进行提问;其特征在于,还包括:
2.如权利要求1所述的一种基于数字人实时问答响应的优化系统,其特征在于,还包括价值传递处理模块,所述价值传递处理模块用于获取整个视频中用于价值传递的音频,将价值传递的音频作为价值传递语音文本,价值传递语音文本经过口型合成模块生成价值传递口型。
3.如权利要求2所述的一种基于数字人实时问答响应的优化系统,其特征在于,所述口型合成模块包括口型参数缓存单元,检查是否存在对应的口型参数,如果存在对应的口型参数,则直接读取口型参数,如没有匹配的口型参数,口型合成模块将语音文本转化为口型参数;将口型参数存储到参数缓存空间,以待匹配调用。
4.如权利要求3所述的一种基于数字人实时问答响应的优化系统,其特征在于,所述口型合成模块还包括文本处理单元,文本处理单元在接收到语音文本时候,由时间顺序,将语音文本转化为字符流,并存储到字符流缓存队列中;从字符流缓存队列按顺序获取队列数据进行实时分析,识别语音的停顿信息与语气信息;在口型合成模块中根据语音的语气信息和停顿信息生成口型参数。
5.如权利要求4所述的一种基于数字人实时问答响应的优化系统,其特征在于,所述文本处理单元识别形成的字符流是否有效,需要在语音文本转化字符流前对语音文本进行切分,其切分方式是将音频放慢,按照语音中超过100毫秒,音量低于-50进行切分,去除低于1秒语音段。
6.一种基于数字人实时问答响应的优化方法,其特征在于,包括步骤:
7.如权利要求6所述的一种基于数字人实时问答响应的优化方法,其特征在于,在s3中,价值传递处理模块用于获取整个视频中用于价值传递的音频,将价值传递的音频作为价值传递语音文本,价值传递语音文本经过口型合成模块生成价值传递口型。
8.如权利要求7所述的一种基于数字人实时问答响应的优化方法,其特征在于,在s3中,口型参数缓存单元检查是否存在对应的口型参数,如果存在对应的口型参数则直接读取口型参数,如没有匹配的口型参数,口型合成模块将语音文本转化为口型参数;将口型参数存储到参数缓存空间,以待匹配调用。
9.如权利要求8所述的一种基于数字人实时问答响应的优化方法,其特征在于,在s3中,文本处理单元在接收到语音文本时候,由时间顺序,将语音文本转化为字符流,并存储到字符流缓存队列中;从字符流缓存队列按顺序获取队列数据进行实时分析,识别语音的停顿信息与语气信息;在口型合成模块中根据语音的语气信息和停顿信息生成口型参数。
10.如权利要求9所述的一种基于数字人实时问答响应的优化方法,其特征在于,在s3中,文本处理单元识别形成的字符流是否有效,需要在语音文本转化字符流前对语音文本进行切分,其切分方式是将音频放慢,按照语音中超过100毫秒,音量低于-50进行切分,去除低于1秒语音段。
技术总结本发明涉及计算机人工智能技术领域,具体涉及一种基于数字人实时问答响应的优化系统及方法,其中系统包括:问答处理模块,用于接收客户端的提问,并发送客户端的提问到ChatGPT获取相应的答案话术,调用语音合成算法将ChatGPT获取的答案话术生成答案语音文件;过渡处理模块,用于获取当前时段播放的音频的后面一段音频,将后一段音频作为过渡语音文本;口型合成模块,用于根据语音文件生成口型参数,语音文件包括答案语音文件、过渡语音文本;话术播放模块,用于结合口型参数的数字人画面形成与音频配合的数字人动画,将数字人动画与音频组合形成视频,通过话术播放模块播放该视频。本发明能够提高响应速度,有利于实现流畅的人机交互。技术研发人员:陶澍受保护的技术使用者:重庆虚拟实境科技有限公司技术研发日:技术公布日:2024/3/17本文地址:https://www.jishuxx.com/zhuanli/20240618/22461.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表