一种基于叠加模型融合宽度学习系统的语音情感识别方法
- 国知局
- 2024-06-21 11:37:24
本发明涉及机器学习、情感计算、人机交互领域,具体涉及一种基于叠加模型融合宽度学习系统的语音情感识别方法。
背景技术:
1、早期语音情感识别主要依靠人工设计的语音声学特征,随后研究者尝试采用高斯混合模型(gmm)、支持向量机(svm)等机器学习方法对语音特征进行模型化分类,取得了一定进展。
2、近年来,深度学习技术在各个领域展现强大优势,语音情感识别也引入了卷积神经网络(cnn)、长短期记忆(lstm)等深度模型。然而,深度学习也存在一些缺点,其中计算速度和资源消耗是主要瓶颈(a.shrestha and a.mahmood,"review of deep learningalgorithms and architectures,"in ieee access,vol.7,pp.53040-53065,2019,doi:10.1109/access.2019.2912200.)。为解决这一问题,陈俊龙院士提出了宽度学习系统(bls)(c.l.p.chen and z.liu,"broad learning system:an effective and efficientincremental learning system without the need for deep architecture,"in ieeetransactions on neural networks and learning systems,vol.29,no.1,pp.10-24,jan.2018,doi:10.1109/tnnls.2017.2716952.)。宽度学习是一种独立于深度结构的神经网络架构,其出色的计算速度和简洁的结构对于谓机器学习领域代表着机器学习领域朝着更高效的方向又迈出了重要的一步。
3、然而,单一模型识别语音情感的能力仍然相对有限,因此集成学习应运而生。集成学习是一种集成多个机器学习模型,通过某种策略综合各模型的结果,以得到最终输出的技术手段。与单一模型相比,集成学习通常可以提高稳定性和泛化能力。
技术实现思路
1、针对现有技术中单一模型在识别语音情感方面存在的稳定性不强和泛化能力不足等问题,本发明提出了一种基于叠加模型融合宽度学习系统的语音情感识别方法及系统,以提高语音情感识别的效果。
2、本发明至少通过如下技术方案之一实现。
3、一种基于叠加模型融合宽度学习系统的语音情感识别方法,包括以下步骤:
4、采集包含真实语音样本的数据集作为训练和测试用数据;
5、对采集的语音数据进行预处理,提取音频参数作为基础语音特征;
6、在基础语音特征的基础上,对每个语音样本计算包含梅尔频率倒谱系数、能量、基音频率、光谱质心的高维语音声学特征,构建compare_2016特征集以表征语音样本;
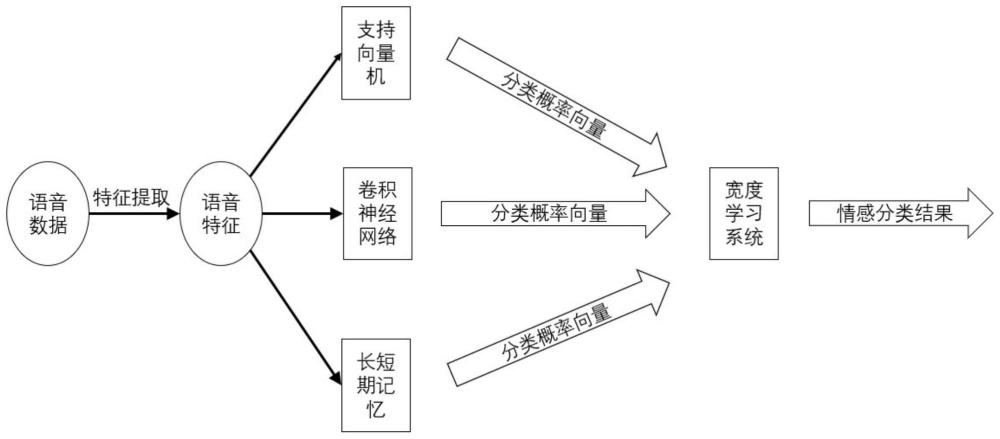
7、构建并基于compare_2016特征集训练语音情感识别多模型;语音情感识别多模型包括第一层多模型集成框架和第二层元模型,元模型以第一层多模型集成框架的输出作为输入,进行二次融合学习,得到语音情感识别结果。
8、进一步地,对语音数据的预处理过程包括音频格式标准化、采样率统一、去除噪音、语音分段。
9、进一步地,对每个语音样本的梅尔频率倒谱系数计算过程包括预加重、分帧、应用汉明窗、傅里叶变换、梅尔滤波器组、对数压缩。
10、进一步地,第一层多模型集成框架包含三个基模型,分别为支持向量机、卷积神经网络、长短期记忆。
11、进一步地,针对每个基模型,采用5折交叉验证进行训练,并分别得到5组不同验证集的输出结果以及相同测试集的5次输出结果;将每个基模型在5组不同验证集上的输出结果进行纵向堆叠,形成元模型的训练数据集特征列;将测试集的5份输出结果取平均后形成元模型的测试数据集特征列;最后,将三个基模型得到的训练数据集特征列和测试数据集特征列横向合并,分别构成元模型的训练数据集和测试数据集。
12、进一步地,第二层元模型采用宽度学习系统。
13、进一步地,所述宽度学习系统的构建过程包括引入特征节点和增强节点、合并节点、计算输出层权重、增量学习、结构简化、模型评估。
14、进一步地,第一层多模型集成框架的训练和测试数据均为compare_2016特征集。
15、进一步地,元模型的训练和测试数据基于三个基模型对语音情感的分类概率向量。
16、实现所述的一种基于叠加模型融合宽度学习系统的语音情感识别方法的系统,包括语音数据输入模块、语音特征提取模块、基模型训练模块、元模型训练模块和情感分类输出模块;
17、语音数据输入模块,用于接收原始语音数据作为输入;
18、语音特征提取模块,用于对输入的语音数据进行预处理和特征提取,构建compare_2016特征集;
19、基模型训练模块,用于针对提取的语音特征,分别训练支持向量机、卷积神经网络和长短期记忆网络;
20、元模型训练模块,用于利用基模型的输出构建元模型的数据集,并使用宽度学习系统进行元模型的训练;
21、情感分类输出模块,用于输出最终的语音情感分类结果。
22、本发明在语音情感识别领域取得了显著的有益效果,主要体现在以下几个方面:
23、1.compare_2016语音特征集构建:本发明充分利用了compare_2016特征集,通过对语音数据的精心处理和声学特征工程,构建了具有丰富信息的特征表示。这有助于提高模型对语音情感的敏感性和表达能力,为后续模型训练提供了有力支持。
24、2.互补性模型设计:本发明的设计考虑到svm、cnn、lstm三种基模型在语音情感识别中的互补特性。svm具备强大的泛化能力,cnn能够有效捕捉局部信息,而lstm则擅长学习时序模式。这种巧妙的组合使得各模型相互补充,形成了更为全面和综合的语音情感建模。
25、3.宽度学习系统的二次融合:本发明采用宽度学习系统(bls)作为二次融合模型,通过特征节点和增强节点的引入,巧妙地学习异构模型的互补信息。这使得多个模型的判断结果得以再融合,进一步提升了系统对语音情感的准确性和鲁棒性。
26、4.叠加模型融合:本发明采用了叠加模型融合的策略,针对每个基模型,采用5折交叉验证进行训练,并分别得到5组不同验证集的输出结果以及相同测试集的5次输出结果;将每个基模型在5组不同验证集上的输出结果进行纵向堆叠,形成元模型的训练数据集特征列;将测试集的5份输出结果取平均后形成元模型的测试数据集特征列;最后,将三个基模型得到的训练数据集特征列和测试数据集特征列横向合并,分别构成元模型的训练数据集和测试数据集。通过这种叠加模型融合方式,本发明充分利用了各个基模型的优势,通过元模型学习它们之间的权衡关系,提高对语音情感的建模效果,同时有效抑制了过拟合现象,增强了模型的识别效果和泛化性,使得系统更为鲁棒地适应不同的语音情感数据。
27、5.构建端到端系统:本发明构建了端到端的语音情感识别系统,通过优化的模型集成框架和宽度学习系统,实现了对语音信号的直接处理和情感分类输出。这种端到端系统简化了流程,提高了系统的实用性和适用性,使得语音情感识别更加直观和易用。整个系统的设计旨在为用户提供高效、准确且直观的语音情感识别服务。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22503.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。