一种基于噪声联合估计的改进OMLSA语音降噪算法的制作方法
- 国知局
- 2024-06-21 11:37:13
本发明涉及语音降噪,特别是一种基于噪声联合估计的改进omlsa语音降噪算法。
背景技术:
1、语音在日常生活中有着不可替代的作用,是信息传递最直接、最平常的一种途径。同样在其他应用领域,语音也有着十分广泛的作用,比如工业、医疗、家电、汽车等等领域,语音信号的存在也不可被忽视。然而,在现实生活中,语音信号的存在常常伴随着周围环境的噪声,各类噪声都会影响语音信号的质量。因此,语音降噪技术在各类语音信号通信的系统中最为重要。
2、语音降噪可分为单通道语音降噪和多通道语音降噪,其中,单通道语音降噪由于其成本低,易实现等特点被国内外学者广泛研究。目前的几种单通道语音降噪算法主要有谱减法、基于统计模型的方法、基于子空间分解的方法等。谱减法是将估计的噪声功率谱从嘈杂的语音中减去,算法性能取决于对噪声频谱的跟踪;基于子空间分解的方法是假设信号子空间和噪声子空间是正交的,但是这种子空间正交性在短时条件下不精确。本发明是基于统计模型的方法,在该方法中主要有最小均方误差-短时谱幅值估计器(minimum meansquare error short time spectral amplitude estimator,mmse-stsa)、最优修正的对数谱幅度估计器(optimal modified logarithmic spectral amplitude estimator ,omlsa),而对于噪声估计方法有最小值统计(minimum statistics,ms)、最小值控制的递归平均算法(minima controlled recursive averaging,mcra)、改进的mcra(improved-mcra,imcra)算法以及结合先验语音缺失概率(speech absence probability, sap)的方法。综合上述的几种语音降噪方法,在低信噪比条件下性能均较低。本发明针对低信噪比条件下单通道语音降噪算法性能低的问题,提出了基于噪声联合估计的改进omlsa语音降噪算法。
3、噪声是语音降噪领域的主要研究方向,噪声估计的准确性决定了降噪的性能。现有的技术在强噪声背景下的降噪性能仍有待提高。主要是针对强噪声干扰下的语音信号输出信噪比不高及语音质量降低的问题。
4、针对上述缺点,本发明主要提出了一种基于噪声联合估计的改进omlsa语音降噪算法。首先,将信号进行时域分帧、加窗处理后,利用傅里叶变换将其转换到频域;其次,在多帧信号处理、参数迭代中,采用基于噪声联合估计的改进omlsa语音降噪算法,主要是对omlsa算法中的估计噪声更新模块进行改进,提出二次平滑噪声估计,在第一次平滑噪声估计的基础上,联合残余噪声估计,先结合小波分解近似求得残余噪声估计值,并将该估计值与降噪语音信号进行平滑处理,得到第二次平滑噪声估计值,根据噪声的加性特征,将两次估计值合并更新。本发明提高了低信噪比条件下输出语音的分段信噪比、减少了语音失真、提升了语音质量。
技术实现思路
1、针对上述问题,提供一种基于噪声联合估计的改进omlsa语音降噪算法。通过对噪声估计模块进行改进,引入了残余噪声,结合小波一级分解近似求得残余噪声的估计值,并提出二次平滑的噪声估计,利用第一次平滑得到的频谱幅值对求得的残余噪声进行第二次平滑噪声估计,联合两次的平滑噪声估计值在每帧信号中迭代处理、合并更新,由于提高了噪声估计的精度,从而提高了语音质量,减少了语音降噪的失真度。本发明提出二次噪声更新,通过联合降噪后的残余噪声,更准确的更新了噪声估计值,通过平滑噪声处理来减少误差,提高语音的信噪比。此外,本发明可显著提高语音信噪比和语音质量,降低语音的失真度。
2、为达到上述目的,本发明所采用的技术方案是。
3、一种基于噪声联合估计的改进omlsa语音降噪算法,包括以下步骤:
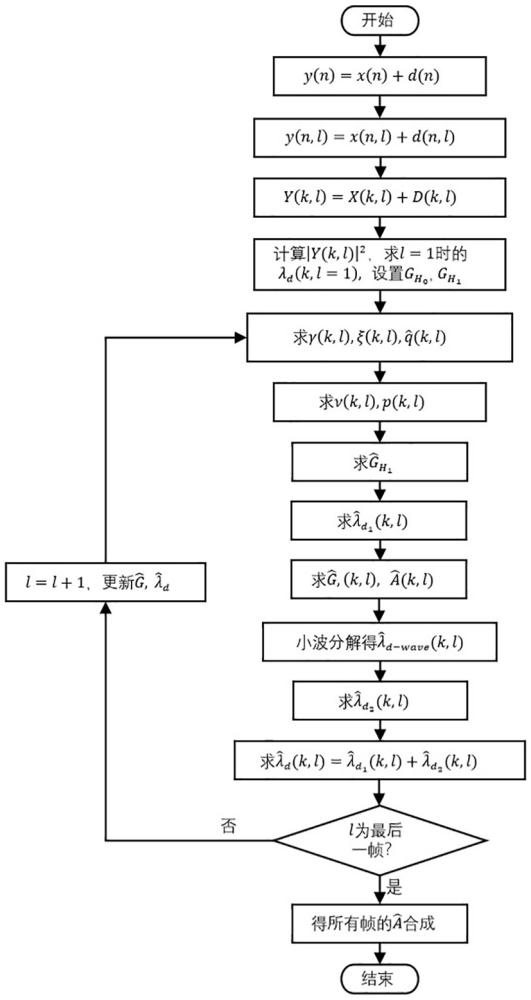
4、步骤1:设 x( n)和 d( n)为语音和不相关的加性噪声,接收信号模型为: y( n)=x( n)+ d( n);
5、步骤2:将信号分帧,利用汉宁窗做加窗处理,得到: y( n, l)= x( n, l)+d( n, l),其中为帧索引;
6、步骤3:利用傅里叶变换,将时域信号转换为频域信号,得到: y( k, l)= x( k, l)+ d( k, l),其中 k表示频率索引;
7、步骤4:计算,利用 l=1时的代替噪声功率谱,设置常数项,的初始值为1;
8、步骤5:在omlsa-sap算法的实际处理中,先验信噪比 ξ( k, l)是未知的,可利用下式来获得先验信噪比:,其中α=0.92;
9、同时计算后验信噪比:;
10、并根据先验信噪比 ξ( k, l)求解先验概率;
11、步骤6:依据步骤5中的先验信噪比 ξ( k, l)和后验信噪比,求得;
12、并最终求解条件语音存在概率;
13、步骤7:基于omlsa语音降噪算法求解语音存在时的增益;
14、步骤8:在噪声谱估计的过程中,设定初始值 λ d0为第一帧频谱幅值的平方,并使用改进的噪声谱估计更新方法来更新值;
15、步骤9:判断该帧是否为最后一帧,“否”则继续执行第10步,“是”则跳转并执行第11步;
16、步骤10: l= l+1,跳转至第5步,并用当前帧计算得到的更新值和代替和计算下一帧频域信号;
17、步骤11:得到所有帧去噪语音信号频谱幅度:,再对进行算法合成得到完整语音。
18、优选的,所述步骤5中的先验概率的计算方法如下:
19、通过在递归平均后的频域信号上应用局部(θ=local)和全局(θ=global)的平均窗口,分别获得先验信噪比 ξ( k, l)的局部和全局的平均值,即
20、,其中 β=0.75,的初始值为1;
21、, 其中 ωlocal=1, hlocal为汉宁窗;
22、, 其中 ωgloba=15, hgloba为汉宁窗;
23、因此,局部和全局的能量为:
24、,其中 min=-15 db, max=-5 db
25、,其中 min=-15 db, max=-5 db
26、为了进一步衰减纯噪声帧中的噪声,定义相邻帧中的语音能量:
27、
28、则先验概率为: 。
29、优选的,所述步骤6中的所述条件语音存在概率求解方法如下:
30、假设 h0( k, l)和 h1( k, l)分别表示语音不存在和语音存在,并假设信号满足复高斯分布,同时设和分别表示语音在两种条件下的概率密度函数,则:
31、
32、其中, λ d( k, l)为噪声方差, λ x( k, l)为语音信号方差;
33、从而可求得条件语音存在概率为:
34、
35、其中,表示语音不存在的先验概率,表示先验信噪比,,其中表示后验信噪比。
36、优选的,所述步骤7中的所述语音存在时的增益计算方法如下:
37、(1)基于统计模型:
38、
39、(2)当语音信号不存在时,增益被约束为大于常数阈值 g min,因此:
40、
41、(3)则当语音存在时的增益为:
42、
43、优选的,所述步骤8中的所述改进的噪声谱估计更新方法步骤如下:
44、步骤s1:计算平滑参数,其中 α=0.85为平滑因子, p( k, l)为语音存在概率;
45、步骤s2:获得第一次平滑噪声方差:
46、;
47、步骤s3:计算整体增益:;
48、步骤s4:获取去噪语音信号频谱幅度:;
49、omlsa估计器得到的频谱幅度的最优修正估计值为:,其中, a( k,l)为语音信号的频谱幅度;
50、步骤s5:利用db4小波分解得到一组小波系数近似噪声信息;
51、步骤s6:取中的中值mad计算噪声方差,并引入常数增益thr=-17db,防止失真:;
52、步骤s7:利用第一次去噪的语音信号频谱幅度对噪声方差进行二次平滑:;
53、步骤s8:联合噪声估计,求得当前帧数据的最终的噪声方差为:。
54、优选的,所述信号的采样率为8000hz。
55、优选的,所述汉宁窗的使用长度为512。
56、优选的,所述汉宁窗具有25%的重叠。
57、由于采用上述技术方案,本发明具有以下有益效果。
58、(1)本发明基于omlsa语音降噪算法,通过对噪声估计模块进行改进,引入了残余噪声,结合小波一级分解近似求得残余噪声的估计值,并提出二次平滑的噪声估计,利用第一次平滑得到的频谱幅值对求得的残余噪声进行第二次平滑噪声估计,联合两次的平滑噪声估计值在每帧信号中迭代处理、合并更新,由于提高了噪声估计的精度,从而提高了语音质量,减少了语音降噪的失真度。
59、(2)本发明针对强噪声干扰条件下,语音信号输出的信噪比底,语音质量差的问题,在噪声估计模块提出了二次噪声更新,通过联合降噪后的残余噪声,更准确的更新了噪声估计值,通过平滑噪声处理来减少误差,从而提高了语音信噪比。
60、(3)本发明可在低信噪比条件下,相比于传统的mmse-ms、mmse-mcra、omlsa-imcra、omlsa-sap算法,显著提高了语音信噪比和语音质量,降低了语音失真度。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22480.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表