基于涌现交流规则的多智能体通信方法及系统
- 国知局
- 2024-06-21 11:38:18
本发明属于人工智能领域中的多智能体间的涌现通信领域和认知推理基准测试领域。
背景技术:
1、多智能体间的涌现通信。在人类社会中,沟通交流对完成一个合作任务大有帮助,相似的,在多智能体的环境中,单个智能体的能力有限,往往不足以完成复杂的合作任务,通信让智能体之间开展合作成为可能,进而允许智能体群体可以更好的完成复杂的合作任务。多智能体间的涌现通信是智能体之间产生交流的一种方式。对通信协议语义的研究主要基于参考博弈(referential game),其是刘易斯信号博弈(lewis signaling game)的一个变体。该博弈由两个智能体(agent)参与,分别为说话者(speaker)和听者(listener),说话者和听者是两个神经网络,一般运行在gpu服务器上。在博弈中说话者获得一些私有的输入(通常是简单图像或符号),对其编码后通过离散的信道发送给听者,听者在接收到消息后对消息进行解码,从中复原出说话者的消息,若能从自身看到的备选中选出正确答案,即可获得奖励。智能体之间的通信协议随着上述博弈过程逐渐形成,并收敛稳定。
2、第一现有技术在研究离散信道下的多智能体通信问题,提出使用参考博弈作为研究多智能体通信协议语义的基本环境。研究者探究了两种结构的说话者:agnostic说话者、informed说话者的结构(见图1)对涌现的通信协议的影响。其中agnostic说话者仅根据图像生成的嵌入编码消息,informed说话者则在agnostic说话者的基础上加入了1维卷积层来对两幅图片的比对。在离散消息生成手段上,该研究提出将消息编码层的激活函数改成了带有温度参数的吉布斯分布,从中采样得到离散消息。实验结果表明,informed说话者在开展参考博弈时成功率更高,消息的纯度更高。当减少词汇表的大小时,通信信道容量不足以清晰的描述每一种图像类别,智能体倾向于将符号分配给有生命/无生命属性,其中有生命的对象如猫、狗等,无生命的对象如汽车、房子、路牌等,表现出了与人类交流中类似的效果。该研究还首次采用t-sne对嵌入层的特征进行可视化降维聚类,结果表明降维后表现出了明显的语义分离。
3、第二现有技术的研究以认知心理学中的一个基本假设——“交流中的听者与说者心智水平相近”为出发点,基于参考博弈开展对通信协议语义的研究。该研究使用包含多种几何体的合成数据集,设计了对等的智能体结构,见图2,以保证智能体的潜在能力接近。训练时,为保证两智能体的认知水平接近,在参考博弈的每一轮,两个智能体会先按照正常角色开展交流,然后再互换听者说者角色并开展交流。消息编解码器采用循环神经网络,以捕捉消息序列中词的上下文关系。该研究对通信协议进行了细致的分析,统计出了几何体属性在智能体开发出的通信协议中的对应关系。实验发现了智能体开发出的通信语义随着训练过程逐渐进化,最终收敛到稳定的、语义分离的通信协议的过程。
4、第三现有技术的研究则深刻揭示了智能体开发出的通信协议与自然语言的区别。自然语言遵循zipf’s law,即出现频次越大的词汇越短,但该研究却发现智能体开发出来的通信协议却表现出截然相反的倾向。该研究从基于一个符合幂律分布的人造数据集中采样作为输入数据,允许智能体发送可变长度的消息,观察智能体在产生的消息长度。实验中,研究者设计了多种消息长度上限,测试智能体在多种设定下发送的消息长度的分布,结果表明智能体开发出了一种违背zipf’s law的语言。研究者认为这是因为智能体在开发通信协议时没有最小化消息长度的内在压力,而人类语言为了表达的便捷性与易于理解性,常常含有这样的内在压力,当为speaker的消息长度引入惩罚项时,观察到通信协议向zipf’s law靠拢,但是会对收敛速度以及正确率产生负面影响。通过对智能体发送消息的上下文关系的进一步分析,研究者还发现智能体开发出的通信协议的二元语法分布非常倾斜,与自然语言有较大差异,这意味着智能体倾向于一遍又一遍的重复自己说过的话,直到达到最大消息长度。该研究首次将多智能体开发的通信协议于自然语言比较,为多智能体通信协议的研究提供了一个全新的视角。
5、第四现有技术的研究发现了“教育的压力”这一环境压力是如何诱导通信协议产生组合性这一良好的语言性质的。研究者指出,自然语言在演进过程中由于群体更迭,为了让语言更易传播,语言通常要易于传授,这种易于传授的压力就是“教育的压力”。实验同样基于参考博弈,研究者首先使用具备组合性的消息和不具备组合性的消息分别训练随机初始化的听者,结果表明,输入为具备组合性的消息的听者更快收敛,这表明高度结构化的语言易于教授;更进一步的,研究者使用在训练中周期性的重置听者(以模拟引入新的听者智能体)的方式来向说话者引入教育的压力,实验结果表明在这种教育的压力下,智能体开发出的通信协议更具组合性。该研究提出的通过重置听者来约束通信协议产生组合性的方法是目前诱导产生组合性较为有效的手段。
6、第五现有技术的研究主要关注通信协议的泛化性,研究者观察到在进行参考博弈时,智能体通常开发出人类难以理解的通信协议,该通信协议与图片中的实体对应。研究者进一步发现这种不可解释性可能来自于数据集的偏歧,当数据集没有特殊设计时,说话者往往只需要描述图片中某个像素的值这类低级别的感知特征就可以确保听者可以从备选答案中区分出正确答案。基于这个发现,研究者设计了三种级别的参考博弈的变体,见图3。第一级就是最基本的参考博弈,在该级别下说话者描述的图片和听者应当辨认出的图片完全一致;第二级是集合参考博弈,在该级别下说话者描述的图片与听者应当辨认出的图片会在实体的位置上有所变化,此时屏蔽了说话者通过发送像素颜色等低级感知特征完成任务的可能性;第三级概念参考博弈,在该级别下说话者描述的图片与听者应当辨认出的图片会在实体的位置、形状大小上有所变化,但是该图片中的实体仍然同属一个概念类别下面(如红色三角形、黄色正方形等),该级别要求说话者从概念级别上对图片进行描述。实验结果表明上述三种级别的任务中,智能体开发出的通信协议的泛化性逐渐增强。
7、第六现有技术从数学的层面给出了多智能体通信协议语义的研究常采用的参考博弈可能导致泛化性确实与过拟合的因素。具体来说,该研究证明了参考博弈的损失函数可以被分解为信息损失与共同适应损失。最小化信息损失约束说话者在描述输入数据时不产生二义性,最小化共同适应损失则确保说话者和听者的认知匹配,可以通过通信达成共识。上述的两种损失对应着两种过拟合,信息过拟合和共同适应过拟合,信息过拟合代表说话者只能在训练集上产生无二义的描述,共同适应过拟合代表说话者-听者只能在训练集上达成共识。研究者指出,共同适应过拟合是导致通信协议不可解释、缺少组合性的主要原因,研究者采用周期化重置听者的方式来减少共同适应过拟合。实验结果表明,当减少共同适应过拟合时,通信协议可以恢复良好的性质,并且观察到了泛化性与组合性有明显的正相关关系。该研究从数学层面证明了f.li等人提出的周期性重置听者的方法的有效性,为后续关注通信协议的组合性与泛化性的研究提供了理论基础。
8、认知推理基准测试:
9、pgm基准测试是计算机视觉领域的首个认知推理基准测试,图4给出了该基准测试中的一个实例,该基准测试的组织形式参照人类瑞文智力测试。该基准测试中每个实例包含8张上下文图片与8个备选答案。生成该基准测试的最基本要素是规则、物体与属性三元组,该三元组表示规则r应用在物体o的属性a上,规则集合包含渐进、逻辑(与、异或、或)和共现,物体包含图形(圆、正方形、三角形等)和直线,属性包含颜色、位置、数量等。每个问题实例按照难度等级由不同数量三元组生成,每个三元组同时作用在行维度和列维度上,因此正确答案需要同时满足第三行与第三列上的规则。该基准测试为了检验训练出的深度学习模型的泛化性能,对训练集和测试集引入了诸多差异,例如排除训练集中某些属性的取值以测试模型是否能习得属性维度上的内插性和外推性泛化、排除训练集中某些三元组来检验模型是否能够习得规则维度上的分布外泛化。该基准测试为开展认知推理任务的研究提供了有力的支持。
10、raven基准测试的组织形式同样参照人类瑞文智力测试,包含8个上下文图片和8个备选答案。该基准测试实例的每张图片由仅由几何图形组成,通过将规则(渐进、算术运算、共现等)应用在属性(形状、颜色、大小)上来生成认知推理问题。为了区分出不同的难度等级,该基准测试设计了从易到难的多种布局,见图2。该基准测试包含的逻辑数目适中,难度设置合理,因此被诸多后续研究采用。但该基准测试的备选答案生成算法存在缺陷,图3中(b)给出在raven基准测试中采用的备选答案生成算法,该算法通过随机修改正确答案的某个属性的取值来得到多个错误备选答案。该算法生成的备选答案有导致模型的过拟合的隐患,在求解认知推理问题时,只需要读取全部备选答案,选出备选答案中属性出现次数最多的取值作为答案的取值,就可以在不看到上下文信息的前提下推断出正确答案,此时模型并未真正习得推理能力。为了改进这个缺陷,提出了i-raven基准测试,该基准测试的备选答案生成方式见图3(c),其采用了类似二叉树的属性修改方式来生成备选答案,每个备选答案都有数目不同的属性被修改,因此无法仅通过观察备选答案推断出结果。
11、cvr是一个关注组合视觉推理的基准测试。在该研究中,研究者指出人类可以仅通过学习少量推理问题,就能较好的完成认知推理任务,而深度学习模型则需要学习大量样本才能习得推理能力,深度学习模型对样本的利用效率与人类有巨大差距。基于这个观点,该基准测试提出了带有组合性先验的数据生成方法,希望借助组合性来提高人工智能模型对样本利用效率。具体来说,该研究生成的基准测试实例见图4,每个实例包含四张图片,每张图片由多个形状不定的几何实体组成,每种几何实体有多种属性(形状、位置、大小、颜色等),同一张图片的不同实体之间存在规则,该任务的目标是从四张图片中选出与其余三张图片蕴含的规则不同的图片。该基准测试的规则可以根据集中基本规则组合产生,共可以组合出103种不同的规则。
12、上述现有技术存在以下缺陷:
13、(1)现有的多智能体间的涌现通信领域的技术在场景设置上存在缺陷,如图7。这些技术均采用的感知导向的设置,即说话者涌现描述高度组合的符号或简单合成图像内容的通信协议,听者执行感知导向的任务(辨别或者重建组合符号/图像中的物体)。该感知导向的设置使得智能体无法涌现认知导向的通信(说话者提炼并交流抽象规则,听者根据抽象规则解决推理问题)。认知导向的通信被语言学和认知心理学方面的文献认为是人类语言和智力进化的基础。
14、(2)现有的认知推理基准测试的缺陷首先在于规则组合不适合使用语言描述(存在二义性和冗余规则),这使得已有的认知推理基准测试无法直接应用到多智能体间的涌现通讯领域的研究,以实现探讨认知导向的交流。其次,现有的认知推理基准测试的备选答案生成方式存在缺陷,这使得通信过程存在过拟合的风险。
15、(3)现有的多智能体间的涌现通信领域的技术在模型训练方法上存在缺陷。在从感知导向的通信迈向认知导向的通信中,任务难度大大增加,这使得以往的模型训练方法无法在认知导向的通信过程达到最优效果,易在通信过程中陷入局部最优进而导致通信失败。
技术实现思路
1、发明人在进行涌现交流规则的多智能体通信研究时,发现上述缺陷(1)是由现有技术的博弈设定不合理导致。现有通信博弈的瓶颈一般在于把图片压缩为离散消息,再根据离散消息复原语言,这样的形式使得说话者在通信中描述的内容均为图片中易得的感知特征。发明人发现,解决该缺陷需要重新设计通信的博弈形式,即参考博弈的新变体——推理博弈。该博弈的关键点在于,切断了智能体通过感知导向的通信来完成任务的可能性,迫使说话者智能体推理并交流隐藏在多个上下文背后蕴含的规则。
2、发明人在为推理博弈设计认知推理基准测试时,发现现有的认知推理博弈基准测试存在上述缺陷(2)。已有基准测试在设计时并未考虑面向多智能体涌现通信这一全新的场景,因此在规则设计和控制通信过拟合的问题上考虑不足。发明人经过综合比对已有的认知推理基准测试,总结出无二义的规则集作为本发明提出的规则瑞文(rule-raven)基准测试的规则集。在深入分析了通信过拟合现象后,发明人通过充分混淆问题-备选答案面板层次上的规则以避免过拟合。
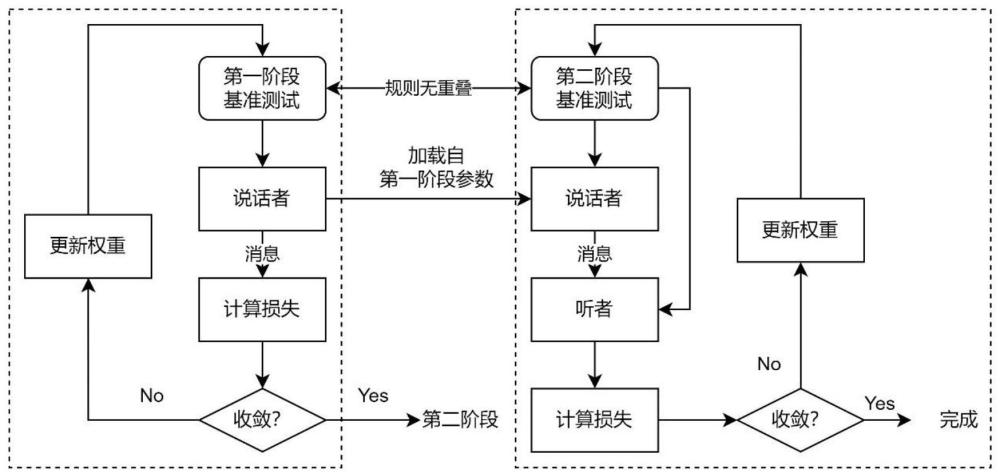
3、发明人在基于前述的推理博弈和规则瑞文基准测试训练说话者、听者智能体时,发现多智能体涌现通信领域的现有模型训练方法存在上述缺陷(3)。发明人发现,存在此缺陷的原因在于说话者与听者通信的早期,通信协议的语义和推理问题规则存在双向漂移的现象,这使得模型难以优化,最终导致听者倾向于完全忽视说话者发来的消息。据此,发明人提出一种两阶段的课程学习训练方法,由简到难逐步的训练两个智能体,以克服该缺陷。
4、具体来说,本发明提出了一种基于涌现交流规则的多智能体通信方法,其中包括:
5、初始步骤,用于获取提取上下文规则的神经网络模型作为说话者模型,获取根据该上下文规则进行推理的神经网络模型作为听者模型;
6、第一训练步骤,用于获取已标注规则标签的第一上下文面板,该说话者模型根据该第一上下文面板推理得到第一规则,并结合该第一上下文面板的规则标签构建第一损失函数,以训练更新该说话者模型,得到中间说话模型;
7、第二训练步骤,用于获取已标注规则标签的第二上下文面板、已标注答案标签的问题面板和备选答案面板,该中间说话模型将该第二上下文面板的第二规则发送至该听者模型,该听者模型根据该第二规则从该备选答案面板选择正确答案以回答该问题面板;根据该第二规则和该第二上下文面板的规则标签、该正确答案和该答案标签构建第二损失函数联合训练更新该中间说话模型和该听者模型,得到最终说话模型和最终听者模型;
8、智能通信步骤,用于通过该最终说话模型提取目标上下文面板的目标规则,该最终听者模型根据该目标规则从其候选答案中选择正确答案以完成指定任务。
9、所述的基于涌现交流规则的多智能体通信方法,其中该说话者模型和该听者模型均位于gpu服务器,该第一上下文面板、该第二上下文面板和该目标上下文面板均包括多个图像,该规则标签和该目标规则为图像类别,该问题面板和该指定任务为图像分类选择任务,该候选答案和该备选答案面板为该图像分类选择任务的备选图像。
10、所述的基于涌现交流规则的多智能体通信方法,其中该说话者模型包括第一感知模块、第一推理模块和消息编码器,该第一感知模块由多层感知机构成,该第一推理模块由共享分组的多层感知机构成,该消息编码器由长短期记忆人工神经网络构成;该听者模型包括消息解码器、第二感知模块和第二推理模块,该消息解码器由长短期记忆人工神经网络构成,该第二感知模块由多层感知机构成,该第二推理模块由共享分组的多层感知机构成;
11、第一感知模块将接收到的上下文面板编码为嵌入,送入该第一推理模块中推理出上下文面板蕴含的规则,使用该消息编码器将规则编码成离散消息;该消息解码器解码离散消息得到规则嵌入,使用该第二感知模块将该问题面板和该备选答案面板编码为嵌入,然后送入该第二推理模块中推理出每种问题-备选面板对蕴含的规则,与该规则嵌入计算相似度,得到备选面板的概率分布。
12、所述的基于涌现交流规则的多智能体通信方法,其中该备选答案面板生成过程包括:
13、获取包含规则r、上下文面板c和问题面板q的推理问题;对于每个面板属性,遍历该属性对应的规则空间,筛选出满足问题面板q的规则,构成当前面板属性对应的备选规则集合;将每个面板属性的备选规则集合进行笛卡尔积,构成问题面板q满足的规则空间,去除当前推理问题的规则r,构成负例规则空间;从该负例规则空间中随机不放回的采样负例面板数目的规则,并对于每条负例规则生成负例面板,得到的所有负例面板和正确答案面板构成该备选答案面板a。
14、本发明还提出了一种基于涌现交流规则的多智能体通信系统,其中包括:
15、初始模块,用于获取提取上下文规则的神经网络模型作为说话者模型,获取根据该上下文规则进行推理的神经网络模型作为听者模型;
16、第一训练模块,用于获取已标注规则标签的第一上下文面板,该说话者模型根据该第一上下文面板推理得到第一规则,并结合该第一上下文面板的规则标签构建第一损失函数,以训练更新该说话者模型,得到中间说话模型;
17、第二训练模块,用于获取已标注规则标签的第二上下文面板、已标注答案标签的问题面板和备选答案面板,该中间说话模型将该第二上下文面板的第二规则发送至该听者模型,该听者模型根据该第二规则从该备选答案面板选择正确答案以回答该问题面板;根据该第二规则和该第二上下文面板的规则标签、该正确答案和该答案标签构建第二损失函数联合训练更新该中间说话模型和该听者模型,得到最终说话模型和最终听者模型;
18、智能通信模块,用于通过该最终说话模型提取目标上下文面板的目标规则,该最终听者模型根据该目标规则从其候选答案中选择正确答案以完成指定任务。
19、所述的基于涌现交流规则的多智能体通信系统,其中该说话者模型和该听者模型均位于gpu服务器,该第一上下文面板、该第二上下文面板和该目标上下文面板均包括多个图像,该规则标签和该目标规则为图像类别,该问题面板和该指定任务为图像分类选择任务,该候选答案和该备选答案面板为该图像分类选择任务的备选图像。
20、所述的基于涌现交流规则的多智能体通信系统,其中该说话者模型包括第一感知模块、第一推理模块和消息编码器,该第一感知模块由多层感知机构成,该第一推理模块由共享分组的多层感知机构成,该消息编码器由长短期记忆人工神经网络构成;该听者模型包括消息解码器、第二感知模块和第二推理模块,该消息解码器由长短期记忆人工神经网络构成,该第二感知模块由多层感知机构成,该第二推理模块由共享分组的多层感知机构成;
21、第一感知模块将接收到的上下文面板编码为嵌入,送入该第一推理模块中推理出上下文面板蕴含的规则,使用该消息编码器将规则编码成离散消息;该消息解码器解码离散消息得到规则嵌入,使用该第二感知模块将该问题面板和该备选答案面板编码为嵌入,然后送入该第二推理模块中推理出每种问题-备选面板对蕴含的规则,与该规则嵌入计算相似度,得到备选面板的概率分布。
22、所述的基于涌现交流规则的多智能体通信系统,其中该备选答案面板生成过程包括:
23、获取包含规则r、上下文面板c和问题面板q的推理问题;对于每个面板属性,遍历该属性对应的规则空间,筛选出满足问题面板q的规则,构成当前面板属性对应的备选规则集合;将每个面板属性的备选规则集合进行笛卡尔积,构成问题面板q满足的规则空间,去除当前推理问题的规则r,构成负例规则空间;从该负例规则空间中随机不放回的采样负例面板数目的规则,并对于每条负例规则生成负例面板,得到的所有负例面板和正确答案面板构成该备选答案面板a。
24、本发明提出了一种服务器,其中包括所述的基于涌现交流规则的多智能体通信装置。
25、本发明提出了一种存储介质,用于存储执行所述基于涌现交流规则的多智能体通信方法的计算机程序。
26、由以上方案可知,本发明的优点在于:
27、与现有技术相比,该发明令基于深度学习技术的智能体可以涌现描述高级抽象语义的通信协议,提高了智能体的认知推理能力和表达抽象概念的能力。这两种能力对于构建可解释的、人类可交互的和具有泛化能力的人工智能是非常重要的。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22584.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表