一种语音驱动数字人方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 11:40:34
本技术涉及人工智能,尤其涉及一种语音驱动数字人方法、装置、设备及存储介质。
背景技术:
1、在对数字人驱动中,通常以语音内容和唇形对齐为主,很少考虑语音所带有的情绪对数字人的面部表情产生的影响,因此,得到的仅仅是唇形与语音内容对齐而面部没有任何表情的数字人。
2、若想要通过语音中的情绪改变数字人的面部表情,可以首先将唇形与语音内容对齐,然后再采用情绪编辑网络直接跟换原始的数字人的情绪,得到与语音情绪相匹配的数字人。
3、但是,此方法获得语音内容和语音情绪是通过相互独立的两个模块完成的,因此会导致无法生成平滑的视频序列。
技术实现思路
1、本技术实施例提供了一种语音驱动数字人方法、装置、设备及存储介质,用于强调语音情绪对数字人的驱动作用。
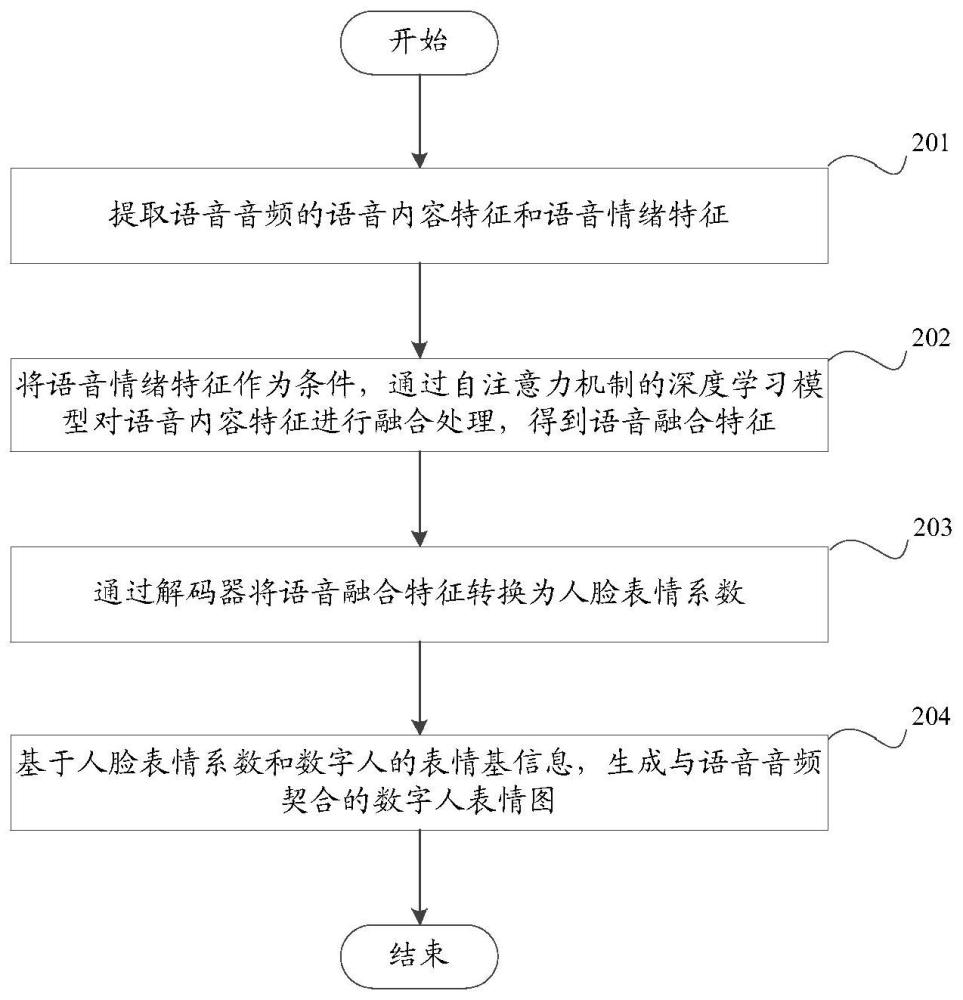
2、第一方面,本技术实施例提供一种语音驱动数字人方法,包括:
3、提取语音音频的语音内容特征和语音情绪特征;
4、将所述语音情绪特征作为条件,通过自注意力机制的深度学习模型对所述语音内容特征进行融合处理,得到语音融合特征;
5、通过解码器将所述语音融合特征转换为人脸表情系数;
6、基于所述人脸表情系数和数字人的基表情信息,生成与所述语音音频契合的数字人表情图。
7、本技术实施例中,通过提取语音音频的语音内容特征和语音情绪,实现了将语音情绪特征作为参考因素;通过将语音内容特征和语音情绪特征融合,得到语音融合特征不止包含语音内容,还包含了语音情绪特征;通过将语音融合特征映射为人脸表情系数,根据人脸表情系数生成数字人表情图,使得数字人表情图带有与语音音频相同的情绪,提升了数字人的自然性。
8、可选地,所述提取语音音频的语音内容特征和语音情绪特征,包括:
9、通过语音内容识别网络获得所述语音音频的语音内容特征,通过语音情绪识别网络获得所述语音音频的语音情绪特征,所述语音情绪识别网络是基于所述人脸表情系数损失训练获得的。
10、可选地,所述语音情绪识别网络通过如下方式训练得到,包括:
11、通过所述语音内容识别网络,得到样本音频的样本内容特征;并通过所述语音情绪识别网络,得到所述样本音频的样本情绪特征;
12、将所述样本内容特征和所述样本情绪特征拼接为样本融合特征;通过解码器将所述样本融合特征转换为预测人脸表情系数;
13、基于所述预测人脸表情系数和所述样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值;所述所述语音情绪识别网络损失值用于调整所述语音情绪识别网络直至满足训练终止条件。
14、本技术实施例中,将预测人脸表情系数与真实人脸表情系数构建损失函数,通过调整损失值优化语音情绪识别网络,使得语音情绪识别网络更加精准,因而得到更加准确的语音情绪特征。
15、可选地,所述样本音频包括第一样本音频和第二样本音频,所述第一样本音频与所述第二样本音频具有相同的样本内容特征和不同的样本情绪特征;
16、基于所述预测人脸表情系数和所述样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值,包括:
17、基于第一样本音频的预测人脸表情系数、第一样本音频的真实人脸表情系数、第二样本音频的预测人脸表情系数、第二样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值。
18、本技术实施例中,将样本音频中的情绪特征对调,针对第一样本音频和第二样本音频分别得到对应的损失函数,使得损失函数的构建包容性更强,使得最终的损失函数包含的范围更大,因而对模型的训练效果更好。
19、可选地,所述基于第一样本音频的预测人脸表情系数、第一样本音频的真实人脸表情系数、第二样本音频的预测人脸表情系数、第二样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值,包括:
20、基于所述第一样本音频的预测人脸表情系数和所述第一样本音频的真实人脸表情系数,得到第一损失值;
21、基于所述第二样本音频的预测人脸表情系数和所述第二样本音频的真实人脸表情系数,得到第二损失值;
22、根据所述第一损失值和所述第二损失值,确定所述语音情绪识别网络损失值。可选地,所述语音情绪识别网络损失值还包括第三损失值,所述第三损失值是基于语音情绪分类损失得到的。
23、可选地,样本音频中的任一子样本是通过如下方式得到的,包括:
24、通过多人以多种情绪表达相同的文字内容,从而得到多个样本视频;
25、对任一样本视频进行图片和音频分离,得到带有真实情绪标签的音频以及带有人脸表情的图片;通过所述带有人脸表情的图片获得所述图片的真实人脸表情系数,从而得到具有音频、真实情绪标签、图片和真实人脸表情系数的子样本。
26、本技术实施例中,通过获取多人多种情绪表达多种文字内容而得到的样本视频,使得样本量巨大且涵盖范围广,在对模型训练时,模型针对不同的样本使得得到的输出更加精准。
27、可选地,所述自注意力机制的深度学习模型具有多个串接的transformer模块;
28、将所述语音情绪特征作为条件,通过自注意力机制的深度学习模型对所述语音内容特征进行融合处理,得到语音融合特征,包括:
29、针对任一transformer模块,通过transformer模块中的自注意力模块对所述语音内容特征进行特征提取;通过transformer模块中的交叉注意力模块,将所述语音情绪特征与所述自注意力模块输出的语音特征进行融合,并输入至transformer模块中的前馈层,直至最后一个transformer模块处理后得到语音融合特征。
30、本技术实施例中,通过在transformer模块中不断添加语音情绪特征,使得语音融合特征包含了较强的语音情绪,因此数字人的表情中也添加了语音情绪,使得数字人的表情更加自然。
31、第二方面,本技术实施例提供一种语音驱动数字人装置,包括:
32、提取模块,用于提取语音音频的语音内容特征和语音情绪特征;
33、融合模块,用于将所述语音情绪特征作为条件,通过自注意力机制的深度学习模型对所述语音内容特征进行融合处理,得到语音融合特征;
34、转换模块,用于通过解码器将所述语音融合特征转换为人脸表情系数;
35、生成模块,用于基于所述人脸表情系数和数字人的基表情信息,生成与所述语音音频契合的数字人表情图。
36、可选地,所述提取模块具体用于:
37、通过语音内容识别网络获得所述语音音频的语音内容特征,通过语音情绪识别网络获得所述语音音频的语音情绪特征,所述语音情绪识别网络是基于所述人脸表情系数损失训练获得的。
38、可选地,所述提取模块具体用于:
39、通过所述语音内容识别网络,得到样本音频的样本内容特征;并通过所述语音情绪识别网络,得到所述样本音频的样本情绪特征;
40、将所述样本内容特征和所述样本情绪特征拼接为样本融合特征;通过解码器将所述样本融合特征转换为预测人脸表情系数;
41、基于所述预测人脸表情系数和所述样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值;所述语音情绪识别网络损失值用于调整所述语音情绪识别网络直至满足训练终止条件。
42、可选地,所述样本音频包括第一样本音频和第二样本音频,所述第一样本音频与所述第二样本音频具有相同的样本内容特征和不同的样本情绪特征;
43、基于所述预测人脸表情系数和所述样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值,包括:
44、基于第一样本音频的预测人脸表情系数、第一样本音频的真实人脸表情系数、第二样本音频的预测人脸表情系数、第二样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值。
45、可选地,所述基于第一样本音频的预测人脸表情系数、第一样本音频的真实人脸表情系数、第二样本音频的预测人脸表情系数、第二样本音频的真实人脸表情系数,确定所述语音情绪识别网络损失值,包括:
46、基于所述第一样本音频的预测人脸表情系数和所述第一样本音频的真实人脸表情系数,得到第一损失值;
47、基于所述第二样本音频的预测人脸表情系数和所述第二样本音频的真实人脸表情系数,得到第二损失值。
48、根据所述第一损失值和所述第二损失值,确定所述语音情绪识别网络损失值。
49、可选地,所述语音情绪识别网络损失值还包括第三损失值,所述第三损失值是基于语音情绪分类损失得到的。
50、可选地,所述提取模块具体用于:
51、通过多人以多种情绪表达相同的文字内容,从而得到多个样本视频;
52、对任一样本视频进行图片和音频分离,得到带有真实情绪标签的音频以及带有人脸表情的图片;通过所述带有人脸表情的图片获得所述图片的真实人脸表情系数,从而得到具有音频、真实情绪标签、图片和真实人脸表情系数的子样本。
53、可选地,所述自注意力机制的深度学习模型具有多个串接的transformer模块;
54、可选地,所述融合模块具体用于:
55、针对任一transformer模块,通过transformer模块中的自注意力模块对所述语音内容特征进行特征提取;通过transformer模块中的交叉注意力模块,将所述语音情绪特征与所述自注意力模块输出的语音特征进行融合,并输入至transformer模块中的前馈层,直至最后一个transformer模块处理后得到语音融合特征。
56、第三方面,本技术实施例提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一所述方法的步骤。
57、第四方面,本技术实施例提供了一种计算机可读存储介质,其存储有可由计算机设备执行的计算机程序,当所述程序在计算机设备上运行时,使得所述计算机设备执行上述任一所述方法的步骤。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22835.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。