数据处理方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 11:40:57
本公开涉及语音识别,具体而言,涉及一种数据处理方法、装置、电子设备及可读存储介质。
背景技术:
1、语音识别技术,也被称为自动语音识别(automatic speech recognition,asr),其目标是将语音中的词汇内容转换为计算机可读的输入。相关技术中采用基于人工智能技术的机器学习模型进行语音识别。为提高语音识别模型的准确性,通常需要大量的具有准确的标签的训练数据,因此,如何为语音识别模型提供丰富的有效训练数据成为亟待解决的问题。
2、在所述背景技术部分公开的上述信息仅用于加强对本公开的背景的理解,因此它可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、本公开的目的在于提供一种数据处理方法、装置、电子设备及可读存储介质,至少在一定程度上扩充可用于训练语音识别模型的数据集。
2、本公开的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本公开的实践而习得。
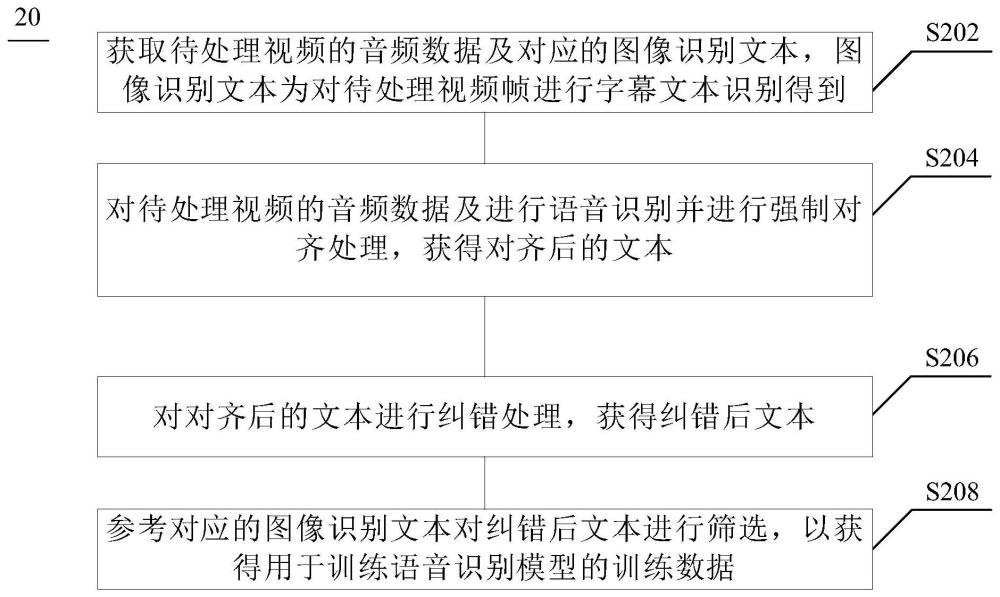
3、根据本公开的一方面,提供一种数据处理方法,包括:获取待处理视频的音频数据及对应的图像识别文本,所述图像识别文本为对待处理视频帧进行字幕文本识别得到;对所述待处理视频的音频数据及进行语音识别并进行强制对齐处理,获得对齐后的文本;对所述对齐后的文本进行纠错处理,获得纠错后文本;参考对应的图像识别文本对所述纠错后文本进行筛选,以获得用于训练语音识别模型的训练数据。
4、根据本公开的一实施例,所述待处理视频的音频数据及对应的图像识别文本包括多个音频文本对,所述音频文本对包括对一条字幕的视频帧进行字幕文本识别得到的图像识别文本及与该条字幕对应的时间区间的音频数据;对所述对齐后的文本进行纠错处理,获得纠错后文本,包括:对所述音频文本对的对齐后的文本进行分词处理,获得对齐后的文本的词列表;根据所述词列表判断所述音频文本对的对齐后的文本分词后是否大于三个词;若所述音频文本对的对齐后的文本分词后大于三个词,则利用三元语言模型对所述音频文本对对应的对齐后的文本进行打分,获得所述音频文本对对应的对齐后的文本为句子的概率;基于所述概率对所述音频文本对对应的对齐后的文本进行纠错处理,获得所述音频文本对的纠错后文本。
5、根据本公开的一实施例,对所述对齐后的文本进行纠错处理,获得纠错后文本,还包括:若所述音频文本对的对齐后的文本分词后不大于三个词,则利用所述二元语言模型对所述音频文本对对应的对齐后的文本进行打分,获得所述音频文本对对应的对齐后的文本为句子的概率;基于所述概率对所述音频文本对对应的对齐后的文本进行纠错处理,获得所述音频文本对的纠错后文本。
6、根据本公开的一实施例,基于所述概率对所述音频文本对对应的对齐后的文本进行纠错处理,获得所述音频文本对的纠错后文本,包括:若所述概率不大于预设概率阈值,获取所述词列表中各个词的候选替换词,所述候选替换词为根据对应词的拼音获得;利用语言模型对利用所述候选替换词替换后的词列表中的文本进行打分,确定替换后为句子的概率最高的词列表为所述音频文本对的纠错后文本。
7、根据本公开的一实施例,获取所述词列表中的各个词的候选替换词,包括:获取所述词列表中的各个词的拼音;获得与所述词列表中的各个词的拼音的近似度大于预设近似度阈值的相近音;获得所述词列表中的各个词的相近音的同音词,作为对应词的候选替换词。
8、根据本公开的一实施例,所述训练数据包括监督学习数据集和半监督学习数据集;参考对应的图像识别文本对所述纠错后文本进行筛选,以获得用于训练所述语音识别模型的训练数据,包括:获得所述纠错后文本与对应的图像识别文本相比的置信度;将置信度大于预设置信度阈值的纠错后文本及对应的音频数据加入所述监督学习数据集;将置信度不大于预设置信度阈值的纠错后文本及对应的音频数据加入所述半监督学习数据集。
9、根据本公开的一实施例,所述方法还包括:检测所述待处理视频的当前视频帧中出现文本的区域,获得所述当前视频帧的文本区域;判断所述当前视频帧的文本区域是否为预设字幕区域;若确定所述当前视频帧的文本区域为所述预设字幕区域,则以所述当前视频帧的时间戳为时间起点检测连续视频帧,获得所述当前视频帧的文本区域的字幕对应的时间区间;对所述当前视频帧的文本区域进行光学字符识别处理,获得所述当前视频帧的文本区域的字幕的图像识别文本;按照各条字幕对应的时间区间切分所述待处理视频的音频数据,以获得所述多个音频文本对。
10、根据本公开的一实施例,对所述待处理视频的音频数据及进行语音识别并进行强制对齐处理,获得对齐后的文本,包括:将所述音频文本对中的音频数据输入语音识别及强制对齐工具中的所述语音识别模型,获得对应语音识别文本;将所述音频文本对中的音频数据及对应的语音识别文本输入语音识别及强制对齐工具中的强制对齐模型,获得所述音频文本对的对齐后的文本。
11、根据本公开的再一方面,提供一种数据处理装置,包括:获取模块,用于获取待处理视频的音频数据及对应的图像识别文本,所述图像识别文本为对待处理视频帧进行字幕文本识别得到;语音转录模块,用于对所述待处理视频的音频数据及进行语音识别并进行强制对齐处理,获得对齐后的文本;文本纠错模块,用于对所述对齐后的文本进行纠错处理,获得纠错后文本;处理模块,用于参考对应的图像识别文本对所述纠错后文本进行筛选,以获得用于训练语音识别模型的训练数据。
12、根据本公开的再一方面,提供一种电子设备,包括:存储器、处理器及存储在所述存储器中并可在所述处理器中运行的可执行指令,所述处理器执行所述可执行指令时实现如上述任一种方法。
13、根据本公开的再一方面,提供一种计算机可读存储介质,其上存储有计算机可执行指令,所述可执行指令被处理器执行时实现如上述任一种方法。
14、本公开的实施例提供的数据处理方法,获取待处理视频的音频数据及对对应的待处理视频帧进行字幕文本识别得到的图像识别文本,对待处理视频的音频数据及进行语音识别并进行强制对齐处理,获得对齐后的文本,然后对对齐后的文本进行纠错处理,获得纠错后文本,并参考对应的图像识别文本对纠错后文本进行筛选,以获得用于训练语音识别模型的训练数据,从而可扩充语音识别模型的训练数据集。
15、应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本公开。
技术特征:1.一种数据处理方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述待处理视频的音频数据及对应的图像识别文本包括多个音频文本对,所述音频文本对包括对一条字幕的视频帧进行字幕文本识别得到的图像识别文本及与该条字幕对应的时间区间的音频数据;
3.根据权利要求2所述的方法,其特征在于,对所述对齐后的文本进行纠错处理,获得纠错后文本,还包括:
4.根据权利要求2或3所述的方法,其特征在于,基于所述概率对所述音频文本对对应的对齐后的文本进行纠错处理,获得所述音频文本对的纠错后文本,包括:
5.根据权利要求4所述的方法,其特征在于,获取所述词列表中的各个词的候选替换词,包括:
6.根据权利要求1至3中任意一项所述的方法,其特征在于,所述训练数据包括监督学习数据集和半监督学习数据集;
7.根据权利要求2或3所述的方法,其特征在于,还包括:
8.根据权利要求2或3所述的方法,其特征在于,
9.一种数据处理装置,其特征在于,包括:
10.一种电子设备,包括:存储器、处理器及存储在所述存储器中并可在所述处理器中运行的可执行指令,其特征在于,所述处理器执行所述可执行指令时实现如权利要求1-8任一项所述的方法。
11.一种计算机可读存储介质,其上存储有计算机可执行指令,其特征在于,所述可执行指令被处理器执行时实现如权利要求1-8任一项所述的方法。
技术总结本公开提供一种数据处理方法、装置、设备及存储介质,涉及语音识别技术领域。该方法包括:获取待处理视频的音频数据及对对应的待处理视频帧进行字幕文本识别得到的图像识别文本,对待处理视频的音频数据及进行语音识别并进行强制对齐处理,获得对齐后的文本,然后对对齐后的文本进行纠错处理,获得纠错后文本,并参考对应的图像识别文本对纠错后文本进行筛选,以获得用于训练语音识别模型的训练数据。该方法扩充了语音识别模型的训练数据集。技术研发人员:李方祝,付立,邓丽萍,范璐,吴友政,何晓冬受保护的技术使用者:京东科技信息技术有限公司技术研发日:技术公布日:2024/3/31本文地址:https://www.jishuxx.com/zhuanli/20240618/22871.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
音频处理方法和装置与流程
下一篇
返回列表