一种儿童语音识别的方法、电子设备及介质
- 国知局
- 2024-06-21 11:41:11
本发明属于人工智能,更具体地说,涉及一种儿童语音识别的方法、电子设备及介质。
背景技术:
1、语音识别技术是指将用户的语音转换为计算机可读的输入,广泛应用于工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等领域,是当前人工智能领域的研究热点之一。语音识别系统主要包含特征提取、声学模型,语言模型以及字典与解码等部分。特征提取是指将声音信号从时域转换到频域,为声学模型提供合适的特征向量,为了更有效地提取特征往往还需要对所采集到的声音信号进行滤波、分帧等音频数据预处理工作。声学模型通过对语音数据进行训练获得,输入时特征向量,输出为音素信息。字典则是实现字或词与因素的对应。语言模型通过大量文本信息进行训练,得到单个字或者词相互关联的概率。解码部分就是通过声学模型、字典、语言模型对特征提取后的音频数据进行文字输出。
2、语音识别技术性能的评价指标有许多,其中就包括英文的词错误率(word errorrate,wer)和中文的字错误率(character error rate,cer),词错率是指识别出来的词序列中的插入、替换和删除的词总个数除以标准的词序列中词的总个数的百分比。将词错率降低一直是提高语音识别性能的关键。现阶段的语音识别技术主要基于神经网络模型,常用的语音识别神经网络模型包括ctc、rnn-t和las三种模型。传统的神经网络模型在训练时很难把输出序列的长度与目标文本的长度匹配起来,解决这个问题需要人工将输入的频谱图划分成几个片段,每个片段对应最终输出的一个字或者词。与传统的神经网络模型相比,采用ctc作为损失函数的声学模型训练,是一种完全端到端的网络模型,不需要预先对数据做对齐,只需要输入序列和输出序列即可以训练。
3、儿童语音识别在对话交流、知识问答等儿童教育领域有着广泛的应用场景,虽然ctc模型可以识别各类人群的语音,但是对儿童语音识别的词错率相比成人更高。这是由于与成人相比,儿童语音中的共振峰位于较高频率处,由于儿童的声道较短且还在发育中,较短的声道和较高的基频也会由于谐波间隔较宽而导致频谱包络采样不足(因为语音识别处理是依赖输入信号的频谱表示),还有部分原因是因为儿童年纪小,有部分发音错误和说话不流利的原因和儿童语音低资源的情况(缺乏大的儿童语音语料库来训练鲁棒的语音识别模型),导致通用语音识别模型难以适配。另一方面则是儿童语音的数据资源较为稀缺,使得常规声学建模方法在该场景下很难奏效。
技术实现思路
1、1、要解决的问题
2、针对现有儿童语音识别成本高且识别效果差的问题,本发明提供一种儿童语音识别的方法、电子设备及介质。本发明的方法通过将成人语音转换成儿童语音,得到虚拟儿童语音的语料库,解决儿童语料库资源稀少的问题;最终儿童语音卷积神经网络的搭建在成人语音卷积神经网络的基础上进行更新,使时间成本与金钱成本都大幅度降低,且有效保障精度。
3、2、技术方案
4、为解决上述问题,本发明采用如下的技术方案。
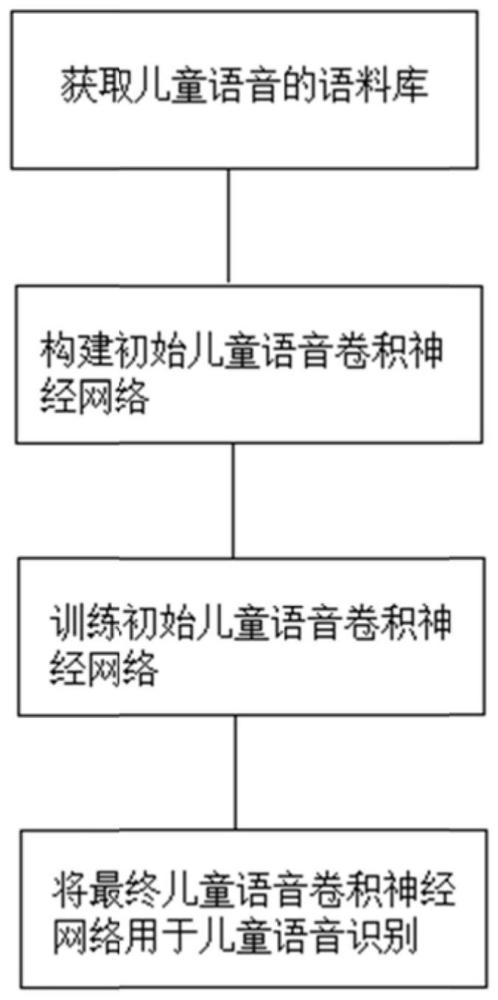
5、一种儿童语音识别的方法,包括以下步骤:
6、获取儿童语音的语料库:将成人语音的语料库中的成人语音进行转换成儿童语音,采用声音长度扰动方法对成人语音的语料库中的成人语音进行转换成儿童语音,得到虚拟儿童语音的语料库;
7、构建初始儿童语音卷积神经网络:将成人语音卷积神经网络的隐含层参数进行迁移,形成初始儿童语音卷积神经网络;
8、训练初始儿童语音卷积神经网络:将虚拟儿童语音的语料库输入至初始儿童语音卷积神经网络中进行适应性训练,训练时保持部分迁移过来的参数不变,仅更新最后一个隐含层中全连接层参数和输出层中softmax激活函数的参数,得到最终儿童语音卷积神经网络;
9、将最终儿童语音卷积神经网络用于儿童语音识别。
10、更进一步的,声音长度扰动方法包括采用扭曲因子α随机的对成人语音的语料库中的成人语音进行频率扭曲,将这些成人语音的成人频率映射到新的儿童频率上,其具体公式如下:
11、
12、其中,f′为儿童频率,f为成人频率,s是采样频率,fhi是选择的边界频率。
13、更进一步的,所述扭曲因子α的取值为:(1<α<1.2)。
14、更进一步的,在最终儿童语音卷积神经网络用于儿童语音识别之前包括对最终儿童语音卷积神经网络进行测试:将真实儿童语音的语料库输入至最终儿童语音卷积神经网络中进行测试;若测试通过,则用于儿童语音识别;若测试不通过,则将真实儿童语音的语料库输入至初始儿童语音卷积神经网络中进行适应性训练,再进行测试,如此反复,直至测试通过。
15、更进一步的,所述成人语音卷积神经网络包括输入层,输出层和若干个依次连接的隐含层;且成人语音卷积神经网络为基于成人语音训练好的成人语音卷积神经网络。
16、更进一步的,所述初始儿童语音卷积神经网络包括输入层,输出层和若干个依次连接的隐含层;所述若干个依次连接的隐含层的参数与所述成人语音卷积神经网络中若干个依次连接的隐含层的参数相同。
17、更进一步的,所述初始儿童语音卷积神经网络中的输入层的数据可以为虚拟儿童语音的语料库和/或真实儿童语音的语料库。
18、更进一步的,对初始儿童语音卷积神经网络进行训练时包括:
19、调用函数对隐含层进行冻结,此处的隐含层指的是除了最后一个隐含层之外的若干个隐含层;
20、重新定义最后一个隐含层的参数,也即重新定义最后一个全连接层和softmax激活函数;
21、重新定义adam优化器和ctcloss损失函数;
22、调用虚拟儿童语音的语料库,进行学习训练,得到最终儿童语音卷积神经网络。
23、一种儿童语音识别的电子设备,采用如上述任一项所述的儿童语音识别的方法。
24、一种存储有计算机程序的计算机可读存储介质,所述计算机程序被处理器执行时实现上述任一项所述的儿童语音识别的方法。
25、3、有益效果
26、相比于现有技术,本发明的有益效果为:
27、(1)本发明通过将成人语音转换成儿童语音,得到虚拟儿童语音的语料库,解决了儿童语料库资源稀少的问题;且直接将成人语音通过声音长度扰动方法转换成儿童语音,能够精准的使得成人语音的频率接近儿童语音的频率,提高转换过程的准确性;随后最终儿童语音卷积神经网络的生成在成人语音卷积神经网络的基础上进行最后一个隐含层和softmax激活函数的参数更新,使得无需重新搭建一个全新的卷积神经网络进行面对儿童使用,有效节约了整体的成本投入,并且也节约了重新搭建卷积神经网络的时间,使得时间成本与金钱成本都大幅度降低,且能够有效保障精度;整个方法操作简便,使得成本与性能得到很好的兼顾;
28、(2)本发明通过对扭曲因子的取值进行限定,在该取值范围内使得成人语音的共振峰频率更加接近儿童语音的共振峰频率,并且通过扭曲因子随机对成人语音的语料库中的成人语音进行频率扭曲,保证对成人语音的语料库中的成人语音尽可能做到进行全覆盖,使得虚拟儿童语音的语料库建立更加全面,继而有效保障后续训练的准确性;
29、(3)本发明在得到最终儿童语音卷积神经网络后会对其进行测试,测试这一步骤的添加则进一步提高了最终儿童语音卷积神经网络的准确性,使其在面对语音识别时能够更加准确的输出;同时当测试不通过时,会将真实儿童语音的语料库输入至初始儿童语音卷积神经网络中进行训练,增加源头数据的真实性,继而进一步增加训练过程的准确性,从而保障最终儿童语音卷积神经网络的识别准确性;
30、(4)本发明中成人语音卷积神经网络采用现有的基于成人语音训练好的,节省了重新搭建的时间,节约时间成本与金钱成本;且初始儿童语音卷积神经网络中的输入层数据可以为真实儿童语音的语料库,从源头上增加了数据输入的准确性,继而增加了训练过程的准确性;且输入层数据也可以为虚拟儿童语音的语料库和真实儿童语音的语料库的结合,即保证准确性又使得数据来源广泛且全面。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22906.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。