一种基于注意力机制的单麦克风声学成像方法与流程
- 国知局
- 2024-06-21 11:41:56
本发明涉及人工智能、声学成像、机器视觉、声音图像跨模态,特别地,涉及一种基于注意力机制的单麦克风声学成像方法。
背景技术:
1、声学成像技术是一种通过麦克风阵列采集声音并确定生源位置,之后在使用相机采集到的图像上对应位置显示出声源及其强弱的一种方法。广泛应用在管道气密性检测(漏气检测)、电器线路板局部漏电检测、车辆噪声、振动与声振粗糙度标定与优化、低空无人机预警、爆炸定位等领域。注意力机制最早来自仿生学研究,是一种对人类视觉工作方式的模拟,主要模拟人眼视网膜如何关注重要的输入部分,以及如何分配有限的资源给重要的部分。这种模拟方式主要采用编码-解码神经网络实现。注意力机制主要分为两种——硬注意力机制(hard attention)以及软注意力机制(soft attention)。
2、传统的声学成像技术主要分为三类,一是基于可控波束形成(beamforming)的方法;二是基于高分辨率谱估计的方法;三是基于声达时延差(tdoa)的方法,目前市场上主流方法为可控波束形成方法。可控波束形成技术是将各麦克风阵元采集来的信号进行加权求和形成波束,通过搜索声源的可能位置来引导该波束,修改权值使得传声器阵列的输出声源位置的信号功率最大。高分辨率谱估计的方法包括了自回归模型、最小方差谱估计和矩阵特征值分解,所有这些方法都通过获取传声器阵列的信号来计算空间谱的相关矩阵。声达时间差(tdoa)的定位技术,使用特殊的声达传感器(原理类似tof飞行时间相机)进行,先进行声达时间差估计,并从中获取传声器阵列中阵元间的声延迟;再利用获取的声达时间差,结合已知的传声器阵列的空间位置进一步定出声源的位置。
3、上述方法存在以下三个问题:一是可控波束形成方法往往依赖大型阵列麦克风,通常麦克风数达上百个,体积巨大,造价高昂。同时,大型阵列麦克风中的各个阵元灵敏度有差异,误报、虚假检测情况时有发生,精度鲁棒性不高;二是高分辨率谱估计方法依赖大量计算,其中涉及矩阵特征值分解、最小回归等,对算力要求极大,且当匹配较大阵列麦克风时,这种方法的运算量会进一步升高,非常容易导致定位不准确;三是声达时间差定位依赖高灵敏度的声达设备,成本较高,且声达在测量远距离物体时易受影响,大型设备的声源检测一般不具备近距离检测的条件,因此声达的使用场景有限。
4、声学成像技术的难点在于:一是受多路径传播和环境噪声干扰。声音在传播过程中会受到多路径传播的影响,导致声音信号在不同路径上反射、散射和衰减,从而使得声源的定位和声场重构变得复杂。此外,环境噪声也会对声音信号造成干扰,进一步降低成像的准确性。二是受限于麦克风阵列设计和布置情况。麦克风阵列的设计和布置对声学成像的效果具有重要影响。合理的麦克风阵列设计可以提高声源定位的准确性和分辨率,但如何选择合适的麦克风类型、数量、位置和方向是一个挑战性问题。三是难以做到高实时性和低系统复杂性。在某些应用场景中,要求声学成像系统具有实时性能。实时性要求对于数据采集、处理和算法运行速度都提出了较高的要求。此外,声学成像系统的复杂性也是一个挑战,需要考虑硬件设计、软件开发、系统集成等方面的问题。
5、解决上述问题的意义为:一是提高声学成像的准确性:传统的声学成像方法主要依赖于麦克风阵列采集的声音信号,但由于环境噪声、多路径传播等因素的干扰,准确地确定声源位置和强度是一项挑战。通过音视频跨模态学习,结合相机采集的图像信息,可以提供额外的视觉线索,帮助准确定位声源,并更准确地估计声源的强度。二是扩展声学成像的应用领域:传统的声学成像主要应用于声源定位和声场重构等领域。而音视频跨模态学习可以将声音和图像两种不同的传感器信息进行融合,为声学成像技术带来更多的应用可能性。例如,在智能会议系统中,结合麦克风阵列和摄像头,可以实现精确的语音定位和人脸识别,提供更好的会议体验。三是降低设备成本和复杂性:传统的声学成像系统通常需要专门的麦克风阵列和处理设备。而音视频跨模态学习可以利用已有的音频和视频设备,无需额外的硬件开销,降低了成本和设备复杂性。这使得声学成像技术更易于应用于各种场景,如智能手机、智能音箱等消费电子产品。
技术实现思路
1、本发明提供了一种基于注意力机制的单麦克风声学成像方法,是一种结合跨模态声音图像匹配和声音引导的图像注意力机制的声学图像生成方法,通过声音引导的视觉注意力机制进行声源定位,有效地提升了声源地位即声学图像生成的准确性和鲁棒性,并极大地降低了硬件成本。
2、本发明的技术方案如下:
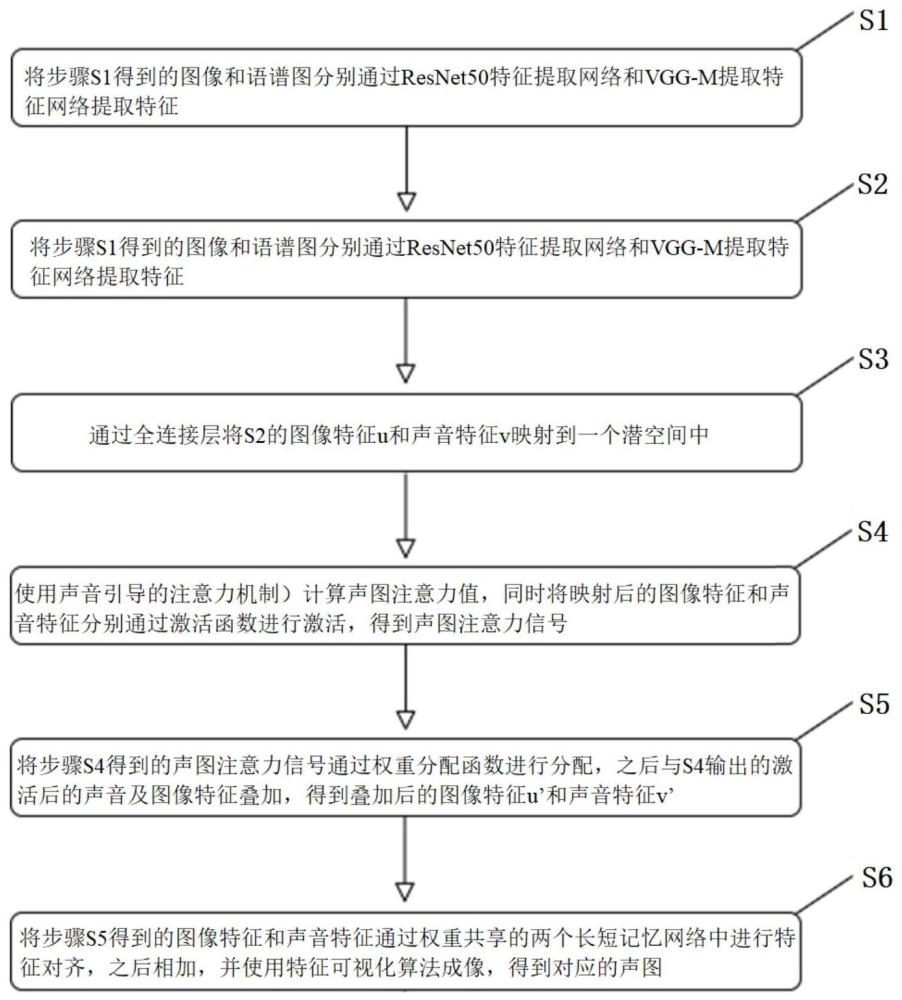
3、本发明的基于注意力机制的单麦克风声学成像方法,包括以下步骤:s1.对声音信号进行预处理得到相应的语谱图,同时对图像数据进行预处理;s2.将步骤s1得到的图像和语谱图进行提取特征,得到图像特征和声音特征;s3.通过全连接层将步骤s2得到的图像特征和声音特征映射到一个潜空间中;s4.使用声音引导的注意力机制计算声图注意力值,同时将映射后的图像特征和声音特征分别通过激活函数进行激活,得到声图注意力信号;s5.将声图注意力信号通过权重分配函数进行分配,之后与s4输出的声音及图像特征叠加,得到叠加后的图像特征和声音特征;s6.将叠加后的图像特征和声音特征通过权重共享的两个长短记忆网络中进行特征对齐,之后相加,并使用特征可视化算法成像,得到对应的声图。
4、可选地,在上述基于注意力机制的单麦克风声学成像方法中,在步骤s1中,对图像和语谱图进行预处理增强数据,并通过快速傅里叶变换生成语谱图,再对语谱图进行对比度增强和锐化处理,抑制背景噪音。
5、可选地,在上述基于注意力机制的单麦克风声学成像方法中,在步骤s2中,图像使用残差网络resnet50特征提取网络来提取特征,语谱图使用卷积神经网络模型vgg-m提取特征网络来提取特征,之后经由一个全连接层将特征映射到一个潜空间,输出图像特征和声音特征。
6、可选地,在上述基于注意力机制的单麦克风声学成像方法中,在步骤s4中,通过声音引导的注意力机制计算声图注意力值,采用双线性模型对输入信息进行“打分”,之后通过归一化指数函数求取对应的注意力分布,接着进行加权平均就得到声图注意力信号。
7、可选地,在上述基于注意力机制的单麦克风声学成像方法中,在步骤s6中,将步骤s5的输出送入两个权重共享的长短时记忆网络中进行特征对齐,对齐后的声音和图像特征经过叠加,并通过特征可视化算法进行成像就得到了对应的声图。
8、根据本发明的技术方案,产生的有益效果是:
9、本发明方法采用跨模态声音图像匹配技术和声音引导的图像注意力技术构建神经网络,训练声学成像模型。该方法对硬件要求较低,仅需一个麦克风和单目相机即可对图像上的声源位置进行识别,且网络在边缘端进行推理的算力要求较低,手机等手持移动终端设备即可满足算力要求。本方法采用的跨模态声音图像匹配技术可以为两段异步采集的声音和图像序列进行精准定位,并获取到相同表达所在的位置。同时,本发明采用的声音引导的视觉注意力机制可以根据声学信号特征,利用跨模态声音图像匹配技术和声音引导的注意力机制,使用单一麦克风单元,即可在图像上找出对应声源,并生成对应的声学图像。本发明方法避免了采用庞大规模的麦克风阵列,也不依赖特殊的声达装置,同时训练好的声学成像模型在边缘端使用时对算力的要求相对较低。最后,本发明方法由于使用深度学习进行训练,采用端到端的方式进行声学成像,因此其成像稳定性和精准性都较传统方法有所提升。
10、为了更好地理解和说明本发明的构思、工作原理和发明效果,下面结合附图,通过具体实施例,对本发明进行详细说明如下:
本文地址:https://www.jishuxx.com/zhuanli/20240618/22992.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表