一种面向语音数据的身份隐私保护方法及系统
- 国知局
- 2024-06-21 11:43:44
本发明涉及身份隐私保护,具体是一种面向语音数据的身份隐私保护方法及系统。
背景技术:
1、语音隐私保护技术是指保留原语音的音质和可懂度的情况下,隐藏说话人身份,在个人隐私保护领域具有非常重要的应用。
2、目前,在语音隐私保护方法中,通常采用将说话人表征和语义信息解耦,而后通过修改说话人表征的方法,来实现匿名化。比如采用修改说话人表征x-vector的方法。它使用外部说话人集合中生成的x-vector来取代目标说话人的x-vector,从而进行匿名化,保护身份隐私信息。该方法对于给定的目标说话人,通过从外部x-vector集合中根据既定规则选出一组候选x-vector并计算其均值,将该均值矢量作为匿名化x-vector,代替原语音x-vector,并重新合成得到匿名化语音,来实现匿名化。但是这种方法得到的匿名化x-vector和原语音x-vector往往差异较大,对合成得到的匿名化语音的音质和可懂度造成了较大的影响,并且这种方法修改x-vector阶段的随机性较差,易受到攻击者的针对性攻击,对匿名化语音的安全性也产生了不利的影响。
技术实现思路
1、为了克服现有技术的不足,本发明提出了一种面向语音数据的身份隐私保护方法及系统,通过向x-vector中添加对抗性扰动来修改x-vector,实现匿名化,该方法在可以在修改x-vector的过程中,增加修改x-vector阶段的随机性并降低匿名化x-vector和原语音x-vector之间的差异,从而在提高安全性的同时,降低对匿名化语音的音质和可懂度的影响。
2、为了实现上述目的,本发明具体采用的技术方案如下:
3、一种面向语音数据的身份隐私保护系统,包括:
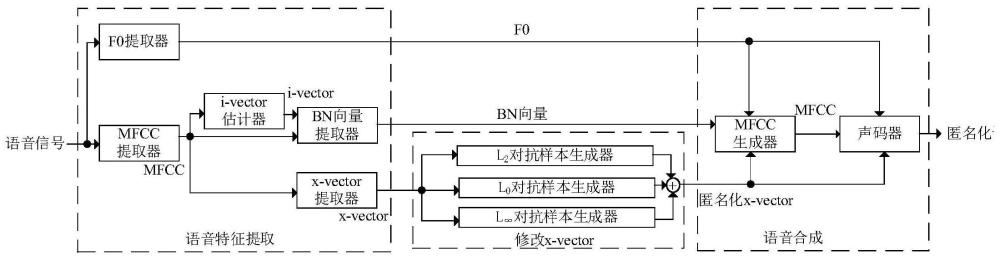
4、语音特征提取模块,通过f0(基音频率)提取器、bn(瓶颈向量)提取器和x-vector提取器分别提取用户的语音信号的f0、bn向量和x-vector;
5、修改x-vector模块,用于将得到的x-vector通过三个独立训练的对抗样本生成器,生成匿名化x-vector;
6、语音合成模块,用于将f0、bn向量和匿名化x-vector通过mfcc生成器生成mfcc,并将生成的mfcc与f0、匿名化x-vector一同输入声码器,合成匿名化语音。
7、进一步地,所述的f0提取器利用语音的时域信息,通过计算自相关函数和变长平均幅度差函数确定基音周期,进而确定f0参数;所述的mfcc提取器利用梅尔频率滤波器组提取mfcc,得到的mfcc通过i-vector估计器和x-vector提取器分别估计i-vector和提取x-vector,再将得到的mfcc和i-vector,通过bn向量提取器提取bn向量。
8、进一步地,所述的三个对抗样本生成器通过建立不同的损失函数,计算各自损失函数对x-vector的梯度,向x-vector中添加基于梯度和扰动系数的对抗性扰动,使得x-vector沿负梯度方向更新,迭代更新x-vector,直至趋于收敛,来生成对抗样本,并采用平行集成的方法融合三个对抗样本生成器的输出,作为匿名化x-vector,该匿名化x-vector可以使得攻击者的说话人分类器误分类,使其无法分辨原说话人身份,达到匿名化的目的。
9、进一步地,所述的i-vector估计器训练时,从语音库中提取任意n个说话人的语音数据,用高斯混合模型(gmm)为每个说话人语音的特征参数空间进行概率分布密度建模,并将每个高斯混合模型(gmm)的高斯分量的均值矢量串联,投影到全局差异空间来计算其对应的i-vector,最终得到由n个gmm模型和n个对应的i-vector组成的i-vector估计器;
10、进一步地,所述的x-vector提取器由帧级别提取模块、统计池化层、句子级别提取模块和输出层组成,训练时,对语音库中的n个说话人的语音数据,提取各帧语音的mfcc,将一句话的各帧mfcc参数作为输入,对应的说话人身份作为标签,训练一个tdnn结构的自动说话人验证器,作为x-vector提取器,将tdnn网络的一个全连接层的输出作为x-vector。
11、进一步地,所述的bn向量提取器由tdnn-f线性层和输出层组成,训练时,对语音库中的n个说话人的语音数据,提取各帧的mfcc,将每个说话人的每帧的mfcc和说话人的i-vector串联并作为网络的输入,每帧的音素序列作为标签,训练一个tdnn-f结构的自动语音识别器,作为bn向量提取器,将网络的一个线性层的输出作为bn向量。
12、进一步地,所述的mfcc生成器由全连接层、双向长短时记忆网络层(bi-lstm)、自回归层、长短时记忆网络层(long short-term memory,lstm)和highway-postnet层组成,将f0、bn向量和x-vector串联,作为全连接层的输入,全连接层对输入进行线性变换来提取特征并使用relu函数对特征进行非线性变换,bi-lstm层对特征序列进行建模,捕捉特征序列中的上下文信息,自回归层通过递归的方法利用上一时刻的输出来生成当前时刻的输出,从而实现输出序列的生成;lstm层通过输入门、遗忘门、细胞状态和输出门的组合,捕捉并传递序列数据中的信息;highway-postnet层通过highway层的门控机制来控制信息的传递,同时使用postnet层对生成的mfcc进行后处理,最终输出生成的mfcc。
13、进一步地,对语音库中的n个说话人的语音数据,提取mfcc、x-vector和f0作为声码器输入,将语音信号时间序列作为标签,训练声码器;所述的声码器是一个神经源滤波器,由条件模块、源模块、滤波器模块三部分组成,可以将输入的声学特征转换为输出的语音波形;条件模块由bi-lstm层、卷积层和上采样模块组成,对f0直接进行上采样,对mfcc和x-vector序列通过bi-lstm层和卷积层后,再通过上采样,变为长度为t的语音特征序列,源模块接收到通过上采样f0得到的fk序列后,生成基于正弦的激励信号,发送到滤波器模块。
14、本发明还提供了一种面向语音数据的身份隐私保护方法,该保护方法采用上述的面向语音数据的身份隐私保护系统实现身份隐私的保护;当用户使用系统时,只需要输入语音数据,系统首先对语音信号进行说话人表征和语义信息的解耦,然后通过三个独立训练的对抗样本生成器,分别向x-vector中添加基于不同范数约束的对抗性扰动,修改说话人表征x-vector,并采用平行集成的方法融合三个对抗样本生成器的输出作为匿名化x-vector,将该匿名化x-vector替代原语音x-vector,重新合成,用户就可得到匿名化的语音数据。
15、本发明所述的一种面向语音数据的身份隐私保护方法,包括如下步骤:
16、1)对于任意的用户,输入一段语音,语音信号首先通过高通滤波器对高频部分进行预加重,得到频谱幅度相对平坦的语音信号,然后系统使用固定长度的滑动窗口将预加重信号分割成短时帧;将信号分割成短时帧后,每帧信号乘以一个汉明窗函数后,每帧信号通过快速傅里叶变换(fast fourier transform,fft),得到每帧信号的频谱;
17、2)预处理后的信号通过f0提取器,从信号中提取每帧信号的基音频率;f0提取器首先计算第i帧信号xi(m)的短时自相关函数,随后计算第i帧信号xi(m)的变长平均幅度差函数,最后计算准周期函数当在设定的基音频率范围内取最大值时,采样频率fs除以此时的时延τ即为第i帧信号的f0;
18、3)预处理后的信号通过mfcc提取器,利用梅尔频率滤波器组提取mfcc,得到的mfcc通过i-vector估计器估计用户的i-vector;i-vector估计器首先计算mfcc序列在n个gmm模型下的概率,得到n个概率后,找出n个概率中的最大值所对应的说话人i,说话人i对应的i-vector,即为估计的用户i-vector;
19、4)得到的mfcc通过x-vector提取器将网络中句子级别特征提取模块的第一个全连接层的输出作为说话人特征x-vector,提取x-vector;
20、5)得到的mfcc和估计的i-vector通过bn向量提取器,通过网络中将最后一个线性层的输出作为bn向量,提取bn向量;
21、6)提取的x-vector通过三个基于不同范数约束的对抗样本生成器,通过向x-vector添加基于不同范数约束的对抗性扰动,来生成匿名化x-vector;具体地,首先为匿名化x-vector随机选定伪说话人标签t(伪说话人标签t不能为真实说话人标签),然后l2范数对抗样本生成器通过向输入x中添加基于l2范数约束的对抗性噪声,生成对抗样本x′2,即:
22、x′2=x+δ2 (1)
23、具体来说,l2范数对抗样本生成器首先计算损失函数lossl2,t对x的梯度,损失函数为:
24、
25、其中,损失函数的第一项通过最小化x′2和x的欧氏距离来限制x′2和x的差异,第二项通过鼓励分类器将对抗样本x′2分类为伪说话人t,来保证扰动效果,其中,f(x′2)i为分类器f(·)将对抗样本x′2分类为说话人i的概率,为除伪说话人t外,其他说话人分类概率的最大值;exp(·)为指数函数,log(2)的底数为2,其值为1;当损失函数第二项小于等于0时,认为分类器将对抗样本x′2误分类为伪说话人t;b为超参数用来调节l2范数限制和扰动效果的权重;
26、计算损失函数对x的梯度后,通过反向传播,向x中添加基于l2范数约束的对抗性扰动,使得x沿负梯度方向进行更新,生成对抗样本x′2,并经过数轮迭代,使得x′2趋于收敛,即:
27、
28、
29、其中,lossf,t(x′2,t)表示,针对分类器f(·),伪说话人标签为t,扰动生成的对抗样本为x′2的损失函数;为微分矢量算符,表示,输入矢量x的每一个元素,对损失函数lossf,t(x′2,t)求偏导;α是每次迭代的步长;设置为0.001,sign()是符号函数,它将输入的实数值作为参数,如果输入大于0,则返回1;如果输入等于0,则返回0;如果输入小于0,则返回-1;
30、7)l0范数对抗样本生成器通过向x中添加基于l0范数约束的对抗性噪声,生成对抗样本x′0,即:
31、x′0=x+δ0 (5)
32、具体来说,l0范数对抗样本生成器通过限制修改元素的数量,限制x′0和x的差异,l0范数对抗样本生成器首先通过隐私风险值估计器估计输入x中各元素的隐私风险值,并将每个元素的隐私风险值进行降序排序;排序前面的隐私风险值较大元素的隐私风险值之和占全部元素隐私风险值之和的k%时,隐私风险值较大元素所构成的集合定义为隐私风险区域;通过仅允许对隐私风险区域内元素进行修改,限制修改元素的数量;
33、l0范数对抗样本生成器随后计算损失函数lossl0,t对隐私风险区域内元素的梯度,损失函数为:
34、
35、损失函数鼓励分类器将x′0分类为伪说话人标签t,来保证扰动效果;计算损失函数对隐私风险区域内元素的梯度后,通过反向传播,向x中添加对抗性扰动,使得x沿负梯度方向进行更新,生成对抗样本x′0,并经过数轮迭代,使得x′0趋于收敛,即:
36、
37、
38、8)l∞范数对抗样本生成器通过向x中添加基于l2范数约束的对抗性噪声后,进行最大值裁剪,生成对抗样本x′∞,即:
39、x′∞=x+clip(δ2) (9)
40、具体来说,l0范数对抗样本生成器通过限制修改元素的最大幅度,限制x′∞和x的差异,l0范数对抗样本生成器首先计算损失函数lossl∞,t对x的梯度,损失函数为:
41、
42、其中,损失函数的第一项通过最小化欧氏距离适当限制x′∞和x的差异,第二项鼓励分类器将x′∞分类为伪说话人标签t;c为超参数用来调节l2范数限制和扰动效果的权重;计算损失函数对x的梯度后,通过反向传播,向x中添加基于l2范数约束的对抗性扰动后,进行最大值裁剪,使得x沿负梯度方向进行更新,生成对抗样本x′∞,并经过数轮迭代,使得x′∞趋于收敛,即:
43、
44、
45、9)然后使用平行集成的方法融合三个对抗样本生成器的输出,即:
46、x′=αx′0+βx′2+γx′∞ (13)
47、通过梯度下降法确定α,β,γ的取值,具体来说,计算损失函数对于α,β,γ的梯度,损失函数为:
48、
49、损失函数鼓励分类器将x′分类为伪说话人标签t,来保证扰动效果;计算损失函数对α,β,γ的梯度后,通过反向传播,使得α,β,γ沿负梯度方向进行更新,并经过数轮迭代,使得α,β,γ趋于收敛,即:
50、
51、
52、
53、12)最终f0,bn向量,匿名化x-vector通过mfcc生成器,生成mfcc,并与f0、匿名化x-vector一同输入到声码器合成匿名化语音。
54、本发明具有以下的特点和有益效果:
55、1)通过添加对抗性扰动,解决了传统修改x-vector算法中,匿名化x-vector和原语音x-vector差异较大并且匿名化过程的随机性差的问题。在修改x-vector过程中,对抗性扰动大小受到范数约束。在保证安全性的同时,尽量保留数据的可用性,避免不必要的信息损失,更好地保留了原语音的音质和可懂度。
56、2)在添加基于l0范数的对抗扰动时,通过隐私风险值估计器估计隐私风险区域,相比于传统的估计方法,更准确地估计x-vector的隐私风险区域。
57、3)在添加对抗性扰动时,使用了基于不同的范数约束的对抗性扰动,并使用平行集成的方法融合,增加了匿名化的鲁棒性使得攻击者不易使用蒸馏防御等手段消除添加的扰动,增加了匿名化的安全性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23166.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表