歌声转换模型的训练方法、歌声转换方法、系统和介质与流程
- 国知局
- 2024-06-21 11:44:00
本发明涉及歌唱处理,尤其是一种歌声转换模型的训练方法、歌声转换方法、系统和介质。
背景技术:
1、歌声是一种人类情感表达和情感交互的重要表达方式。歌声转换(变声)处理是输入一段歌声,输出另外一段歌声,但是,这两段歌声有些不同。歌声转换过程中希望保留歌声的内容和技巧,改变歌唱者的音色。例如,在定制目标对象a的歌声需求下,现实当中目标对象a日常说话或朗读的语音数据往往比歌唱数据成本更低,从而造成歌声数据低资源甚至零资源数据的困境,并且,唱歌的声音通常比说话的语音更难建模。现有算法和低资歌声数据或零资源歌声数据的情况下存在以下问题:第一、说话数据易获取但与目标歌声数据音域差异大;第二、歌声数据获取难导致训练数据音域跨度与实际数据不匹配。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种歌声转换模型的训练方法、歌声转换方法、系统和介质,能够有效缓解音域不匹配和音域跨度大导致的合成歌声破音现象。
2、一方面,本发明实施例提供了一种歌声转换模型的训练方法,包括以下步骤:
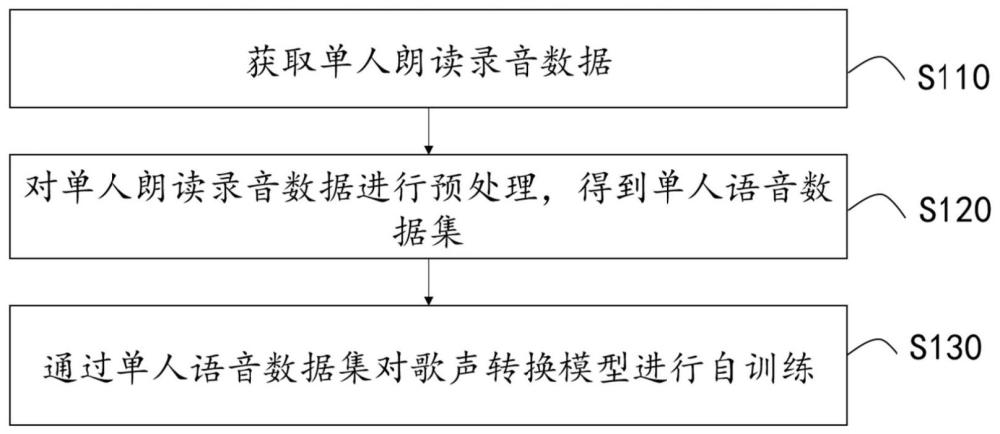
3、获取单人朗读录音数据;
4、对所述单人朗读录音数据进行预处理,得到单人语音数据集;
5、通过所述单人语音数据集对歌声转换模型进行自训练;
6、其中,所述歌声转换模型的自训练过程,包括以下步骤:
7、将所述单人语音数据集中的单语音数据作为训练数据训练歌声转换模型,输出得到合成歌唱数据;
8、将上一步训练得到的合成歌唱数据中符合预设要求的合成歌唱数据添加到所述训练数据后继续训练上一步训练后的歌声转换模型。
9、在一些实施例中,所述对所述单人朗读录音数据进行预处理,得到单人语音数据集,包括:
10、对所述单人朗读录音数据进行清洗,得到第一朗读录音数据;
11、对所述第一朗读录音数据进行降噪去混响,得到第二朗读录音数据;
12、对所述第二朗读录音数据进行音频切分,得到第三朗读录音数据;
13、对所述第三朗读录音数据进行数据增强,得到所述单人语音数据集。
14、在一些实施例中,所述对所述第三朗读录音数据进行数据增强,包括:
15、根据多个预设音调值或多个预设音高值分别处理所述第三朗读录音数据,得到多个不同音调或不同音高的朗读录音数据。
16、在一些实施例中,所述对所述第三朗读录音数据进行数据增强,包括:
17、根据预设音频速度值对所述第三朗读录音数据进行处理,得到多个音频速度对应的朗读录音数据。
18、在一些实施例中,所述对所述第二朗读录音数据进行音频切分,得到第三朗读录音数据,包括:
19、将所述第二朗读录音数据切分为不同时长的录音数据作为第三朗读录音数据。
20、在一些实施例中,所述歌声转换模型在自训练过程的损失函数如下:
21、
22、其中,ln表示所述歌声转换模型在第n轮训练时的损失函数;n表示自训练中迭代的轮数;αn为权重参数;l为所述歌声转换模型未训练时的损失函数;f为神经网络模型的前向运算过程;θs为神经网络模型权重参数;yn表示所述单人语音数据集中的语音数据;表示所述歌声转换模型输出的合成歌唱数据;xn表示从所述语音数据中提取的内容信息和基频信息;表示从所述合成歌唱数据中提取的内容信息和基频信息。
23、另一方面,本发明实施例提供了一种歌声转换方法,包括以下步骤:
24、获取单人朗读录音数据;
25、对所述单人朗读录音数据进行预处理,得到单人语音数据集;
26、通过所述单人语音数据集对歌声转换模型进行自训练;
27、获取待转换歌声数据;
28、将所述待转换歌声数据输入到自训练后的歌声转换模型,得到目标歌声数据;
29、其中,所述歌声转换模型的自训练过程,包括以下步骤:
30、将所述单人语音数据集中的单语音数据作为训练数据训练歌声转换模型,输出得到合成歌唱数据;
31、将上一步训练得到的合成歌唱数据中符合预设要求的合成歌唱数据添加到所述训练数据后继续训练上一步训练后的歌声转换模型。
32、另一方面,本发明实施例提供了一种歌声转换模型的训练系统,包括:
33、第一模块,用于获取单人朗读录音数据;
34、第二模块,用于对所述单人朗读录音数据进行预处理,得到单人语音数据集;
35、第三模块,用于通过所述单人语音数据集对歌声转换模型进行自训练;
36、第四模块,获取待转换歌声数据;
37、第五模块,将所述待转换歌声数据输入到自训练后的歌声转换模型,得到目标歌声数据;
38、其中,所述歌声转换模型的自训练过程,包括以下步骤:
39、将所述单人语音数据集中的单语音数据作为训练数据训练歌声转换模型,输出得到合成歌唱数据;
40、将上一步训练得到的合成歌唱数据中符合预设要求的合成歌唱数据添加到所述训练数据后继续训练上一步训练后的歌声转换模型。
41、另一方面,本发明实施例提供了一种歌声转换系统,包括:
42、第一模块,用于获取单人朗读录音数据;
43、第二模块,用于对所述单人朗读录音数据进行预处理,得到单人语音数据集;
44、第三模块,用于通过所述单人语音数据集对歌声转换模型进行自训练;
45、其中,所述歌声转换模型的自训练过程,包括以下步骤:
46、将所述单人语音数据集中的单语音数据作为训练数据训练歌声转换模型,输出得到合成歌唱数据;
47、将上一步训练得到的合成歌唱数据中符合预设要求的合成歌唱数据添加到所述训练数据后继续训练上一步训练后的歌声转换模型。
48、另一方面,本发明实施例提供了一种存储介质,其中存储有计算机可执行的程序,所述计算机可执行的程序被处理器执行时用于实现上述的歌声转换模型的训练方法或上述的歌声转换方法。
49、本发明实施例具有如下有益效果:
50、本实施例通过对获取到的单人朗读录音数据进行预处理得到单人语音数据集,然后通过单人语音数据集对歌声转换模型进行自训练,并在自训练过程中将单人语音数据集中的单语音数据作为训练数据训练歌声转换模型,输出得到合成歌唱数据后,将上一步训练得到的合成歌唱数据中符合预设要求的合成歌唱数据添加到所述训练数据后继续训练上一步训练后的歌声转换模型,从而使得训练得到的歌声转换模型在应用过程中,可以有效缓解音域不匹配和音域跨度大导致的合成歌声破音现象。
51、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:1.一种歌声转换模型的训练方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种歌声转换模型的训练方法,其特征在于,所述对所述单人朗读录音数据进行预处理,得到单人语音数据集,包括:
3.根据权利要求2所述的一种歌声转换模型的训练方法,其特征在于,所述对所述第三朗读录音数据进行数据增强,包括:
4.根据权利要求2所述的一种歌声转换模型的训练方法,其特征在于,所述对所述第三朗读录音数据进行数据增强,包括:
5.根据权利要求2所述的一种歌声转换模型的训练方法,其特征在于,所述对所述第二朗读录音数据进行音频切分,得到第三朗读录音数据,包括:
6.根据权利要求1所述的一种歌声转换模型的训练方法,其特征在于,所述歌声转换模型在自训练过程的损失函数如下:
7.一种歌声转换方法,其特征在于,包括以下步骤:
8.一种歌声转换模型的训练系统,其特征在于,包括:
9.一种歌声转换系统,其特征在于,包括:
10.一种存储介质,其特征在于,其中存储有计算机可执行的程序,所述计算机可执行的程序被处理器执行时用于实现如权利要求1-6任一项所述的歌声转换模型的训练方法或权利要求7所述的歌声转换方法。
技术总结本发明公开了一种歌声转换模型的训练方法、歌声转换方法、系统和介质,可广泛应用于歌唱处理技术领域。本发明通过对获取到的单人朗读录音数据进行预处理得到单人语音数据集,然后通过单人语音数据集对歌声转换模型进行自训练,并在自训练过程中将单人语音数据集中的单语音数据作为训练数据训练歌声转换模型,输出得到合成歌唱数据后,将上一步训练得到的合成歌唱数据中符合预设要求的合成歌唱数据添加到所述训练数据后继续训练上一步训练后的歌声转换模型,从而使得训练得到的歌声转换模型在应用过程中,可以有效缓解音域不匹配和音域跨度大导致的合成歌声破音现象。技术研发人员:曾令帆,李权,叶俊杰,成秋喜,王伦基,付玟受保护的技术使用者:广州赛灵力科技有限公司技术研发日:技术公布日:2024/4/17本文地址:https://www.jishuxx.com/zhuanli/20240618/23198.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表