一种语义拒识方法、装置、设备以及存储介质与流程
- 国知局
- 2024-06-21 11:44:11
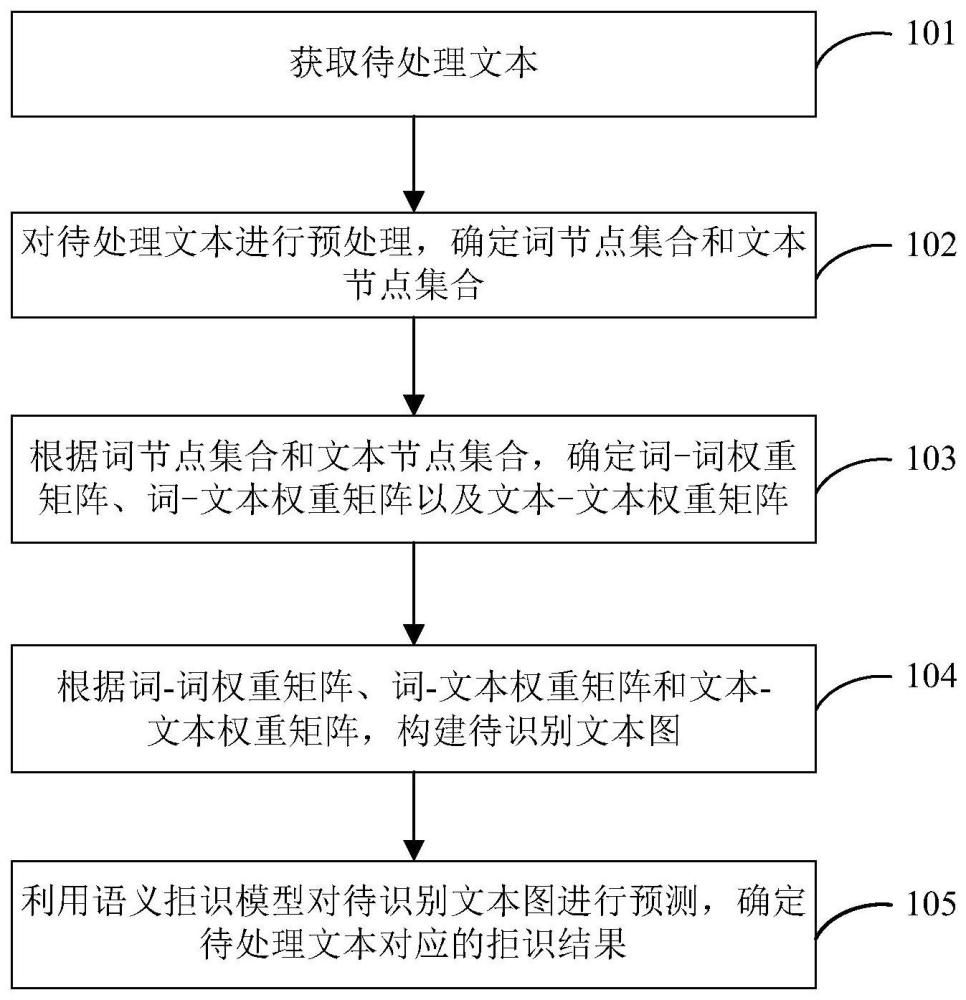
本技术涉及车载对话文本处理,具体涉及一种语义拒识方法、装置、设备以及存储介质。
背景技术:
1、随着交通工具智能化程度的提升,交通工具的应用程序与用户之间的互动越来越频繁。目前,在车载语音助手持续监听用户的场景中,由于实际交互环境的复杂多变性,在语音交互过程中经常会出现噪声干扰,导致车辆语音助手错误地做出响应。
2、在相关技术中,车辆语音助手可通过语义拒识模型根据输入语音的语义特征拒绝识别某些干扰性语音,从而提高车载语音助手的识别准确率。因此,语义拒识模型的准确率直接影响着最终指令是否能被正确理解和执行,如何提高语义拒识的准确率成为一个迫切需要解决的问题。
技术实现思路
1、本技术提供一种语义拒识方法、装置、设备以及存储介质,可以提高语义拒识的准确率。
2、本技术采用的技术方案如下:
3、第一方面,本技术实施例提供一种语义拒识方法,该语义拒识方法包括:获取待处理文本;对待处理文本进行预处理,确定词节点集合和文本节点集合;并根据词节点集合和文本节点集合,确定词-词权重矩阵、词-文本权重矩阵以及文本-文本权重矩阵;根据词-词权重矩阵、词-文本权重矩阵和文本-文本权重矩阵,构建待识别文本图;利用语义拒识模型对待识别文本图进行预测,确定待处理文本对应的拒识结果。
4、可以理解,获取待处理文本;对待处理文本进行预处理,确定词节点集合和文本节点集合;然后根据词节点集合和文本节点集合,确定词-词权重矩阵、词-文本权重矩阵以及文本-文本权重矩阵;进一步根据词-词权重矩阵、词-文本权重矩阵和文本-文本权重矩阵,构建待识别文本图;最后利用语义拒识模型对待识别文本图进行预测,确定待处理文本对应的拒识结果。如此,不仅能够挖掘对话文本之间相关性从而解决语义不明问题,而且通过语义拒识模型对文本图进行语义识别,有助于获取用户对话、对话意图、词汇之间耦合关系的高维特征,进而提高了语义拒识的准确率。
5、在一些实施例中,对待处理文本进行预处理,确定词节点集合和文本节点集合,包括:获取预设词集;根据预设词集对待处理文本进行分词及清洗处理,确定词节点集合和文本节点集合。
6、可以理解,根据预设词集对待处理文本进行分词及清洗处理,能够去除待处理文本中的无用部分,例如去除停用词、语气词、标点符号等,降低了文本图构建过程的复杂度,提升处理效率。
7、在一些实施例中,获取预设词集,包括:获取用户语料库和语义语料库;从用户语料库和语义语料库中提取文本数据;对文本数据进行分词及清洗处理,得到预设词集。
8、可以理解,通过用户语料库和语义语料库的大量数据来构建预设词集,能够有效对文本进行误识别拦截,进而提高语义拒识的准确率。
9、在一些实施例中,根据词节点集合和文本节点集合,确定词-词权重矩阵、词-文本权重矩阵以及文本-文本权重矩阵,包括:根据词节点集合中的每两个词节点之间的关系,确定每两个词节点之间的边的权重,以得到词-词权重矩阵;根据词节点集合中的任意词节点与文本节点集合中的任意文本节点之间的关系,确定任意词节点与任意文本节点之间的边的权重,以得到词-文本权重矩阵;根据文本节点集合中的每两个文本节点之间的关系,确定每两个文本节点之间的边的权重,以得到文本-文本权重矩阵。
10、可以理解,基于词节点集合和文本节点集合来确定词-词权重矩阵、词-文本权重矩阵以及文本-文本权重矩阵,不仅丰富了待识别文本图的信息,而且有助于挖掘对话文本之间相关性从而解决语义不明问题,进而提高语义拒识的准确率。
11、在一些实施例中,根据词节点集合中的每两个词节点之间的关系,确定每两个词节点之间的边的权重,包括:基于点互信息方式对每两个词节点之间的相关性进行计算,得到每两个词节点之间的边的权重。
12、可以理解,通过采用点互信息(pointwise mutual information,pmi)来计算每两个词节点之间边的权重,可以更好地捕捉预设词集中词与词之间的语义关系,从而丰富了待识别文本图的信息。
13、在一些实施例中,根据词节点集合中的任意词节点与文本节点集合中的任意文本节点之间的关系,确定任意词节点与任意文本节点之间的边的权重,包括:基于词频-逆文档频率方式对任意词节点与任意文本节点之间的相关性进行计算,得到任意词节点与任意文本节点之间的边的权重。
14、可以理解,通过使用词频-逆文档频率(term frequency-inverse documentfrequency,td-idf)来计算文本节点与词节点之间的边的权重,考虑了单词在当前对话中的重要性以及在用户语料库中的普遍性。同时结合词节点与词节点之间的pmi值,通过cgn进一步抽取词与对话文本关联程度的高维特征,可以解决用户对话文本口语化严重、短文本语义不明的问题。
15、在一些实施例中,根据文本节点集合中的每两个文本节点之间的关系,确定每两个文本节点之间的边的权重,包括:基于文本相似度方式对确定每两个文本节点之间的相关性进行计算,得到每两个文本节点之间的边的权重。
16、可以理解,通过文本相似度计算每两个文本节点之间的边的权重,以衡量不同文本之间的语义相似度,有助于语义拒识模型在多轮对话过程中可以更好地理解和推断不同对话之间的关系,进而提高语义拒识的准确率。
17、在一些实施例中,对于语义拒识模型的构建,包括:获取多个训练文本;基于多个训练文本,构建多个训练文本图;将多个训练文本图对预设网络模型进行训练,并且在损失函数满足收敛条件时,将训练后的预设网络模型确定为语义拒识模型。
18、可以理解,通过构建训练文本图,将训练文本图放入预设网络模型训练,在损失函数满足收敛条件时,将训练后的预设网络模型确定为语义拒识模型。如此,所得到的语义拒识模型能够获取用户对话、对话意图、词汇之间耦合关系的高维特征,进而提高语义拒识的准确率。
19、在一些实施例中,预设网络模型包括图卷积网络模型和分类模型,将所述多个训练文本图对预设网络模型进行训练,包括:将多个训练文本图依次输入图卷积网络模型进行特征训练,得到多个特征向量;根据多个特征向量依次输入分类模型进行分类训练,在损失函数满足收敛条件时,确定语义拒识模型。
20、可以理解,通过将训练文本图输入图卷积网络(graph convolutional network,gcn)中进行训练,可以更好的捕捉训练文本图各节点之间的复杂关系;然后由分类模型根据gcn学习到的语义信息,对输入的训练文本进行分类,在损失函数满足收敛条件时,这时候所确定的语义拒识模型更准确,有助于提高语义拒识的准确率。
21、第二方面,本技术实施例提供一种语义拒识装置,该语义拒识装置包括获取单元、确定单元、构建单元和预测单元,其中:获取单元,配置成获取待处理文本;确定单元,配置成对待处理文本进行预处理,确定词节点集合和文本节点集合;并根据词节点集合和文本节点集合,确定词-词权重矩阵、词-文本权重矩阵以及文本-文本权重矩阵;构建单元,配置成根据词-词权重矩阵、词-文本权重矩阵和文本-文本权重矩阵,构建待识别文本图;预测单元,配置成利用语义拒识模型对待识别文本图进行预测,确定待处理文本对应的拒识结果。
22、第三方面,本技术实施例提供一种电子设备,电子设备包括存储器和处理器,其中:存储器,用于存储能够在处理器上运行的计算机程序;处理器,用于在运行计算机程序时,执行如第一方面中任一项所述的方法。
23、第四方面,本技术实施例提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被至少一个处理器执行实现如第一方面中任一项所述的方法。
24、本发明的有益效果:
25、(1)针对用户对话口语化严重、短文本语义不明的问题,提出利用用户语料库以及语义语料库构建的预设词集,计算词节点-词节点的权重矩阵、词节点与文本节点的权重矩阵以及文本节点与文本节点之间的权重矩阵并构建文本图,能够挖掘对话文本之间相关性从而解决语义不明问题;
26、(2)通过语义拒识模型对文本图进行语义识别,有助于获取用户对话、对话意图、词汇之间耦合关系的高维特征,进而提高了语义拒识的准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23222.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表