一种基于GPT模型语音识别的自训练系统和方法与流程
- 国知局
- 2024-06-21 11:44:13
本发明涉及语音识别领域,具体为一种基于gpt模型语音识别的自训练系统和方法。
背景技术:
1、随着智能系统的发展,为了减少打字时间,提高交流效率,语音识别系统为交流和沟通提供了加便捷,但现有的语音识别系统大多针对实际场景优化,需要提前收集该场景的关键字,把关键字输入语音识别模型中,这个需要提前收集关键字,实际操作难度大,关键字的提前收集范围也具有局限性,所以提出一种不需要提前场景的关键字,也能对语音识别实现场景优化的语音识别的系统和方法是十分必要的。
技术实现思路
1、本发明的目的在于提供一种基于gpt模型语音识别的自训练系统和方法,使得语音识别模块不需要提前收集场景关键字,就能对语音识别实现场景优化,以解决现有的技术缺陷和不能达到的技术要求。
2、为实现上述目的,本发明提供如下技术方案:一种基于gpt模型语音识别的自训练系统,包括:
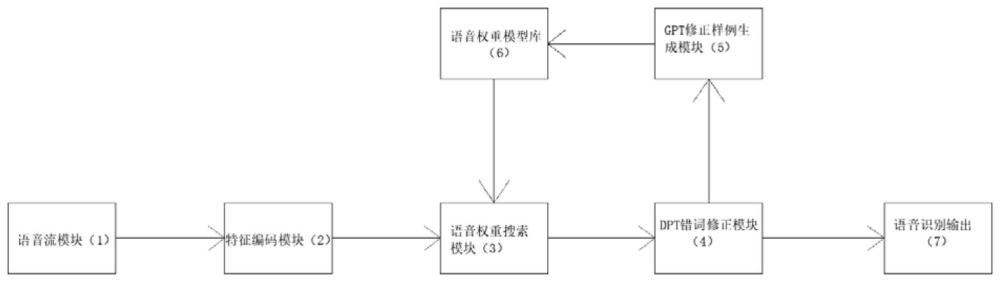
3、语音流模块,所述语音流模块采集真实世界的声音,将声音的信号类型进行转化,再对转化后的声音信号进行处理,得到音频分片数据,最后语音流模块把得到的音频分片数据发送报给特征编码模块;
4、特征编码模块,所述特征编码模块接收到语音流模块发送来的重叠音频分片数据后,并对重叠音频分片数据进行编码,得到音频数据的频域分片,再对音频数据进一步处理得到语音特征数据,最终特征编码模块把语音特征数据发送语音权重搜索模块;
5、语音权重搜索模块,所述语音权重搜索模块接收特征编码模块中的语音特征数据,同时接收语音权重模型库的词间概率值,先对语音特征数据进行搜索解码获取语音识别可能字,再结合词间概率值,将语音特征数据按照语音权重模型库的语言表达习惯输出语言识别结果,最终音权重搜索模块把语音识别结果发送给gpt错词修正模块;
6、gpt错词修正模块,所述gpt错词修正模块接收语音权重搜索模块发送来的的语音识别结果,并对语音识别结果进行检测,再将语音识别结果进行纠正,然后gpt错词修正模块将纠正后的语音识别结果发送给语音识别输出,将纠正后的语音识别结果与未纠正的语音识别结果发送gpt修正样例生成模块;
7、gpt修正样例生成模块,所述gpt修正样例生成模块接受gpt错词修正模块发送来的纠正后的语音识别结果与未纠正的语音识别结果,并将二者进行对比的识别错的词,再通过错的词扩充一批新的句子,最后gpt修正样例生成模块将纠正后的语音识别结果与新生成句子发送给语音权重模型库;
8、语音权重模型库,所述语音权重模型库接收的gpt修正样例生成模块发过来的纠正后的语音识别结果与新生成句子,并将二者进行处理得到新的词间概率值,最后语音权重模型库将新的词间概率值发送给语音权重搜索模块;
9、语音识别输出,所述语音识别输出接收gpt错词修正模块的纠正的语音识别结果,并对纠正后的语音识别结果进行进一步的形式修正,得到修正后的语音识别结果,并将修正后的语音识别结果展示给用户。
10、优选的,一种基于gpt模型语音识别的自训练方法,包括:
11、1)、语音流模块收集外界声音,并对收集到的声音进行初步处理;
12、1.1)语音流模块通过麦克风采集真实世界的声音;
13、1.2)语音流模块将模拟信号的声音转化成数字信号;
14、1.3)语音流模块将数字信号进行分片处理,得到音频分片数据,最后将音频分片数据发送报给特征编码模块;
15、2)、特征编码模块对音频分片后的数据进行进一步处理,减少其特征数据量;
16、2.1)特征编码模块接收语音流模块发来的音频分片数据;
17、2.2)特征编码模块将音频分片数据进行快速傅立叶编码,得到音频数据的频域分片;
18、2.3)特征编码模块对频域分片进行滤波处理;
19、2.4)特征编码模块对滤波处理后的数据再进行降采样编码处理,最终得到语音特征数据,最后将语音特征数据发送语音权重搜索模块;
20、3)、语音权重搜索模块根据语音权重模型库中的语言表达习惯进行语言识别;
21、3.1)语音权重搜索模块接收特征编码模块发过来的语音特征数据,同时接收语音权重模型库的词间概率值;
22、3.2)语音权重搜索模块对语音特征数据进行搜索解码获取语音识别可能字;
23、3.3)语音权重搜索模块根据词间概率值对语音特征数据进行筛选处理,最终得到语音识别结果;
24、3.4)语音权重搜索模块把语音识别结果发送给gpt错词修正模块;
25、4)、gpt错词修正模块对语音识别的结果进行错词修正;
26、4.1)gpt错词修正模块接收语音权重搜索模块发过来的的语音识别结果;
27、4.2)gpt错词修正模块使用大语言模型的强大语言理解和生成能力对语音识别结果进行分片检测;
28、4.3)gpt错词修正模块再对分片检测后的语音识别结果进行纠正,最终得到纠正后的语音识别结果;
29、4.5)gpt错词修正模块将gpt错词修正模块纠正后的语音识别结果发送给语音识别输出,将纠正后的语音识别结果与未纠正的语音识别结果发送gpt修正样例生成模块;
30、5)、gpt修正样例生成模块提取错的词,生成新的句子;
31、5.1)gpt修正样例生成模块接收接受gpt错词修正模块发过来的的纠正后的语音识别结果和未纠正的语音识别结果;
32、5.2)gpt修正样例生成模块将纠正后的语音识别结果与未纠正的语音识别结果进行对比,得到错的词;
33、5.3)gpt修正样例生成模块使用大语言模型的文本生成能力,通过错的词扩充一批新句子;
34、5.4)gpt修正样例生成模块把纠正后的语音识别结果与新生成句子发送给语音权重模型库;
35、6)、语音权重模型库根据gpt修正样例生成模块传递过来的内容生成词间概率值;
36、6.1)语音权重模型库接收的gpt修正样例生成模块的纠正后的语音识别结果与新生成句子;
37、6.2)语音权重模型库将纠正后的语音识别结果与新生成句子添加到语音权重模型库的文本库中;
38、6.3)语音权重模型库对新的文本库使用语言模型进行重新训练得到新的词间概率值;
39、6.4)语音权重模型库将新的词间概率值发送给语音权重搜索模块;
40、7)、语音识别输出输出最终值呈现给用户;
41、7.1)语音识别输出接收接收gpt错词修正模块发送来的纠正后的语音识别结果;
42、7.2)语音识别输出为纠正后的语音识别结果添加上标点符号,最终展现给用户。
43、优选的,1.3)中,语音流模块将数字信号进行分片处理的具体方法为:
44、将数字信号按照采样点数量利用重叠分片法进行分片处理,每个分片与上一个分片有采样点一半数量的采样点重叠,最终得到的音频分片数据为重叠音频分片数据。
45、优选的,2.3)中,所述特征编码模块对频域分片进行过滤处理的方法为:
46、所述特征编码模块通过mel滤波器对频域分片进行滤波处理。
47、优选的,2.4)中,所述特征编码模块对滤波处理后的数据进行降采样编码的具体方法为:
48、所述编码模块采用2d-conv降维算法对mel滤波器处理后数据进行降采样编码,以得到语音特征数据。
49、优选的,3.3)中,所述语音权重搜索模块根据词间概率值对语音特征数据进行筛选处理的具体步骤为:
50、所述语音权重搜索模块根据语音特征数据获取可能字;
51、所述语音权重搜索模块再根据词间概率值计算概率p;
52、所述语音权重搜索模块保留语音特征数据中p值最高的词序列,最终得到语言识别结果。
53、优选的,p的计算公式为:
54、
55、优选的,4.3)中,所述gpt错词修正模块再对分片检测后的语音识别结果进行纠正的方法为:
56、所述gpt错词修正模块使用最近50修改后的识别结果加上新语音识别结果,让大语言模型理解这段语音识别结果上文,来纠正语音识别结果。
57、优选的,所述gpt错词修正模块纠正语音识别结果中的内容包括:语音识别结果中的拼写错误、语法错误和语言习惯问题。
58、优选的,6.3)中,所述语音权重模型库使用的语言模型为:ngram语言模型。
59、与现有技术相比,本发明的有益效果是:
60、1、本发明采用在一个特定语音识别场景利用gpt大模型对识别结果进行修正,利用修正生成相关扩招文本,使用文本训练语音识别的语言库模型,实现无手工标点关键词条件语音识别场景优化,降低提高语音识别率的成本。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23225.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表