音频合成模型训练方法、计算机设备及计算机存储介质与流程
- 国知局
- 2024-06-21 11:44:14
本申请实施例涉及音频处理领域,具体涉及一种音频合成模型训练方法、计算机设备及计算机存储介质。
背景技术:
1、歌声合成(singing voice synthesis)是根据乐谱生成歌声的技术,是创造能说会唱的虚拟人中的重要一环。语音音色转换(voice conversion)或语音克隆(voiceclone)是指输入一条语音,在保持说话内容不变的情况下,让它听起来像是另一个人说的;歌声音色转换(singing voice conversion,svc)即保持歌词内容不变的情况下改变音色和歌唱技巧,类似达到一首歌曲多个翻唱版本。
2、相关的svc方案合成具有指定人员音色的歌曲,但是该svc方案需要用到大量的用户干声数据进行模型训练,因而需要用户预先提供其多首歌唱作品以便提取该用户的音色特征,这种方式较为不便,不利于歌声合成产品落地上线要求,歌声合成时间和成本较高。
技术实现思路
1、本申请实施例提供了一种音频合成模型训练方法、计算机设备及计算机存储介质,用于降低svc模型的训练成本和训练时间,提升用户对svc产品的使用体验。
2、本申请实施例第一方面提供了一种音频合成模型训练方法,所述方法包括:
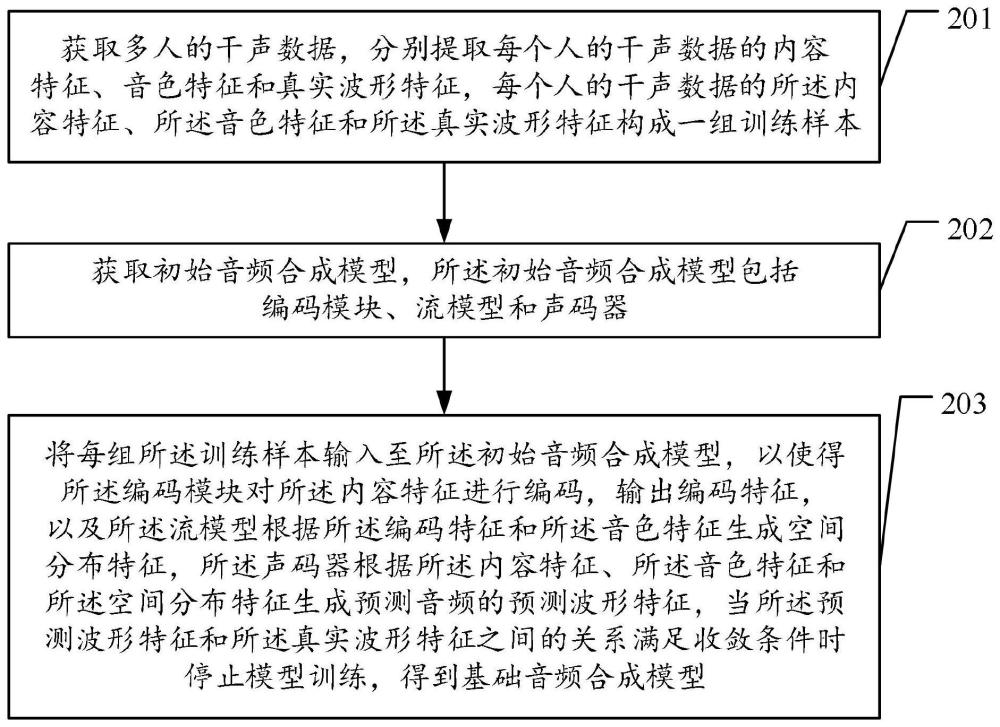
3、获取多人的干声数据,分别提取每个人的干声数据的内容特征、音色特征和真实波形特征,每个人的干声数据的所述内容特征、所述音色特征和所述真实波形特征构成一组训练样本;
4、获取初始音频合成模型,所述初始音频合成模型包括编码模块、流模型和声码器;
5、将每组所述训练样本输入至所述初始音频合成模型,以使得所述编码模块对所述内容特征进行编码,输出编码特征,以及所述流模型根据所述编码特征和所述音色特征生成空间分布特征,所述声码器根据所述内容特征、所述音色特征和所述空间分布特征生成预测音频的预测波形特征,当所述预测波形特征和所述真实波形特征之间的关系满足收敛条件时停止模型训练,得到基础音频合成模型;
6、其中,所述基础音频合成模型用于基于目标用户的干声数据的音色特征和所述待转换音频的内容特征,将所述待转换音频的音色转换为所述目标用户的音色。
7、本申请实施例第二方面提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现前述第一方面的方法。
8、本申请实施例第三方面提供了一种计算机存储介质,计算机存储介质中存储有指令,该指令在计算机上执行时,使得计算机执行前述第一方面的方法。
9、本申请实施例第四方面提供了一种计算机程序产品,所述计算机程序产品在计算机设备上运行时,使得所述计算机设备执行前述第一方面的方法。
10、从以上技术方案可以看出,本申请实施例具有以下优点:
11、基于多人的干声数据的音色特征、内容特征和真实波形特征训练音频合成模型,模型中的编码模块对内容特征进行编码,输出编码特征,以及流模型根据编码特征和音色特征生成空间分布特征,声码器根据内容特征、音色特征和空间分布特征生成预测音频的预测波形特征,当预测波形特征和真实波形特征之间的关系满足收敛条件时停止模型训练,得到基础音频合成模型,通过对基础音频合成模型的多个模块的训练,可以让基础音频合成模型具备模仿任一用户的音色的能力,因而即使是用户少量的干声数据,如仅有用户的语音片段或歌唱干声片段,或者仅有用户的几首歌曲的歌唱干声,也能使模型学习到用户的音色并基于学习到的用户音色对音频进行音色转换,从而降低svc模型的训练成本和训练时间,提升用户对svc产品的使用体验。
技术特征:1.一种音频合成模型训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述目标用户的干声数据包括所述目标用户演唱预设数量歌曲的歌唱干声数据;
3.根据权利要求2所述的方法,其特征在于,所述将所述待转换音频的音色转换为所述目标用户的音色,包括:
4.根据权利要求2所述的方法,其特征在于,所述基础音频合成模型中的编码模块包括编码器encoder和后验编码器posterior encoder;
5.根据权利要求4所述的方法,其特征在于,执行所述微调训练时,所述方法还包括:
6.根据权利要求2至5任一项所述的方法,其特征在于,所述提取所述歌唱干声数据的音色特征、内容特征和真实波形特征,包括:
7.根据权利要求1所述的方法,其特征在于,所述目标用户的干声数据为所述目标用户说话或者歌唱的音频片段;
8.根据权利要求1至7任一项所述的方法,其特征在于,在所述初始音频合成模型的模型训练中,所述方法还包括:
9.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至8中任一项所述的方法。
10.一种计算机存储介质,其特征在于,所述计算机存储介质中存储有指令,所述指令在计算机上执行时,使得所述计算机执行如权利要求1至8中任一项所述的方法。
技术总结本申请实施例公开了一种音频合成模型训练方法、计算机设备及计算机存储介质。基于多人干声数据的音色特征、内容特征和真实波形特征训练音频合成模型,模型中的编码模块对内容特征进行编码输出编码特征,流模型根据编码特征和音色特征生成空间分布特征,声码器根据内容特征、音色特征和空间分布特征生成预测波形特征,满足收敛条件时得到基础音频合成模型,通过对模型多个模块的训练,让模型具备模仿任一用户的音色的能力,因而即使是用户少量的干声数据,如仅有用户的语音片段或歌唱干声片段,或者仅有用户的几首歌曲的歌唱干声,也能使模型学习到用户的音色并基于学习到的用户音色对音频进行音色转换,从而降低SVC模型的训练成本和训练时间。技术研发人员:张斌受保护的技术使用者:腾讯音乐娱乐科技(深圳)有限公司技术研发日:技术公布日:2024/4/17本文地址:https://www.jishuxx.com/zhuanli/20240618/23228.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表