一种联合语音增强方法及其模型搭建方法
- 国知局
- 2024-06-21 11:44:20
本发明属于语音识别模型,尤其涉及一种联合语音增强方法及其模型搭建方法。
背景技术:
1、通常,正常听力的听众能够专注于特定的声学刺激,针对目标语音或感兴趣的语音,同时过滤掉其他声音,这种众所周知的现象被称为鸡尾酒会效应,因为它类似于鸡尾酒会上发生的情况,由此引发了人们对语音增强这一问题的关注。语音增强的目的是消除信号中的噪声成分同时保留干净的语音信号,提高语音质量和可懂度。随着数字信号处理技术的发展,语音增强技术也得到了很大的发展和改进。通过数字技术对语音信号进行滤波、增强、去混响等处理,语音信号的质量和清晰度得以进一步提高。基于数字信号处理技术的语音增强,可以分为传统的数字语音增强方法和基于神经网络的语音增强方法两大类。
2、传统的数字语音增强方法通常是基于时域或频域进行信号处理的,常见的方法包括谱减法、维纳滤波法、子空间法等。其只适用于简单噪声场景,但现实中的噪声场景通常比较复杂。近年来,由于具有良好的泛化性能,可以从大量的数据中自动学习特征,应对不同的语音增强场景和任务,深度学习在语音增强领域的应用逐渐增多。众多表现良好的语音增强的模型被提出。
3、然而,语音感知本质上是多模态的,特别是视听,因为除了到达听众耳朵的声学语音信号之外,一些有助于语音产生的发音器官(例如舌头、牙齿、嘴唇、下巴和面部表情)的位置和运动也可能对接收者可见。神经科学和言语感知的研究表明,言语的视觉方面对人类将听觉注意力集中在特定刺激上的能力有潜在的强烈影响。2018年谷歌提出了一个基于深度学习联合视听语音分离/增强模型,相比纯音频方法显著提高了其增强性能。但上述方法对视听信息融合方面做的不够充分,如何有效地结合音视频特征,使其提高语音增强效果仍然值得探讨。
技术实现思路
1、针对上述问题,本发明第一方面提供了一种联合语音增强模型的搭建方法,包括以下过程:
2、步骤1,获取若干说话人的视频和相应音频的原始数据;
3、步骤2,对步骤1中获取的原始数据进行预处理;将视频分别处理为一帧一帧的图像,同时从原始数据中随机选取一个说话人的数据和一个噪声数据,将其中的音频混合按一定比例混合后对混合语音做短时傅里叶变换得到语音的语谱图,结合说话人数据对应的面部帧构建数据集,并划分为训练集、验证集和测试集;
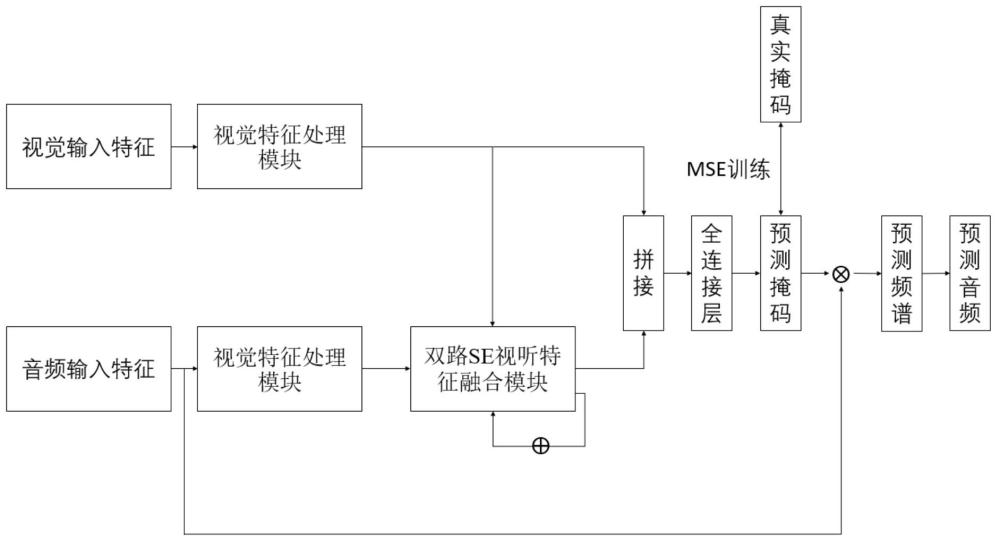
4、步骤3,基于resnet18网络结构和cbam注意力机制,构建视觉特征处理模块;基于3个cnn卷积块的组合,构建音频特征处理模块;基于se模块结构,在传统的se模块基础上增加了视频流输入,对视听特征分别进行压缩,然后合并压缩特征,最后由输入音频特征进行激励,构建为一个双路se视听特征融合模块;基于双向lstm网络结构和全连接层,构建为网络输出模块;将上述四个网络模块结合,构建为基于挤压激励融合视听特征的联合语音增强模型;
5、其中,模型将混合语音的语谱图和视频面部帧作为输入,模型输出为预测音频语谱图,最终将预测语谱图进行逆短时傅里叶变换得到最终预测音频;
6、步骤4,使用预处理后的数据集对构建的联合语音增强模型进行训练与测试评估,获取最终联合语音增强模型。
7、优选的,所述步骤2中预处理的具体过程为:
8、首先将每一个视频以每秒25帧进行裁剪,得到按照时间维度排列的图像,对于每一张图像使用现有的基于opencv库的mtcnn人脸检测器提取每张图片中的目标说话人的人脸缩略图,使用facenet预训练模型来提取每个人脸缩略图的人脸特征,facenet预训练模型经过训练大量人脸图片得到;然后从原始数据中随机选取一个说话人的数据和一个噪声数据,将其中的音频混合后对混合语音做短时傅里叶变换得到语音的语谱图,结合说话人数据对应的面部特征构建数据集。
9、优选的,所述视觉特征处理模块由修改后的resnet18残差网络和卷积块注意力模块cbam组成;
10、所述修改后的resnet18残差网络,包括1个conv5卷积层,4个conv_res层;其中conv5层由大小为5×5步长为1的卷积核、批归一化bn层以及relu激活函数组成,每个conv_res层由两个相同的卷积块组成,每个卷积块包含一个大小为1×7步长为1的卷积核、bn层以及relu激活函数;卷积块的输入输出公式可由下式表示:
11、y = relu(x + bn(conv_res (relu(bn(conv_res (x))))))
12、其中,x代表卷积块的输入,y代表卷积块的输出;所述conv_res是1×7卷积运算;修改后的resnet18残差网络的输出作为cbam模块的输入;
13、所述cbam模块由通道注意力模块和空间注意力模块组成,所述cbam模块位于修改后的resnet18残差网络之后,用于高效的提取和音频相关性较大的人脸关键区域,忽略人脸之外的次要区域;
14、所述cbam模块的输出作为网络提取的初步视觉特征,其用作双路se视听特征融合模块的一部分输入。
15、优选的,所述音频特征处理模块由3个cnn卷积块组成;每个卷积块包括2d卷积层、批量归一化bn和relu激活函数;所述2d卷积层卷积核大小为55,步长为1;所述cnn卷积块的输出作为网络提取的初步音频特征,其用作双路se视听特征融合模块的另一部分输入。
16、优选的,所述双路se视听特征融合模块,基于挤压激励模块改进,包括一个2d卷积层、双路se视听特征融合结构、批量归一化bn和relu激活函数;
17、所述2d卷积层为处理音频特征处理模块的输出,其由一个大小为5×5步长为1的卷积核、一个bn层以及一个relu激活函数组成;
18、所述双路se视听特征融合结构输入为处理视觉特征处理模块的输出和2d卷积层处理后的音频特征,其结构由对视频输入特征进行压缩操作,对音频输入特征进行压缩操作、1d卷积层调整通道维度操作、延展成1维向量的操作,对压缩后的音视频特征进行拼接操作,对拼接后的音视频特征利用全连接层重塑维度操作,将输入音频特征与重塑后的音视频融合特征进行哈达玛乘积操作;
19、视频输入特征压缩操作为,对输入视频特征进行全局平均池化,即空间注意力机制操作;压缩的视频特征为一个一维向量;
20、音频输入特征压缩操作为,对输入音频特征进行计算通道维度的平均值,即空间注意力机制操作;
21、所述1d卷积层调整通道维度操作,是将压缩后的音频输入特征进行1d卷积,调整维度;
22、所述延展成1维向量的操作,是将调整维度后的音频特征重塑为一个一维向量;
23、所述压缩后的音视频特征进行拼接操作,是将上述得到的两个音视频一维特征拼接成一个新的音视频融合一维特征向量;
24、所述拼接后的音视频特征利用全连接层重塑维度操作,是利用两个全连接层将音视频融合一维特征向量先利用第一个全连接层压缩,其中压缩因子r=16,之后利用第二个全连接层将其还原为输入音频特征时间维度和频率维度相乘的大小;
25、所述输入音频特征与重塑后的音视频融合特征进行哈达玛乘积操作公式如下:
26、
27、其中为双路se视听特征融合结构输出,为经过2d卷积层的音频特征,为重塑后的音视频融合特征;
28、所述批量归一化bn和relu激活函数用于处理双路se视听特征融合结构输出。
29、优选的,所述双路se视听特征融合模块在联合语音增强模型结构中将重复多次,并且模块与模块之间将使用残差思想连接,公式如下:
30、
31、其中为第个融合模块的输出,为第个融合模块输出,为第个融合模块的最终输出。
32、优选的,所述网络输出模块由双向lstm网络结构和三个全连接层构成;
33、所述双向lstm网络用于更好地捕捉双向的语义依赖,所述三个全连接层,其中最后一个全连接层的维度等于模型输入音频特征。
34、优选的,所述步骤4中对构建的联合语音增强模型进行训练与测试评估,在训练过程中使用复数域理想比值掩码crm作为音频的训练目标,使用均方误差mse损失计算真实音频掩码和预测音频掩码的差异,crm的计算公式如下所示:
35、
36、其中,其中,和代表混合语音信号的实部和虚部,和代表干净语音的实部和虚部。
37、优选的,所述步骤2中,对混合语音做短时傅里叶变换得到语音的语谱图,音频采样率为16khz,音频片段长度为3s,stft帧长为512个采样点,帧移为160个采样点,采用汉宁窗。
38、本发明第二方面还提供了一种联合语音增强方法,包括以下过程:
39、获取包含有说话人的视频和相应音频;
40、将获取的视频和相应音频进行处理,分别提取混合语音的语谱图和视频面部帧;
41、将语谱图和视频面部帧输入到如第一方面所述的搭建方法所搭建的最终联合语音增强模型中;
42、输出最终预测音频。
43、本发明第三方面还提供了一种联合语音增强设备,所述设备包括至少一个处理器和至少一个存储器,所述处理器和存储器相耦合;所述存储器中存储有如第一方面所述的搭建方法所搭建的最终联合语音增强模型的计算机执行程序;所述处理器执行存储器中存储的计算机执行程序时,可以使处理器执行一种联合语音增强方法。
44、本发明第四方面还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有如第一方面所述的搭建方法所搭建的最终联合语音增强模型的计算机执行程序,所述计算机执行程序被处理器执行时,可以使处理器执行一种联合语音增强方法。
45、与现有技术相比,本发明具有如下有益效果:
46、本发明提出了一种基于挤压激励融合视听特征的模块构建的视听语音增强模型,轻量化了音频模态和视频模态的处理部分,并把重点放在了双路se视听特征融合模块上,se模块算法能让网络更好地利用视觉信息和音频信息之间的内在联系,可以实现更好的语音增强性能;针对于传统的级联融合或是加法融合模式,这两种融合方法简单直接且不需要计算,但是在模型中这种简单的融合会损失很多有用的信息,从而导致分离的音频的效果不够准确,本发明提出的融合方法在效果上明显占优;相比于单纯使用音频信号的频域特征,本发明对混合语音信号做stft变换,充分的利用语音信号的幅度信息和相位信息。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23240.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。