基于对比学习和混合注意力的口语英语识别方法和系统
- 国知局
- 2024-06-21 11:45:25
本发明属于语音识别,尤其涉及基于对比学习和混合注意力的口语英语识别方法和系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、语音识别是一种基于声波信号将语音转录为人类或计算机可以理解的文本,该技术广泛应用于自然语言交互、智能家居、自动驾驶和金融服务等领域。
3、早期语音识别基于模版匹配,提取语音信号后,简单地将语音信号与已有的预设模版进行匹配。然后这种方法噪音环境下的识别能力极差,而且由于说话人的不同和语言能力的不同,预设模板很难去确定和保证全部的情况。随着机器学习技术的兴起,统计学习建模逐渐成为主流,该方法依据大量的训练数据,构建概率模型,能够得到更高的识别准确率。
4、近年深度学习发展迅速,在自然语言处理、计算机视觉和语言识别上都取得了非常卓越的效果,深度学习模型能够更好的建模语音特征和文本之间的关系,是目前识别准确率最高的方法,本发明的语言识别模型也是基于深度学习方法。总的来说,基于深度学习的语音识别模型在准确率、鲁棒性和速度上都显著提高,但是仍然存在一些不足,比如数据量不足的情况下难以训练出优秀的模型,或者在噪音环境下识别准确率降低等问题。
5、语音识别和语音合成等领域对音频的质量和数量有很高的要求,但是实际应用场景中,由于场景或者设备的不足,录制的音频质量往往不是很理想,比如含有噪声、回声、失真或者低音炸音等。质量较低的音频数据难以训练出高准确率的语音识别模型,对转录后的分析工作带来了诸多不便。针对质量较低的噪音数据,以往方法可以通过预处理来解决,降低噪声或噪声对实际任务的干扰,比如滤波器、降噪算法等,但是这些方法需要花费大量的时间精力,降噪效果也不尽人意。
6、与普通的语音识别相比,考场口语噪音多而杂,原因来源于录制环境和设备,这大大的增加了语音识别的难度,降低了识别的准确率,因此,普通的语音识别技术难以直接应用至口语英语的识别中。
技术实现思路
1、为克服上述现有技术的不足,本发明提供了基于对比学习和混合注意力的口语英语识别方法,分析考场口语的特点和环境设定,以增强抗噪能力为主要目的,有助于提高口语评分系统的准确率和可靠性,为考生和考官带来更好的用户体验。
2、为实现上述目的,本发明的一个或多个实施例提供了如下技术方案:
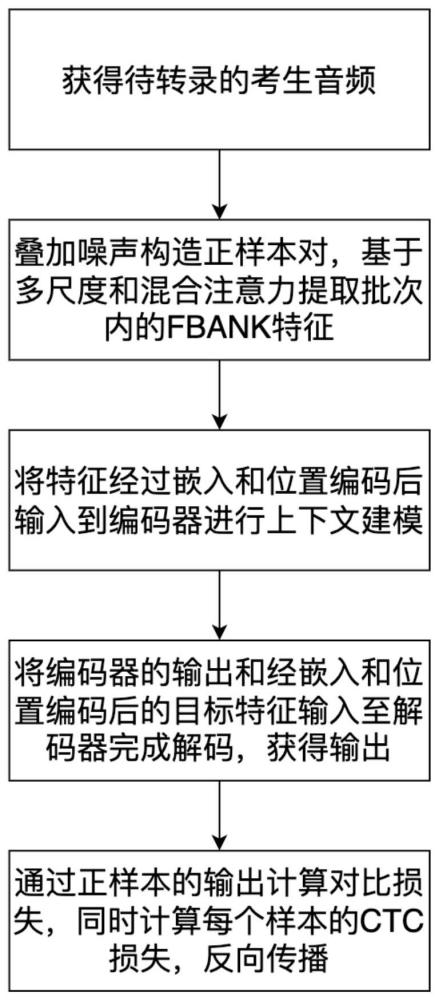
3、第一方面,公开了基于对比学习和混合注意力的口语英语识别方法,包括:
4、获取口语英语考试的音频,依据环境录音叠加随机类别的噪声实现噪声增强进而构造正样本;
5、基于多尺度和混合注意力对对添加噪声的数据进行特征提取;
6、将特征经过嵌入和位置编码后输入至编码器进行上下文建模;
7、将编码器的输出和经嵌入和位置编码后的目标特征输入至解码器完成解码;
8、在训练过程中,通过正样本的输入计算对比损失,同时计算每个样本的损失,反向传输,获得识别模型;
9、待转录的考生音频输入至识别模型,获得识别结果。
10、作为进一步的技术方案,基于多尺度和混合注意力对对添加噪声的数据进行特征提取,具体为:
11、对添加噪声的数据提取音频的特征;
12、对提取的音频特征通过不同窗口大小卷积降维后拼接,得到多尺度的特征表示;
13、基于时序和尺度的混合注意力机制计算每一个时序对不同尺度特征的注意力分数;
14、基于注意力分数加权计算每一个维度的特征,获得混合注意力计算后的多尺度融合特征。
15、作为进一步的技术方案,在尺度维度上拼接特征,并通过卷积降低维度,得到尺寸为(t,c,l)的特征图,其余l是不同尺度的数量,t是单个尺度的时序数目,而c则是单个时序位置的特征维度;
16、通过三个分支获取维度为(t*l,1)的q、k、v向量,其中,v向量通过最大池化获得,而q和k向量则通过卷积降维得到,将q向量转置后与k向量进行矩阵乘法,生成形状为(t*l,t*l)的注意力矩阵,之后,将注意力矩阵与v向量相乘,得到大小为(t*l,1)的尺度注意力分数。
17、作为进一步的技术方案,基于注意力分数加权计算每一个维度的特征,获得混合注意力计算后的多尺度融合特征,具体为:
18、将q、k、v向量通过两个全连接层进行平滑和信息提炼后,拆分时序和尺度维度,并在尺度维度上softmax归一化注意力分数,代表每个时序中各个尺度的重要性;
19、利用归一化的注意力分数以加权求和的方式计算多尺度特征图中的每个时序的特征值,得到注意力机制计算后的注意力图。
20、作为进一步的技术方案,基于多尺度和混合注意力对对添加噪声的数据进行特征提取之前还包括音频特征提取,具体为:
21、对特征进行加窗,每个窗口视为一帧,紧接着,对每一帧做快速傅里叶变换,获得频率特征,最终将每一帧在时间维度堆叠起来就可以得到声谱图。
22、作为进一步的技术方案,训练时,解码器输入是编码器的输出、经特征嵌入和位置编码后的目标序列,在推理时,经由解码器得到每个时步的概率分布,对于每个时步得到的特征经过处理后得到分类向量,对应着该时步选择每个单词的概率,在得到每一个时步的概率矩阵后,通过解码算法来搜索最佳的文本序列,得到识别结果。
23、作为进一步的技术方案,所述解码器解码时选用了正反向的平行解码器来取代conformer原文中的lstm,逆向的解码器在训练时输入相反目标序列。
24、第二方面,公开了基于对比学习和混合注意力的口语英语识别系统,包括:
25、噪声叠加模块,被配置为:获取口语英语考试的音频,依据环境录音叠加随机类别的噪声实现噪声增强进而构造正样本;
26、特征提取模块,被配置为:基于多尺度和混合注意力对对添加噪声的数据进行特征提取;
27、编码及解码模块,被配置为:将特征经过嵌入和位置编码后输入至编码器进行上下文建模;
28、将编码器的输出和经嵌入和位置编码后的目标特征输入至解码器完成解码;
29、训练模块,被配置为:在训练过程中,通过正样本的输入计算对比损失,同时计算每个样本的损失,反向传输,获得识别模型;
30、识别模块,被配置为:待转录的考生音频输入至识别模型,获得识别结果。
31、以上一个或多个技术方案存在以下有益效果:
32、为了更进一步提高语言识别模型的噪音鲁棒性,本发明提出了一种基于对比学习的语音识别训练方法。该方法通过添加噪音实现数据增强,与原始干净的语音作为正样本对进行对比学习,提高模型在噪音环境下的识别准确率。方法思想是期望模型能够学习到原始和加噪音频之间的映射关系,利用二者的差异来学习一个更加鲁棒的特征表征能力,进而提高在噪音环境中的泛化能力。
33、为了减少噪声特征对语言识别模型的破坏性,关注更有用的特征,本发明将多尺度融合的特征提取方式引入到语言识别任务中。为了强化关键特征、减少冗余性和减少计算量,提出了混合注意力机制为每个时序的不同尺度特征分配权重,自动识别和关注任务中更重要的特征,这可以使模型在处理全局和局部信息时具有更好的灵活性。
34、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23391.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。