耳机自识别噪声的方法及系统与流程
- 国知局
- 2024-06-21 11:46:02
本发明涉及数据识别的,尤其是涉及一种耳机自识别噪声的方法。
背景技术:
1、随着音乐数码产品的流行,催生出一大批曲不离耳的“耳机族,他们经常边骑车边带着耳机听歌,或者在乘坐公共交通时也带着耳机,将自己与外部环境隔绝。“耳机族”们通常听不清外界的提示音,如汽车声或警报声,从而面临较大的安全隐患和不便。
2、为了改善这一问题,现有技术中的耳机能够开启“通透模式”来获取环境音。“通透模式”下,能够通过耳机上的麦克风拾取环境声,经滤波后再由耳机扬声器播放,从而使得带着耳机也能听到外界的声音。
3、然而,现有的“通透模式”没法识别外界的声音哪些是有效的,哪些是噪声,因此将获取到的环境音整体放大,同理环境音中的噪声也一并放大,影响了用户的听歌体验和对外界有效音的获取。
技术实现思路
1、本发明目的一是提供一种耳机自识别噪声的方法,具有能解决现有技术中耳机在通透模式下无法准确识别出哪些是有效音和噪音,影响了用户的听歌体验和对外界有效音获取的问题。
2、本发明的上述发明目的一是通过以下技术方案得以实现的:
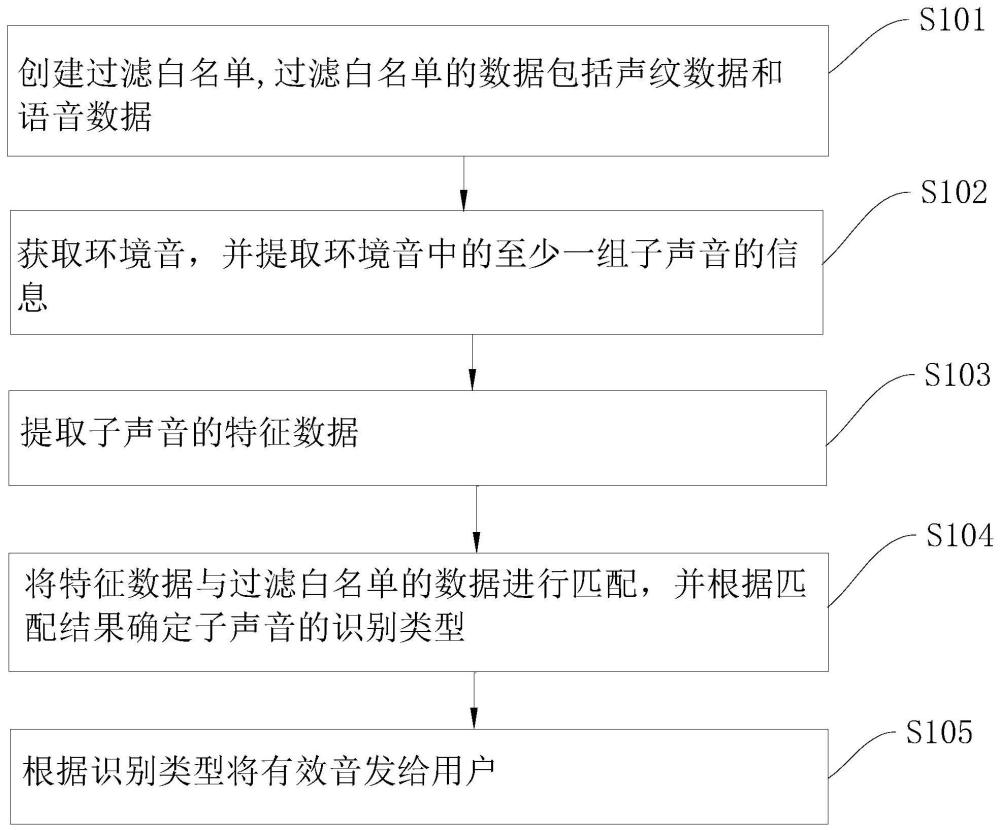
3、一种耳机自识别噪声的方法,包括如下步骤:
4、创建过滤白名单,所述过滤白名单的数据包括至少一条标准声音的信息,所述标准声音的信息包括声纹数据信息和语音数据信息;
5、获取环境音,并提取所述环境音中至少一组子声音的信息,所述不同子声音的信息由不同的音源发出;
6、提取所述子声音的特征数据,所述特征数据包括目标声纹数据和目标语音数据;
7、将所述特征数据与所述过滤白名单的数据进行匹配,并根据匹配结果确定所述子声音的识别类型,所述识别类型包括有效音、噪音和待定音;
8、根据所述识别类型将有效音发送给用户。
9、通过采用上述技术方案,先设定好过滤白名单,符合过滤白名单标准的声音被视为有效音。当获取到环境音后,将环境音中不同音源发出的声音进行提取,并对提取后的声音分别进行识别。识别从两个维度进行,即声纹数据和语音数据,声纹数据对应发声对象本体,语音数据对应声音中包括的信息内容,在预设的识别规则下,通过将被识别声音的声纹数据和语音数据与过滤白名单的数据进行比对,能够更人性化地识别声音是否为有效,使识别结果更符合用户的需要。最后,再根据识别类型执行将有效音传递给用户,让用户获取到自己想要的信息。本方案改善了现有技术中的耳机在通透模式下无法准确识别出哪些是有效音和噪音,从而影响用户的听歌体验和对外界有效音获取的问题。
10、本发明在一较佳示例中可以进一步配置为:所述创建过滤白名单,包括:
11、获取目标声音,并将所述目标声音作为所述标准声音;
12、提取所述目标声音中的标准语音数据和标准声纹数据;
13、将所述标准语音数据和标准声纹数据更新至所述过滤白名单内。
14、通过采用上述技术方案,能够让用户根据自身需要获取有效的声音,例如警报声,或者其他人喊自己的名字的声音,目标声音获取得越多,过滤白名单的内容便越丰富,从而能够覆盖更多的声音判断场景,使得耳机自识别噪声的能力越强。
15、本发明在一较佳示例中可以进一步配置为:将所述特征数据与所述过滤白名单的数据进行匹配,并根据匹配结果确定所述子声音的识别类型,包括:
16、判断所述目标语音数据与所述标准语音数据是否匹配;
17、若是,则识别所述子声音为有效音;
18、若否,则判断所述目标声纹信息与所述标准声纹数据是否匹配,若匹配,则识别所述子声音为待定音,否则,识别所述子声音为噪声。
19、通过采用上述技术方案,优先判断目标语音数据与标准语音数据是否匹配,能够帮助用户快速地获取自己想听的信息;当目标语音数据与标准语音数据不匹配,则说明该目标语音数据不是用户想听的内容;通过判断声纹信息是否与标准声纹信息是否匹配,如果匹配则说明该声源的对象为用户关注的对象,因此判定为待定音,便于用户后续自行决定是否要获取该声音。当识别为噪声时,则说明该声音没有任和用户想了解的信息。
20、本发明在一较佳示例中可以进一步配置为:所述判断所述目标语音数据与所述标准语音数据是否匹配,包括:
21、将所述目标语音数据转换为第一文字数据,并将所述标准语音数据转化为第二文字数据;
22、对所述第一文字数据和第二文字数据进行语义分析,并通过判断语义分析结果是否一致来判断所述目标语音数据与所述标准语音数据是否匹配。
23、通过采用上述技术方案,能够让用户获取到与标准语音数据语义相似的信息,使识别效果更加人性化。
24、本发明在一较佳示例中可以进一步配置为:所述根据所述识别类型将有效音发送给用户,包括:
25、放大所述子声音的音量,并发送给用户。
26、通过采用上述技术方案,便于用户听到自己想要的信息。
27、本发明在一较佳示例中可以进一步配置为:所述根据所述识别类型将有效音发送给用户,还包括:
28、当识别所述子声音为噪音时,则过滤所述子声音。
29、通过采用上述技术方案,使得呈现给用户的干扰项声音更少。
30、本发明在一较佳示例中可以进一步配置为:所述根据所述识别类型将有效音发送给用户,还包括:
31、当识别所述子声音为待定音时,则提示存在所述子声音,并接收判定指令,所述判定指令用于更改所述子声音为有效音或噪音。
32、通过采用上述技术方案,能够让用户自己决定对待定音的处理方式,提高了交互性和体验感。
33、本发明在一较佳示例中可以进一步配置为:所述方法,还包括:
34、接收优先级设定指令,根据所述优先级设定指令对不同的所述标准声音标记对应的优先级。
35、通过采用上述技术方案,当识别出多个有效音时,根据有效音所匹配的标准声音的优先级,来确定出多个有效音的播放优先级,从而能够帮助用户在多个有效音中能更快地获取到最想要的信息。
36、本发明在一较佳示例中可以进一步配置为:所述根据所述识别类型将有效音发送给用户,还包括:
37、当识别出至少两个有效音时,根据所述优先级对两个所述有效音依次进行播放。
38、通过采用上述技术方案,通过对有效音播放顺序进行调整,能够帮助用户更快地从多个有效音中获取到最想要的信息。
39、本发明目的二是提供一种耳机自识别噪声的系统,具有能解决现有技术中的耳机在通透模式下无法准确识别出哪些是有效音和噪音的问题。
40、本发明的上述发明目的二是通过以下技术方案得以实现的:
41、一种耳机自识别噪声的系统,包括:
42、创建模块,用于创建过滤白名单,过滤白名单的数据包括至少一条标准声音的信息,标准声音的信息包括声纹数据信息和语音数据信息;
43、获取模块,用于获取环境音,并提取环境音中的至少一个子声音,不同子声音由不同的音源发出;
44、提取模块,用于提取子声音的特征数据,特征数据包括目标声纹数据和目标语音数据;
45、识别模块,用于将特征数据与过滤白名单的数据进行匹配,并根据匹配结果确定子声音的识别类型,识别类型包括有效音、噪音和待定音;
46、声音处理模块,用于根据识别类型将有效音发送给用户。
47、通过采用上述技术方案,创建模块创建过滤白名单,并将过滤白名单的数据发送至识别模块;获取模块获取环境音,并提取环境音中的至少一个子声音,并将子声音发送至提取模块;提取模块提取子声音的特征数据,并将特征数据发送至识别模块;识别模块将特征数据与过滤白名单的数据进行匹配,并根据匹配结果确定子声音的识别类型。
48、本发明在一较佳示例中可以进一步配置为:创建模块包括采集单元、处理单元和更新单元,其中:
49、采集单元,获取目标声音,并将目标声音作为标准声音;
50、处理单元,用于提取目标声音中的标准语音数据和标准声纹数据;
51、更新单元,用于将标准语音数据和标准声纹数据更新至过滤白名单内。
52、本发明在一较佳示例中可以进一步配置为:识别模块包括第一判断单元、第一识别单元、第二判断单元、第二识别单元和第三识别单元,其中:
53、第一判断单元,用于判断目标语音数据与标准语音数据是否匹配;
54、第一识别单元,用于当第一判断单元判断目标语音数据与标准语音数据匹配时,识别子声音为有效音;
55、第二判断单元,用于当第一判断单元判断目标语音数据与标准语音数据不匹配时,判断目标声纹信息与标准声纹信息是否匹配;
56、第二识别单元,用于当第二判断单元判断目标声纹信息与标准声纹信息不匹配时,识别子声音为噪音;
57、第三识别单元,用于当第二判断单元判断目标声纹信息与标准声纹信息匹配时,识别子声音为待定音。
58、本发明在一较佳示例中可以进一步配置为:第一判断单元包括:
59、转换子单元,用于将目标语音数据转换为第一文字数据,并将标准语音数据转化为第二文字数据;
60、分析子单元,用于对所述第一文字数据和第二文字数据进行语义分析,并通过判断语义分析结果是否一致来判断目标语音数据与标准语音数据是否匹配。
61、本发明在一较佳示例中可以进一步配置为:声音处理模块包括放大/发送单元:
62、放大/发送单元,用于当识别子声音为有效音时,放大子声音的音量,并发送给用户。
63、本发明在一较佳示例中可以进一步配置为:声音处理模块还包括过滤单元:
64、过滤单元,用于当识别子声音为噪音时,则过滤子声音。
65、本发明在一较佳示例中可以进一步配置为:声音处理模块还包括判定单元:
66、判定单元,用于当识别子声音为待定音时,提示存在子声音,并接收判定指令,判定指令用于更改子声音为有效音或噪音。
67、本发明在一较佳示例中可以进一步配置为:系统还包括设定模块:
68、设定模块,用于接收优先级设定指令,根据所述优先级设定指令对不同的所述标准声音标记对应的优先级。
69、本发明在一较佳示例中可以进一步配置为:声音处理模块还包括播放单元:
70、播放单元,用于当识别出至少两个有效音时,根据优先级对两个有效音依次进行播放。
71、综上所述,本发明包括以下至少一种有益技术效果:
72、1.通过先设定好过滤白名单,符合过滤白名单标准的声音被视为有效音。当获取到环境音后,将环境音中不同音源发出的声音进行提取,并对提取后的声音分别进行识别。识别从两个维度进行,即声纹数据和语音数据,在预设的识别规则下,通过对目标声音的声纹数据和语音数据与过滤白名单的数据进行比对,能够对声音的判断更为准确,从而使识别结果更符合用户的需要,解决现有技术中的耳机在通透模式下无法准确识别出哪些是有效音和噪音的问题。
73、2.用户能够通过麦克风获取自认为有效的声音,例如警报声,或者其他人喊自己的名字的声音,目标声音获取得越多,过滤白名单的内容便越丰富,从而能够覆盖更多的声音判断场景,使得耳机自识别噪声的能力越强。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23432.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。