生成参数化空间音频表示的制作方法
- 国知局
- 2024-06-21 11:46:09
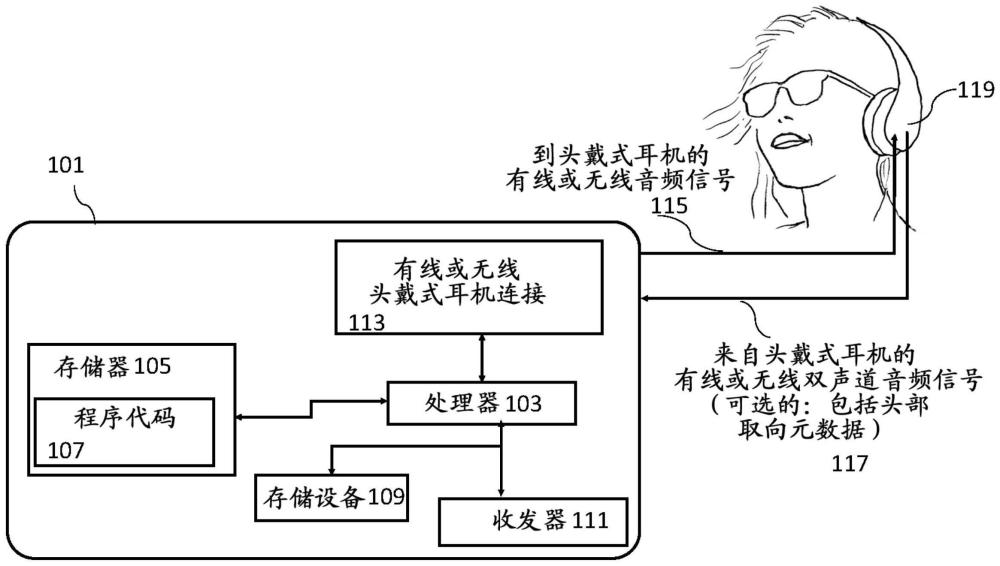
本技术涉及用于生成参数化空间音频表示的装置和方法,但是不是排他地用于从音频编码器的双声道记录生成参数化空间音频表示。
背景技术:
1、捕获空间音频的方法有很多。一种选项是使用例如作为移动设备的一部分的麦克风阵列捕获空间音频。使用麦克风信号,可以执行声音场景的空间分析以确定频带中的空间元数据。此外,可以使用麦克风信号来确定传输音频信号。空间元数据和传输音频信号可以被组合以形成空间音频流。
2、元数据辅助空间音频(masa)是空间音频流的一个示例。它是即将来临的沉浸式语音和音频服务(ivas)编解码器将支持的输入格式之一。它使用音频信号以及对应的空间元数据(包含例如频带中的方向和直接能量与总能量比(direct-to-total energy ratios))和描述性元数据(包含与例如原始捕获和(传输)音频信号相关的附加信息)。masa流可以例如通过用例如移动设备的麦克风捕获空间音频来获得,其中空间元数据集是基于麦克风信号来估计的。masa流还可以从其他来源获得,例如特定的空间音频麦克风(例如高保真度立体声响复制(ambisonics))、工作室混音(mix)(例如5.1混音)或借助适当格式转换的其他内容。还可以在编解码器内使用masa工具,通过将多通道信号转换为masa流并对该流进行编码来对该多通道通道信号进行编码。
技术实现思路
1、根据第一方面,提供了一种用于生成空间音频流的方法,所述方法包括:获得来自至少两个麦克风的至少两个音频信号;从所述至少两个音频信号提取第一音频信号,所述第一音频信号至少部分地包括用户的语音;从所述至少两个音频信号提取第二音频信号,其中所述用户的语音在所述第二音频信号内基本不存在;以及对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流,以使得能够将所述用户的语音渲染(render)到可控方向和/或距离。
2、所述空间音频流还可以使得能够可控渲染所捕获的环境(ambience)音频内容。
3、从所述至少两个音频信号提取所述第一音频信号还可以包括:将机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号。
4、将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号可以进一步包括:基于所述至少两个音频信号生成第一语音掩模;以及基于将所述第一语音掩模应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号,将所述至少两个音频信号分离成经掩模处理的语音音频信号和经掩模处理的剩余音频信号。
5、从所述至少两个音频信号提取所述第一音频信号还可以包括对所述至少两个音频信号进行波束成形以生成语音音频信号。
6、对所述至少两个音频信号进行波束成形以生成所述语音音频信号可以包括:基于所述经掩模处理的语音音频信号来确定用于所述波束成形的导向向量;基于所述经掩模处理的剩余音频信号确定剩余协方差矩阵;以及应用基于所述导向向量和所述剩余协方差矩阵所配置的波束成形器来生成波束音频信号。
7、将所述机器学习模型应用所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号还可以包括:基于所述波束音频信号生成第二语音掩模;以及基于所述第二语音掩模对所述波束音频信号应用增益处理以生成所述语音音频信号。
8、将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个信号以生成所述第一音频信号还可以进一步包括:均衡所述第一音频信号。
9、将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号可以包括:基于经训练的网络生成至少一个语音掩模。
10、从所述至少两个音频信号提取所述第二音频信号可以包括:从所述语音音频信号生成定位语音音频信号;以及从所述至少两个音频信号中减去所述定位语音音频信号以生成所述至少一个剩余音频信号。
11、从所述语音音频信号生成所述定位语音音频信号可以包括基于所述导向向量从所述语音音频信号生成所述定位语音音频信号。
12、从所述至少两个音频信号提取包括所述用户的语音的所述第一音频信号可以包括:基于所述至少两个音频信号生成所述第一音频信号;生成音频对象表示,所述音频对象表示包括所述第一音频信号。
13、从所述至少两个音频信号提取所述第一音频信号还可以包括:分析所述至少两个音频信号以确定相对于与所述用户的所述语音相关联的麦克风的方向和/或位置,其中所述音频对象表示还可以包括相对于所述麦克风的所述方向和/或位置。
14、生成所述第二音频信号还可以包括:生成双声道音频信号。
15、对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流可以包括:对所述第一音频信号和所述第二音频信号进行混音以生成至少一个传输音频信号;确定与所述用户的所述语音的期望方向或位置相关联的至少一个方向或位置空间参数;对所述至少一个传输音频信号和所述至少一个方向或位置空间参数进行编码以生成所述空间音频流。
16、所述方法还可以包括获得能量比参数,并且其中对所述至少一个传输音频信号和所述至少一个方向或位置空间参数进行编码可以包括进一步对所述能量比参数进行编码。
17、所述第一音频信号可以是单通道音频信号。
18、所述至少两个麦克风可以位于所述用户的耳朵上或附近。
19、所述至少两个麦克风可以是接近的麦克风。
20、所述至少两个麦克风可以位于包括作为第一音频源的所述用户和另一音频源的音频场景中,并且所述方法还可以包括:从所述至少两个音频信号提取至少一个其它第一音频信号,所述至少一个其它第一音频信号至少部分地包括所述另一音频源;以及从所述至少两个音频信号提取至少一个其它第二音频信号,其中所述另一音频源在所述至少一个其它第二音频信号内基本不存在,或者所述另一音频源在所述第二音频信号内。
21、所述第一音频源可以是讲话者并且所述另一音频源可以是另一讲话者。
22、根据第二方面,提供了一种用于生成空间音频流的装置,所述装置包括设备,所述设备被配置为:获得来自至少两个麦克风的至少两个音频信号;从所述至少两个音频信号提取第一音频信号,所述第一音频信号至少部分地包括用户的语音;从所述至少两个音频信号提取第二音频信号,其中所述用户的语音在所述第二音频信号内基本不存在;以及对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流,以使得能够将所述用户的语音渲染到可控方向和/或距离。
23、所述空间音频流还使得能够可控渲染所捕获的环境音频内容。
24、被配置为从所述至少两个音频信号提取所述第一音频信号的设备还可以被配置为将机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号。
25、被配置为将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号的设备还可以被配置为:基于所述至少两个音频信号生成第一语音掩模;以及基于将所述第一语音掩模应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号,将所述至少两个音频信号分离成经掩模处理的语音音频信号和经掩模处理的剩余音频信号。
26、被配置为从所述至少两个音频信号提取所述第一音频信号的设备还可以被配置为对所述至少两个音频信号进行波束成形以生成语音音频信号。
27、被配置为对所述至少两个音频信号进行波束成形以生成所述语音音频信号的设备可以被配置为:基于所述经掩模处理的语音音频信号来确定用于所述波束成形的导向向量;基于所述经掩模处理的剩余音频信号确定剩余协方差矩阵;以及应用基于所述导向向量和所述剩余协方差矩阵所配置的波束成形器来生成波束音频信号。
28、被配置为将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号的设备还可以被配置为:基于所述波束音频信号生成第二语音掩模;以及基于所述第二语音掩模对所述波束音频信号应用增益处理以生成所述语音音频信号。
29、被配置为将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个信号以生成所述第一音频信号的设备还可以被配置为均衡所述第一音频信号。
30、被配置为将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号的设备还可以被配置为基于经训练的网络生成至少一个语音掩模。
31、被配置为从所述至少两个音频信号提取所述第二音频信号的设备可以被配置为:从所述语音音频信号生成定位语音音频信号;以及从所述至少两个音频信号中减去所述定位语音音频信号以生成所述至少一个剩余音频信号。
32、被配置为从所述语音音频信号生成所述定位语音音频信号的设备还可以被配置为基于所述导向向量从所述语音音频信号生成所述定位语音音频信号。
33、被配置为从所述至少两个音频信号提取包括所述用户的语音的所述第一音频信号的设备可以被配置为:基于所述至少两个音频信号生成所述第一音频信号;以及生成音频对象表示,所述音频对象表示包括所述第一音频信号。
34、被配置为从所述至少两个音频信号提取所述第一音频信号的设备还可以被配置为分析所述至少两个音频信号以确定相对于与所述用户的所述语音相关联的麦克风的方向和/或位置,其中所述音频对象表示还可以包括相对于所述麦克风的所述方向和/或位置。
35、被配置为生成所述第二音频信号的设备还可以被配置为:生成双声道音频信号。
36、被配置为对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流的设备可以被配置为:对所述第一音频信号和所述第二音频信号进行混音以生成至少一个传输音频信号;确定与所述用户的所述语音的期望方向或位置相关联的至少一个方向或位置空间参数;以及对所述至少一个传输音频信号和所述至少一个方向或位置空间参数进行编码以生成所述空间音频流。
37、所述设备还可以被配置为获得能量比参数,并且其中被配置为对所述至少一个传输音频信号和所述至少一个方向或位置空间参数进行编码的所述设备可以进一步被配置为:对所述能量比参数进行编码。
38、所述第一音频信号可以是单通道音频信号。
39、所述至少两个麦克风可以位于所述用户的耳朵上或附近。
40、所述至少两个麦克风可以是接近的麦克风。
41、所述至少两个麦克风可以位于包括作为第一音频源的所述用户和另一音频源的音频场景中,并且所述设备还可以被配置为:从所述至少两个音频信号提取至少一个其它第一音频信号,所述至少一个其它第一音频信号至少部分地包括所述另一音频源;以及从所述至少两个音频信号提取至少一个其它第二音频信号,其中所述另一音频源在所述至少一个其它第二音频信号内基本上不存在,或者所述另一音频源在所述第二音频信号内。
42、所述第一音频源可以是讲话者并且所述另一音频源可以是另一讲话者。
43、根据第三方面,提供了一种用于生成空间音频流的装置,所述装置包括至少一个处理器和存储指令的至少一个存储器,所述指令当由所述至少一个处理器执行时使系统至少执行:获得来自至少两个麦克风的至少两个音频信号;从所述至少两个音频信号提取第一音频信号,所述第一音频信号至少部分地包括用户的语音;从所述至少两个音频信号提取第二音频信号,其中所述用户的语音在所述第二音频信号内基本不存在;以及对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流,以使得能够将所述用户的语音渲染到可控方向和/或距离。
44、所述空间音频流还使得能够可控渲染所捕获的环境音频内容。
45、被使得执行从所述至少两个音频信号提取所述第一音频信号的所述系统还可以被使得执行:将机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号。
46、被使得执行将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号的所述系统还可以被使得执行:基于所述至少两个音频信号生成第一语音掩模;以及基于将所述第一语音掩模应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号,将所述至少两个音频信号分离为经掩模处理的语音音频信号和经掩模处理的剩余音频信号。
47、被使得执行从所述至少两个音频信号提取所述第一音频信号的所述系统还可以被使得执行对所述至少两个音频信号进行波束成形以生成语音音频信号。
48、被使得执行对所述至少两个音频信号进行波束成形以生成所述语音音频信号的所述系统还可以被使得执行:基于所述经掩模处理的语音音频信号来确定用于所述波束成形的导向向量;基于所述经掩模处理的剩余音频信号确定剩余协方差矩阵;以及应用基于所述导向向量和所述剩余协方差矩阵所配置的波束成形器来生成波束音频信号。
49、被使得执行将所述机器学习模型应用所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号的所述系统还可以被使得执行:基于所述波束音频信号生成第二语音掩模;以及基于所述第二语音掩模对所述波束音频信号应用增益处理以生成所述语音音频信号。
50、被使得执行将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个信号以生成所述第一音频信号的所述系统还可以被使得执行均衡所述第一音频信号。
51、被使得执行将所述机器学习模型应用于所述至少两个音频信号或基于所述至少两个音频信号的至少一个音频信号以生成所述第一音频信号的所述系统可以被使得执行基于经训练的网络生成至少一个语音掩模。
52、被使得执行从所述至少两个音频信号提取所述第二音频信号的所述系统可以被使得执行:从所述语音音频信号生成定位语音音频信号;以及从所述至少两个音频信号中减去所述定位语音音频信号以生成所述至少一个剩余音频信号。
53、被使得执行从所述语音音频信号生成所述定位语音音频信号的所述系统可以被使得执行基于所述导向向量从所述语音音频信号生成所述定位语音音频信号。
54、被使得执行从所述至少两个音频信号提取包括所述用户的语音的所述第一音频信号的所述系统可以被使得执行:基于所述至少两个音频信号生成所述第一音频信号;生成音频对象表示,所述音频对象表示包括所述第一音频信号。
55、被使得执行从所述至少两个音频信号提取所述第一音频信号的所述系统还可以被使得执行分析所述至少两个音频信号以确定相对于与所述用户的所述语音相关联的麦克风的方向和/或位置,其中所述音频对象表示还可以包括相对于所述麦克风的所述方向和/或位置。
56、被使得执行生成所述第二音频信号的所述系统还可以被使得执行生成双声道音频信号。
57、被使得执行对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流的所述系统还可以被使得执行:对所述第一音频信号和所述第二音频信号进行混音以生成至少一个传输音频信号;确定与所述用户的所述语音的期望方向或位置相关联的至少一个方向或位置空间参数;对所述至少一个传输音频信号和所述至少一个方向或位置空间参数进行编码以生成所述空间音频流。
58、可以进一步使所述系统执行获得能量比参数,并且其中被使得执行对所述至少一个传输音频信号和所述至少一个方向或位置空间参数进行编码的所述系统可以进一步被使得执行对所述能量比参数进行编码。
59、所述第一音频信号可以是单通道音频信号。
60、所述至少两个麦克风可以位于所述用户的耳朵上或附近。
61、所述至少两个麦克风可以是接近的麦克风。
62、所述至少两个麦克风可以位于包括作为第一音频源的所述用户和另一音频源的音频场景中,并且可以进一步使得所述系统执行:从所述至少两个音频信号提取至少一个其它第一音频信号,所述至少一个其它第一音频信号至少部分地包括所述另一音频源;以及从所述至少两个音频信号提取至少一个其它第二音频信号,其中所述另一音频源在所述至少一个其它第二音频信号内基本不存在,或者所述另一音频源在所述第二音频信号内。
63、所述第一音频源可以是讲话者并且所述另一音频源可以是另一讲话者。
64、根据第四方面,提供了一种用于生成空间音频流的装置,所述装置包括:获得电路,其被配置为获得来自至少两个麦克风的至少两个音频信号;提取电路,其被配置为从所述至少两个音频信号提取第一音频信号,所述第一音频信号至少部分地包括用户的语音;提取电路,其被配置为从所述至少两个音频信号提取第二音频信号,其中所述用户的语音在所述第二音频信号内基本不存在;以及编码电路,其被配置为对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流,使得能够将所述用户的语音渲染到可控方向和/或距离。
65、根据第五方面,提供了一种包括指令的计算机程序[或包括指令的计算机可读介质],所述指令用于使装置生成空间音频流,所述装置被使得执行至少以下:获得来自至少两个麦克风的至少两个音频信号;从所述至少两个音频信号提取第一音频信号,所述第一音频信号至少部分地包括用户的语音;从所述至少两个音频信号提取第二音频信号,其中所述用户的语音在所述第二音频信号内基本不存在;以及对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流,使得能够将所述用户的语音渲染到可控方向和/或距离。
66、根据第六方面,提供了一种包括程序指令的非暂时性计算机可读介质,所述程序指令用于使用于生成空间音频流的装置执行至少以下:获得来自至少两个麦克风的至少两个音频信号;从所述至少两个音频信号提取第一音频信号,所述第一音频信号至少部分地包括用户的语音;从所述至少两个音频信号提取第二音频信号,其中所述用户的语音在所述第二音频信号内基本不存在;以及对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流,使得能够将所述用户的语音渲染到可控方向和/或距离。
67、根据第七方面,提供了一种用于生成空间音频流的装置,所述装置包括:用于获得来自至少两个麦克风的至少两个音频信号的设备;用于从所述至少两个音频信号提取第一音频信号的设备,所述第一音频信号至少部分地包括用户的语音;用于从所述至少两个音频信号提取第二音频信号的设备,其中所述用户的语音在所述第二音频信号内基本不存在;以及用于对所述第一音频信号和所述第二音频信号进行编码以生成所述空间音频流使得能够将所述用户的语音渲染到可控方向和/或距离的设备。
68、一种装置,包括用于执行如上所述的方法的动作的设备。
69、一种装置,被配置为执行如上所述的方法的动作。
70、一种计算机程序,包括用于使计算机执行如上所述的方法的程序指令。
71、一种存储在介质上的计算机程序产品,可以使装置执行本文所描述的方法。
72、一种电子设备可以包括如本文所描述的装置。
73、一种芯片组可以包括如本文所描述的装置。
74、本技术的实施例旨在解决与现有技术相关的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23445.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。