一种基于分布式协同质检方法与流程
- 国知局
- 2024-06-21 11:46:20
本发明涉及通信,尤其涉及一种基于分布式协同质检方法。
背景技术:
1、传统的通过nlp语音识别,把音频转化成文字,再对文字做出“敏感词”、“敏感字”的正则或者上下文识别算法来鉴定违规内容的方式遇到了很多挑战。比如说,某些用户发出的语气助词,就是无法被翻译为文字,并且没有任何关键敏感词的,但超过一定的尺度则属于违规内容。
2、传统客服中心质检抽检量占全量2%。传统客服中心质检员配比1:40。每人每天最高抽检30条录音。人工质检查受主观因素影响,容易漏判语音中存在问题。海量的语音数据,没有通过系统化手段挖掘其中价值。
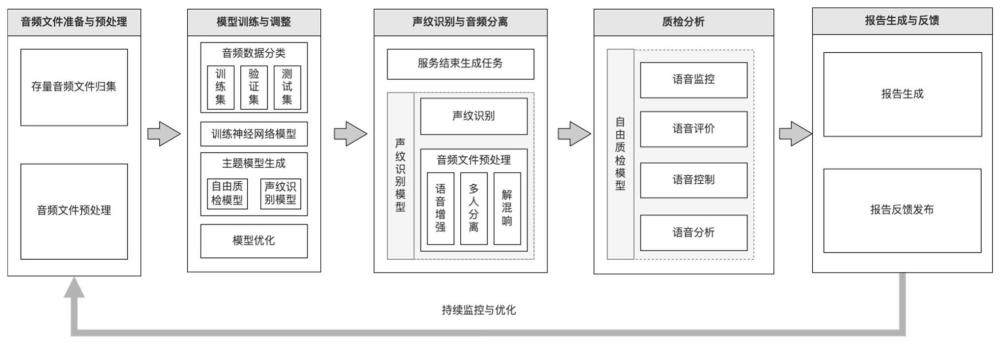
技术实现思路
1、本发明的目的在于提供一种基于分布式协同质检方法。基于云计算大数据采集能力,通过深度学习模型训练,智能语音/语义识别视频、语音内容,把控多媒体质检质量。
2、本发明采用的技术方案是:
3、一种基于分布式协同质检方法,其包括以下步骤:
4、步骤1,特征数据集预处理:获取音频文件并进行预处理得到fbank特征,形成特征数据集,特征数据集按设定比例分为训练集、验证集和测试集;
5、步骤2,构建神经网络:神经网络包括7层卷积、3层最大池化以及1层平均池化,使用relu激活函数以及softmax激活函数;各层排列方式为依次设置的输入层、第一卷积结构、第一最大池化层、第二卷积结构、第一线性单元、平均池化层、第一线性模块、第二线性单元;第一卷积结构包括两个卷积模块,每个卷积模块由两个卷积层、两个标准化层及两个relu激活函数构成,并以一个最大池化层结束以降低特征维度;第一最大池化层进一步压缩特征图;第二卷积结构由三个卷积单元组成,每个单元均设有卷积层、标准化层和relu激活函数,用于提取更深层次的特征;第一线性单元由一个线性层和relu函数组成,以将卷积特征转换为线性特征空间;平均池化层对特征进行全局池化,为分类决策做准备;第一线性模块包含两个第三线性单元,每个单元都包括一个线性层、标准化层及relu激活函数,以增强模型的非线性和学习能力;第二线性单元通过线性层和softmax激活函数输出概率分布,完成多类别识别;
6、具体地,架构起始于一个输入层,负责接收输入数据。紧接着是第一卷积结构,它包括两个卷积模块;每个卷积模块由两个卷积层、两个标准化层及两个relu激活函数构成,并以一个最大池化层结束,以降低特征维度。继第一卷积结构之后是一个最大池化层,进一步压缩特征图。第二卷积结构由三个卷积单元组成,每个单元均设有卷积层、标准化层和relu激活函数,用于提取更深层次的特征。随后的第一线性单元由一个线性层和relu函数组成,将卷积特征转换为线性特征空间。之后,平均池化层对特征进行全局池化,为分类决策做准备。第一线性模块包含两个第三线性单元,每个单元都包括一个线性层、标准化层及relu激活函数,以增强模型的非线性和学习能力。最终,第二线性单元通过线性层和softmax激活函数输出概率分布,完成多类别识别。该架构通过有序层叠的方式精确控制数据流,确保了从初级特征提取到复杂分类决策的高效转换。
7、步骤3,对构建好的神经网络进行模型训练得到自由质检模型和声纹识别模型;
8、步骤4,利用训练好的模型对客服业务场景的语音大数据进行声纹识别与音频分离,并基于分离的音频文件进行质检分析得到对应质检报告。
9、进一步地,步骤1包括以下步骤:
10、步骤1-1,以指定采样率对音频文件进行采样,采样后存储为wav格式;
11、步骤1-2,以设定的时间间隔对采样后的音频进行分帧;
12、步骤1-3,计算音频的能量谱获得mel滤波系数,并对mel滤波系数取对数得到fbank特征。
13、进一步地,步骤1-1中以16khz的采样率进行采样,步骤1-2中设定的时间间隔为0.64s。具体地,将音频文件以16khz的采样率进行采样,采样完成后,以.wav格式存储。以0.64s的时间间隔来进行分帧,便于后续64×64维度的卷积神经网络的输入。计算能量谱之后获得mel滤波系数,对mel滤波系数取对数,得到fbank特征。
14、进一步地,步骤3中自由质检模型模型参数包括以下维度:
15、信息维度:随路数据检测,质检更准确;
16、话术维度:深刻理解话术内容,指定检测角色、检测范围,支持流程检测;
17、交互维度:静默、抢话、重复话术;
18、特征维度:句长、句式、语速、音量、情绪分析。
19、进一步地,步骤3具体包括以下步骤:
20、步骤3-1,基于神经网络创建自由质检模型,利用特征数据集对自由质检模型进行训练,并根据多次训练结果纠正参数权重,实现对于语音录音的监测、评价及控制;
21、步骤3-2,基于神经网络创建声纹识别模型,利用特征数据集对声纹识别模型进行训练,训练结束之后保存为预测模型,以实现对客服的声纹识别;
22、进一步地,步骤3-2具体包括以下步骤:
23、步骤3-2-1,以加性角度间隔损失函数为模型参数对特征向量和权重归一化,对加性角度间隔损失函数θ加上角度间隔m;
24、步骤3-2-2,用预测模型预测测试集中的音频特征,然后使用音频特征进行两两对比,阈值从0到1,步长为0.01进行控制找到最佳的阈值并计算准确率;
25、步骤3-2-3,进行声纹对比:输入两个语音通过预测模型的预测函数获取两者的特征数据,并求两者之间的对角余弦值作为两者之间的相似度;特征数据包括分类输出和音频特征输出值;
26、步骤3-2-4,在声纹对比的基础上创建infer_recognition.py实现声纹识别;使用声纹对比的infer()预测函数获取语音的特征数据,以便系统利用声纹识别函数完成客服的声纹识别。
27、进一步地,步骤4具体包括以下步骤:
28、步骤4-1,声纹识别与音频分离:当质检对象服务结束产生待质检任务时,利用训练好的声纹识别模型识别出不同对象的声纹;
29、步骤4-2,对音频文件执行语音分离任务,语音分离任务包括语音增强、多说话人分离和解混响;
30、步骤4-3,使用训练好的自由质检模型对语音进行监测、评价及控制;
31、步骤4-4,对音频文件进行细致分析,识别出问题区域,问题区域包括服务态度、专业程度、回答的准确性;
32、步骤4-5,报告生成与反馈:根据分析结果生成详细的质检报告,将报告反馈给相关的团队或个人,提出改进建议或表扬。
33、进一步地,步骤4-2具体包括以下步骤:
34、步骤4-2-1,基于mask方法或者频谱映射方法进行语音增强,
35、步骤4-2-2,多说话人分离分:多说话人分为如下情形:目标说话人和干扰说话人都固定;有监督分离目标说话人固定,训练阶段和测试阶段的干扰说话人可变;半监督分离目标说话人和干扰说话人都可变;无监督分离;
36、对于有监督和半监督分离使用基于频谱映射的方法进行多说话人分离分,对于无监督分类,使用无监督聚类、深度聚类以及序列不变训练pit方法进行多说话人分离分;
37、具体地,多说话人分为如下情形:目标说话人和干扰说话人都固定;有监督分离目标说话人固定,训练阶段和测试阶段的干扰说话人可变;半监督分离目标说话人和干扰说话人都可变;无监督分离。进一步地,序列不变训练pit方法的核心在误差回传的时,分别计算输出序列和标注序列间各种组合的均方误差,然后选取最小均方误差作为回传误差,即根据自动找到的声源间的最佳匹配进行优化,避免出现序列模糊的问题。
38、步骤4-2-3,基于频谱映射方法进行解混响:将带混响的语音在时域上进行卷积,并将干净语音做标注形成带标注数据。
39、具体地,解混响中生成训练数据,但不同于带噪语音生成时做时域的相加,带混响的语音是在时域上进行卷积,把干净语音作为带标注数据。
40、进一步地,步骤4-2-1中基于mask方法时,首先进行耳蜗滤波,然后特征提取、时频单元分类、二值掩蔽、后处理,得到增强后的语音;步骤4-2-1中基于频谱映射的方法时,先特征提取,用深度神经网络学习带噪语音和干净语音的对数功率谱之间映射关系,再加上波形重建得到增强后的语音。
41、进一步地,还包括步骤5:定期重复步骤4不断监控客服的表现,并根据实际情况调整神经网络模型,确保持续有效地适应新的数据和场景。
42、本发明采用以上技术方案,在现有客服质检体系的基础上,利用智能语音识别技术,优化人工抽检服务质量的方式,通过智能语音识别系统与质检系统、人工抽检与系统质检的全面融合,建立一套常规质检和专项质检相结合的质量管控手段,扩大质检覆盖范围,提高质检效率。
43、本发明具有如下技术优点,实现100%覆盖所有录音,日处理语音量可达1000小时。系统根据设定模板打分,能有效降低主观因素导致的差错率。如果音频并非识别为文字,可通过大数据算法,对声音的频率、音色等进行分析,识别违规敏感内容。本发明可以为音频打上标签、分类的信息,有助于业务的精细化运营。通过热点分析、聚类分析、分类分析等多种分析方法,挖掘录音价值。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23469.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表