基于超声波感知的交互不受限语音增强方法、系统及终端
- 国知局
- 2024-06-21 11:46:53
本发明涉及语音增强,特别是涉及一种基于超声波感知的交互不受限语音增强方法、系统及终端。
背景技术:
1、随着语音识别和自然语言处理的发展,通过语音与各种移动终端进行交互的用户语音接口(vui)已经成为人类生活中必不可少的一部分。通过语音,可以根据唤醒词对移动终端的语音助手进行唤醒,例如可以通过“hey,siri”或者“小艺小艺”等设置在移动终端上的关键词,快速唤醒语音助手,然后通过语音,进一步与语音助手交互。通过语音,可以进行身份的认证从而完成相应设备或终端的解锁。这种解锁,依赖于用户特定的声纹作为特征进行判断。据统计,在2000例与声纹相关的案件中,声纹认证错误的失败率仅为0.31%。其可靠性使得越来越多的终端支持通过语音进行解锁,比如android设备上的谷歌助手支持语音命令解锁功能,用户可以说出“ok google”来激活设备,并执行包括解锁在内的操作;三星设备使用bixby语音助手,允许用户通过语音命令解锁手机。另外,语音也是在人与人之间通过移动终端进行交流的重要媒介之一。除了传统的电话交流渠道外,越来越多的人也会选择通过微信语音消息或者微信电话的方式进行沟通。由此可见,随着技术的发展,语音接口已经极大地促进了人与移动终端之间交互方式的演进。
2、然而,这种交互方式会收到噪声的干扰。当语音中混合噪声时,会不可避免地降低唤醒词的识别率、声纹认证的准确性以及语音交流的清晰度和流利度,进而影响用户的使用体验和使用热情,并在一定程度上对使用场景产生限制(需要环境中没有强烈的噪声)。语音增强技术的出现能够很好地解决由噪声带来的困扰。语音增强指的是在不改变目标说话人语音信号原义的前提下,通过一定的技术手段消除语音信号中存在的噪声、失真、回声等杂音。
3、早期的语音增强技术主要基于信号处理方法,这些方法通过对语音和噪声的统计特性进行分析,尝试从含噪声的信号中恢复出干净的信号。例如,谱减法能够对含噪信号的频谱进行分析,估计噪声的功率谱,然后从含噪信号的功率谱中减去它。wiener滤波器则考虑了噪声和信号的功率谱密度比,通过最小化均方误差来改善信号的质量。但这些传统的语音增强方法往往依赖较强的先验知识,在实际使用过程中,无法应对复杂多变的噪声环境。
4、随着深度学习技术的兴起,神经网络被应用到语音增强领域,期望能够解决这种泛化性不足的问题。研究者们开始研究是否可以通过深度神经网络来挖掘含噪音频中潜在的目标说话人语音信号,并将其提取出来,进而实现语音增强的目的。深度学习技术通过大量的清晰和含噪语音数据对神经网络进行监督训练,通过神经网络强大的非线性拟合能力可以在日常生活中应对多变的噪声情况。
5、最初,研究者们仅依赖含噪音频作为神经网络的输入,来进行语音增强任务。本发明将这种仅使用音频模态进行语音增强的方法定义为纯音频模态(audio-only)语音增强。segan对噪声音频的时序序列进行建模,他们在时域处理中引入了对抗生成网络(gan)的思想,先训练一个鉴别器(discriminator)用来判断输入的音频序列是否含有噪声,然后再将这个鉴别器的权重固定,在鉴别器的指导下,训练一个生成器(generator)。这个生成器可以用来完成时域上的语音增强任务,其接收一个噪声音频信号序列,然后生成一个去噪后的音频信号序列。由于这种方法,直接对时域上的音频信号进行处理,因此也被称为tdomain的方法。而phasen则是一种典型的t-f(time-frequency)domain的方法。它首先将时域上的音频信号通过短时傅里叶变换转换为时频谱,然后再通过神经网络进行处理。其考虑了时频谱的幅度和相位分量,通过一种双流的神经网络结构分别对幅度和相位进行非线性映射,然后得到恢复后的音频频谱图,再通过逆傅里叶变换将频谱图转换为音频序列。这种t-f domain的方法由于考虑了频域信息,相较于t domain的方法往往可以取得更好的性能。然而由于其需要额外的信号处理过程,所以在处理速度上稍逊色于t domain的方法。不论是t domain还是t-f domain,这种纯音频模态的语音增强方法都具有很好的交互性。用户无需与移动终端保持特定的姿势条件,只要移动终端能够接收到用户的音频信号,即可利用这种方法对噪声音频进行处理。然而这类方法在仅依赖含噪音频作为输入的情况下,只能够对人的声音以及背景噪声进行区分。无法处理多说话人以及低信噪比等复杂噪声场景。当出现多说话人场景时,即含噪语音中同时包括目标说话人的语音信息以及其他说话人的语音信息时,仅通过音频中包含的信息无法从含噪语音中恢复出仅具有目标说话人语音信息的干净音频。这也一定程度上使得语音增强技术在移动终端上的使用场景受限。
6、为了解决含噪语音中的多说话人以及低信噪比等复杂问题,研究者们尝试引入额外的模态信息。心理学和生物学的研究表明,在嘈杂的环境中,观察说话者的嘴唇有助于听觉感知。因此,部分研究者尝试使用含噪音频以及与之对应的含有说话人面部或者唇部运动的视频序列作为输入,以此作为根据进行音频-视觉(audio-visual)语音增强。这种方法,可以借助视频序列作为线索,挖掘含噪音频中存在目标说话人的音频信息,很好地解决多说话人噪声以及低信噪比问题。然而,这种方法依赖额外的视频序列输入,会受到光照等条件的影响。另外,其需要摄像头作为支持来拍摄用户在说话时对应的面部或者唇部运动序列,不仅会带来隐私性问题,而且会限制用户与移动终端的交互姿态。
7、无线感知领域的研究者们,使用超声波信号代替视觉模态,实现了音频-超声波语音增强。他们利用智能设备上的扬声器来发出非侵入式的麦克风信号,通过麦克风来接收超声波信号,利用超声波信号来感知目标说话人在说话时的唇部运动,并以此作为线索,解决多说话人噪声以及低信噪比问题。这种方法相较于音频-视觉方法,不会带来隐私性问题。然而现有的基于超声波的方法的主要缺点是它们高度依赖于超声波信号的可用性,由于超声波信号极易受到距离和角度的影响,这种感知唇部运动的超声波方法在实际使用中,要求用户的唇部与移动终端的麦克风保持一定的角度和距离,导致交互性较差。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明的目的在于提供一种基于超声波感知的交互不受限语音增强方法、系统及终端,用于解决以上现有技术问题。
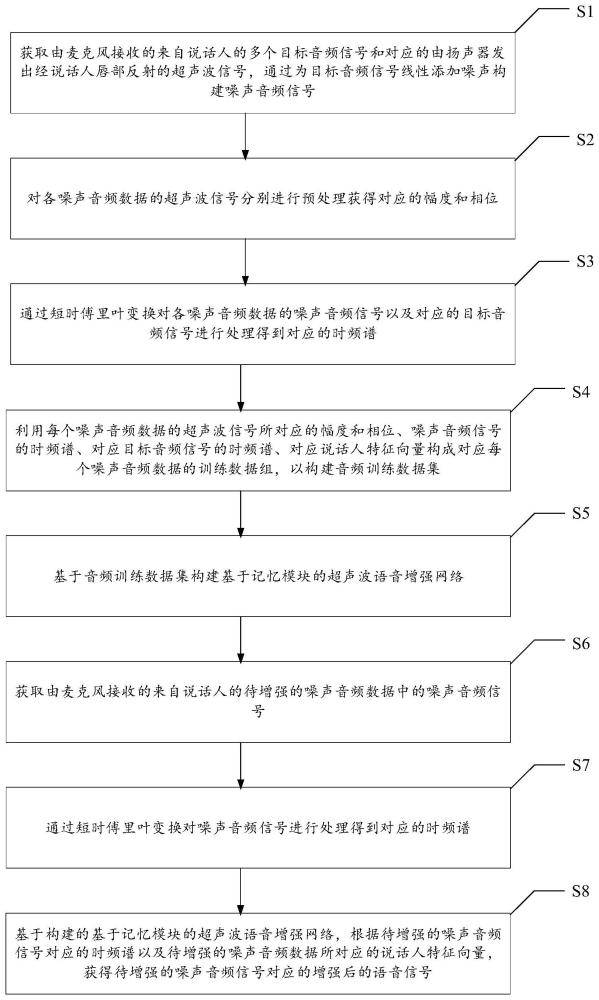
2、为实现上述目的及其他相关目的,本发明提供一种基于超声波感知的交互不受限语音增强方法,所述方法包括:获取由麦克风接收的来自说话人的多个目标音频信号和对应的由扬声器发出经说话人唇部反射的超声波信号,通过为目标音频信号线性添加噪声构建噪声音频信号;其中,噪声音频信号以及对应的超声波信号组成噪声音频数据;对各噪声音频数据的超声波信号分别进行预处理获得对应的幅度和相位;通过短时傅里叶变换对各噪声音频数据的噪声音频信号以及对应的目标音频信号进行处理得到对应的时频谱;利用每个噪声音频数据的超声波信号所对应的幅度和相位、噪声音频信号的时频谱、对应目标音频信号的时频谱、对应说话人特征向量构成对应每个噪声音频数据的训练数据组,以构建音频训练数据集;基于音频训练数据集构建基于记忆模块的超声波语音增强网络;获取由麦克风接收的来自说话人的待增强的噪声音频数据中的噪声音频信号;通过短时傅里叶变换对噪声音频信号进行处理得到对应的时频谱;基于构建的基于记忆模块的超声波语音增强网络,根据待增强的噪声音频信号对应的时频谱以及待增强的噪声音频数据所对应的说话人特征向量,获得待增强的噪声音频信号对应的增强后的语音信号。
3、于本发明的一实施例中,所述基于记忆模块的超声波语音增强网络包括:音频特征提取器、超声波特征提取器、记忆模块、解码器以及增强模块;其中,音频特征提取器,用于对输入的噪声音频信号的时频谱进行处理并与噪声音频信号所对应的说话人特征向量融合,提取音频特征向量;超声波特征提取器,用于对输入的超声波信号所对应的幅度和相位进行处理,提取超声波特征向量;记忆模块,用于输入提取的特征向量输出相应的虚拟超声波特征向量;其中,在训练阶段输入的特征向量为音频特征向量以及超声波特征向量,在推理阶段输入的特征向量为音频特征向量;解码器,用于将输入的提取的音频特征向量以及对应的虚拟超声波特征向量进行结合输出对应的增强语音的理想幅度掩码估计值;增强模块,用于将获得的理想幅度掩码估计值和对应的噪声音频信号的时频谱相乘,输出增强后的语音信号。
4、于本发明的一实施例中,所述基于音频训练数据集训练构建基于记忆模块的超声波语音增强网络的方式包括:将每个训练数据组中的噪声音频信号的时频谱以及对应的说话人特征向量输入至音频特征提取器提取对应的音频特征向量;将每个训练数据组中的超声波信号所对应的幅度和相位输入超声波特征提取器提取对应的超声波特征向量;将每个训练组对应的音频特征向量以及超声波特征向量输入至记忆模块输出每个训练组对应的两个虚拟超声波特征向量,以供与超声波特征向量共同作为输入超声波特征向量;将每个训练组对应的音频特征向量以及各输入超声波特征向量输入至解码器,获得对应每个训练组的各输入超声波特征向量的增强语音的理想幅度掩码估计值;将每个训练组的噪声音频信号的时频谱以及各理想幅度掩码估计值输入至增强模块相乘获得对应各理想幅度掩码估计值的增强后的语音信号;基于每个训练组的对应各理想幅度掩码估计值的增强后的语音信号以及目标音频信号的时频谱计算每个训练组的总模型损失,以调整基于记忆模块的超声波语音增强网络的参数,以获得最终的基于记忆模块的超声波语音增强网络。
5、于本发明的一实施例中,所述根据待增强的噪声音频信号对应的时频谱以及待增强的噪声音频数据所对应的说话人特征向量,获得待增强的噪声音频信号对应的增强后的语音信号包括:将待增强的噪声音频信号对应的时频谱以及对应的说话人特征向量输入至音频特征提取器提取对应的音频特征向量;将提取的音频特征向量输入至记忆模块输出对应的虚拟超声波特征向量;将待增强的噪声音频信号的音频特征向量以及虚拟超声波特征向量输入至解码器获得对应增强语音的理想幅度掩码估计值;将待增强的噪声音频信号对应的时频谱以及理想幅度掩码估计值输入至增强模块相乘获得对应的增强后的语音信号。
6、于本发明的一实施例中,所述记忆模块维护两个向量参数矩阵,且具有设定数量的槽;其中,两个向量参数矩阵包括:具有映射关系的音频向量参数矩阵以及超声波向量参数矩阵;所述记忆模块输入提取的特征向量输出相应的虚拟超声波特征向量的方式包括:对输入的特征向量量化出其与其对应的向量参数矩阵中每个槽的相似度;基于输入的特征向量对应的向量参数矩阵中每个槽的相似度计算输入的特征向量在对应的向量参数矩阵中的权重分布;基于输入的特征向量在对应的向量参数矩阵中的权重分布以及超声波向量参数矩阵计算获得对应输入的特征向量的虚拟超声波特征向量。
7、于本发明的一实施例中,所述基于每个训练组的对应各理想幅度掩码估计值的增强后的语音信号以及目标音频信号的时频谱计算每个训练组的总模型损失包括:计算每个训练组的超声波特征向量以及对应超声波特征向量的虚拟超声波特征向量的误差计算每个训练组的第一损失;计算每个训练组对应的音频特征向量在对应的音频向量参数矩阵中的权重分布与对应的超声波特征向量在对应的超声波向量参数矩阵中的权重分布之间的差异获得每个训练组的第二损失;基于每个训练组的对应各理想幅度掩码估计值的增强后的语音信号以及目标音频信号的时频谱计算每个训练组的第三损失;将每个训练组对应的第一损失、第二损失以及第三损失结合,获得每个训练组的总模型损失。
8、于本发明的一实施例中,所述基于每个训练组的对应各理想幅度掩码估计值的增强后的语音信号以及目标音频信号的时频谱计算每个训练组的第三损失包括:计算每个训练组的对应各理想幅度掩码估计值的增强后的语音信号的频谱幅度分别与对应目标音频信号的时频谱的频谱幅度的误差获得每个训练组的第三损失。
9、于本发明的一实施例中,所述对超声波信号分别进行预处理获得对应的幅度和相位的方式包括:对超声波信号进行滤波、滑窗均值采样提取i、q分量,得到相应的幅度和相位。
10、为实现上述目的及其他相关目的,本发明提供一种基于超声波感知的交互不受限语音增强系统,所述系统包括:信号获取模块,用于获取由麦克风接收的来自说话人的待增强的噪声音频数据中的噪声音频信号;噪声音频信号处理模块,连接所述信号获取模块,用于通过短时傅里叶变换对噪声音频信号进行处理得到对应的时频谱;语音增强模块,连接所述噪声音频信号处理模块,用于基于构建的基于记忆模块的超声波语音增强网络,根据待增强的噪声音频信号对应的时频谱以及待增强的噪声音频数据所对应的说话人特征向量,获得待增强的噪声音频信号对应的增强后的语音信号;其中,构建基于记忆模块的超声波语音增强网络的方式:获取由麦克风接收的来自说话人的多个目标音频信号和对应的由扬声器发出经说话人唇部反射的超声波信号,通过为目标音频信号线性添加噪声构建噪声音频信号;其中,噪声音频信号以及对应的超声波信号组成噪声音频数据;对各噪声音频数据的超声波信号分别进行预处理获得对应的幅度和相位;通过短时傅里叶变换对各噪声音频数据的噪声音频信号以及对应的目标音频信号进行处理得到对应的时频谱;利用每个噪声音频数据的超声波信号所对应的幅度和相位、噪声音频信号的时频谱、对应目标音频信号的时频谱、对应说话人特征向量构成对应每个噪声音频数据的训练数据组,以构建音频训练数据集;基于音频训练数据集构建基于记忆模块的超声波语音增强网络。
11、为实现上述目的及其他相关目的,本发明提供一种基于超声波感知的交互不受限语音增强终端,包括:一或多个存储器及一或多个处理器;所述一或多个存储器,用于存储计算机程序;所述一或多个处理器,连接所述存储器,用于运行所述计算机程序以执行所述基于超声波感知的交互不受限语音增强方法。
12、如上所述,本发明是一种基于超声波感知的交互不受限语音增强方法、系统及终端,具有以下有益效果:本发明通过短时傅里叶变换对由麦克风接收的来自说话人的待增强的噪声音频数据中的噪声音频信号进行处理得到对应的时频谱,并基于构建的基于记忆模块的超声波语音增强网络,根据待增强的噪声音频信号对应的时频谱以及待增强的噪声音频数据所对应的说话人特征向量,获得待增强的噪声音频信号对应的增强后的语音信号。本发明通过融合说话人特征向量以及记忆模块到超声波语音增强网络中,使得可以通过仅使用噪声音频输入来生成相应的超声波特征向量,完成使用超声波语音增强的目的。相较于其他超声波语音增强的方法,增强了交互性。相较于纯音频模态语音增强的方法,提高了性能,并可以处理多说话人、低信噪比等复杂噪声环境。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23531.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表