一种基于弱监督学习的虚假语音片段检测识别方法
- 国知局
- 2024-06-21 11:47:05
本发明属于语音识别,具体是一种基于弱监督学习的虚假语音片段检测识别方法。
背景技术:
1、随着语音识别技术的不断发展以及现代通信的便捷性,以及语音合成和语音转换等语音生成技术越来越成熟,通过语音伪造技术可以精确模仿目标说话人的声音以达到欺骗人或机器听觉的目的,伪造语音的事件也逐渐增多。
2、目前,对伪造或虚假语音的识别方法常通过对声纹特诊数据的深度学习进行区分,传统的监督学习是要人先标注数据,然后利用已标注好的数据去训练神经网络。但是,这种方式人工批注代价太大,因此使用弱监督学习方式处理未标记数据,可以减少手动标记数据所需的时间。但是,在实际应用过程中,还需要对标记的数据与设定的音频特征进行对比区分,对虚假语音的识别精度差且准确率低。
技术实现思路
1、本发明的目的是提供一种基于弱监督学习的虚假语音片段检测识别方法,能根据沟通用户自身的行为特点进行识别区分,以提高虚假语音的识别精度以及准确率。
2、为了实现上述目的,本发明的技术方案如下:
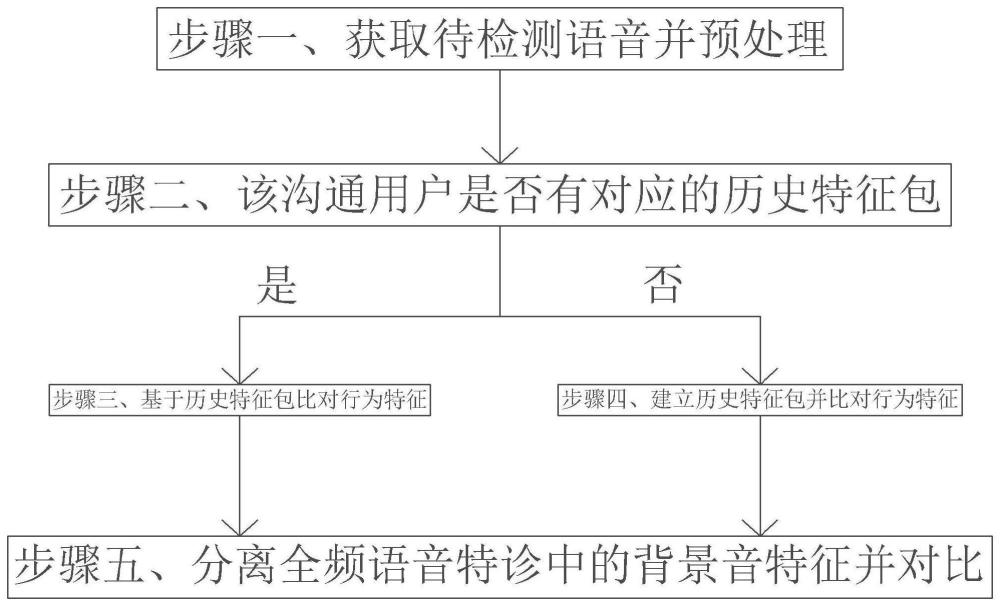
3、一种基于弱监督学习的虚假语音片段检测识别方法,包括以下步骤:步骤一、获取待检测语音,并将待检测语音输入特征向量提取模型中,得到全频声纹特征以及对应的局部声纹特征;
4、其中,局部声纹特征基于各段声纹波动的间隔将全频声纹特征分割为不同的语段,局部声纹特征包括特定语段的对应声纹特征的波峰和波谷,以及常用语段中的结尾语气词的声纹特征;
5、步骤二、基于待检测语音对应的沟通用户检索对应的历史特征包,若该沟通用户存在历史特征包,则进入步骤三;若该沟通用户不存在历史特征包,则创建该沟通用户的历史特征包,并进入步骤四;
6、步骤三、基于历史特征包得到该沟通用户对应的行为特征,并将行为特征与对应的局部声纹特征进行对比,若符合,则将该局部声纹特征的波峰与波谷进行结合,得到相似声纹特征,并将不同的相似声纹特征进行逐一对比,若不同的相似声纹特征一致,则输出虚假语音结果,若不同的相似声纹特征不一致,则进入步骤五,若不符合,则输出虚假语音结果;
7、步骤四、基于该沟通用户的全频语音特征,在特定语段或采用语段下采集待对比声纹特征,并以待对比声纹特征建立历史特诊包;
8、还将全频语音特征的波峰与波谷进行结合,得到相似声纹特征,并将不同的相似声纹特征进行逐一对比,若不同的相似声纹特征一致,则输出虚假语音结果,若不同的相似声纹特征不一致,则进入步骤五;
9、步骤五、分离全频语音特诊中的背景音特征,若存在背景音特征,则终止,若背景音特征不存在,则输出虚假语音结果。
10、采用上述方案后实现了以下有益效果:
11、根据沟通用户的历史语音得到基于行为特点的声纹特征以及语气波动情况(特定语段的对应声纹特征的波峰和波谷),从而能根据用户自身的行为特点,对真实发声与虚假语音进行第一次区分。
12、在该用户与沟通用户交互过程中,判断沟通用户用户是否存在背景音,从而判断用户的是否处于正常发声状态,从而能根据沟通用户自身的行为特点以及沟通用户与外界之间的差别识别虚假语音,以提高对虚假语音的识别精度以及准确率。
13、进一步,在步骤五中,还会计算相邻语段之间的反应时间,并将反应时间与设定的标椎时间进行对比,若反应时间小于标椎时间,则累计一次预警值,若反应时间大于或等于标椎时间,则终止;
14、在连续的语段中,并将累计的预警值与设定的比对值进行对比,若预警值大于对比值,则输出虚假语音结果,若预警值小于对比值,则终止。
15、有益效果:通过对反应时间进行判断,以判断沟通用户是否在思考回答,从而将真实发声与虚假语音进行区分。
16、进一步,在步骤五中,在连续的语段中,当预警值小于对比值时,若下一语段对应的反应时间小于标椎时间,则累计的预警值将清零。
17、有益效果:因问题的简单或困难程度,沟通用户回答问题的反应时间是不同的,可能因简单问题而累计一次预警值,通过将累计的预警值清零,以避免错误识别的发生。
18、进一步,在步骤一中,常用语句中的结尾语气词的声纹特征包括该语段的尾音拖长、结尾语气助词、结尾词对应声纹特征的波峰和波谷。
19、有益效果:将沟通用户自身的说话行为特点作为对比特征,以此实现将真实发声与虚假语音进行第一次区分,便于减少后续待检测语音的处理量。
20、进一步,在步骤五中,背景音特征包括人的呼吸声和外界声音。
21、有益效果:通过呼吸声和外界声音进行判断,以判断该沟通用户是否为真实发声,从而与虚假语音进行区分。
22、进一步,在步骤五中,还会将待检测语音转换成文本内容,并将文本内容输入敏感词提取模型中,得到对应的不同语段,获取出现相同敏感词的连续语段中的关联次数,并将关联次数与设定的敏感值进行对比,若关联次数大于敏感值,则输出虚假语音结果,若关联次数小于敏感值,则终止。
23、有益效果:在连续语段中,通过关联次数的对比,判断该沟通用户是否在引导获取个人信息,从而对用户自身个人信息进行保护。
24、进一步,敏感词包括个人信息和金钱信息。
25、有益效果:通过将个人信息和金钱信息作为敏感词,对用户自身个人信息进行保护,避免个人信息的盗取。
26、进一步,在步骤二中,历史特征包的建立,以该沟通用户之前的语音数据或通话数据作为参考。
27、有益效果:以该沟通用户之前的语音数据或通话数据作为参考,使得到的行为特征具有参考意义,以提高虚假语音的识别精度。
技术特征:1.一种基于弱监督学习的虚假语音片段检测识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于弱监督学习的虚假语音片段检测识别方法,其特征在于:在步骤五中,还会计算相邻语段之间的反应时间,并将反应时间与设定的标椎时间进行对比,若反应时间小于标椎时间,则累计一次预警值,若反应时间大于或等于标椎时间,则终止;
3.根据权利要求2所述的基于弱监督学习的虚假语音片段检测识别方法,其特征在于:在步骤五中,在连续的语段中,当预警值小于对比值时,若下一语段对应的反应时间小于标椎时间,则累计的预警值将清零。
4.根据权利要求1所述的基于弱监督学习的虚假语音片段检测识别方法,其特征在于:在步骤一中,常用语句中的结尾语气词的声纹特征包括该语段的尾音拖长、结尾语气助词、结尾词对应声纹特征的波峰和波谷。
5.根据权利要求1所述的基于弱监督学习的虚假语音片段检测识别方法,其特征在于:在步骤五中,背景音特征包括人的呼吸声和外界声音。
6.根据权利要求1所述的基于弱监督学习的虚假语音片段检测识别方法,其特征在于:在步骤五中,还会将待检测语音转换成文本内容,并将文本内容输入敏感词提取模型中,得到对应的不同语段,获取出现相同敏感词的连续语段中的关联次数,并将关联次数与设定的敏感值进行对比,若关联次数大于敏感值,则输出虚假语音结果,若关联次数小于敏感值,则终止。
7.根据权利要求6所述的基于弱监督学习的虚假语音片段检测识别方法,其特征在于:敏感词包括个人信息和金钱信息。
8.根据权利要求2所述的基于弱监督学习的虚假语音片段检测识别方法,其特征在于:在步骤二中,历史特征包的建立,以该沟通用户之前的语音数据或通话数据作为参考。
技术总结本发明公开了语音识别技术领域的一种基于弱监督学习的虚假语音片段检测识别方法,包括以下步骤:步骤一、获取待检测语音并预处理;步骤二、该沟通用户是否有对应的历史特征包;步骤三、基于历史特征包得到该沟通用户对应的行为特征,并将行为特征与对应的局部声纹特征进行一致性对比;步骤四、基于该沟通用户的全频语音特征,在特定语段或采用语段下采集待对比声纹特征,并以待对比声纹特征建立历史特诊包;还将全频语音特征的波峰与波谷进行结合,得到相似声纹特征,并将不同的相似声纹特征进行相似性对比;步骤五、分离全频语音特诊中的背景音特征并对比;从而根据沟通用户自身的行为特点进行识别区分,以提高虚假语音的识别精度以及准确率。技术研发人员:田植良,李东升,黄震,乔林波,彭丽雯,潘子怡,黄静远,何泽江受保护的技术使用者:中国人民解放军国防科技大学技术研发日:技术公布日:2024/4/29本文地址:https://www.jishuxx.com/zhuanli/20240618/23549.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表