一种基于多模态特征融合的音乐情感识别方法
- 国知局
- 2024-06-21 11:46:57
本发明涉及音乐情感识别,具体涉及一种基于多模态特征融合的音乐情感识别方法。
背景技术:
1、音乐情感识别是一个新兴的研究领域,旨在让智能系统能够识别、感受、推断和解释人类情感。音乐情感识别可被广泛应用于推荐系统、自动作曲、心理治疗、音乐可视化等领域,受到学术界和工业界的广泛关注。
2、传统的音乐情感识别方法,如高斯混合模型和贝叶斯分类等,在处理大量数据和复杂音乐样式时存在计算量大和可靠性低等问题,难以满足需求。为了改进音乐情感识别方法,一些研究学者采用机器学习技术,如支持向量机和神经网络,但仍然存在改进的空间。随着深度学习的发展,越来越多的研究学者利用深度神经网络来有效地提取情感特征从而实现音乐的情感分类。然而,音乐情感本质上是多面性和多模态的,音乐是一个非常复杂的情感载体,音乐的歌词文本信息、音频信息以及音符信息都不同程度地表达着一首音乐的内在情感,这使得深度学习方法很难从特定的音乐形式中(例如,乐谱、音符、歌词或音频)分析音乐中蕴含的情感,这样往往会带来信息丢失、识别准确度不高等问题。因此多模态音乐情感识别逐渐成为学者们的研究重点。对于大部分没有歌词的纯音乐来说,音符信息能起到表征情感的作用,音乐可以通过音符之间的规律变化来表达不同的情感内容,因此,本发明融合了分别从midi数字乐谱格式的符号音乐数据和音频数据中提取的各种具有情感意义的符号特征和声学特征,为音乐情感识别任务提供了更全面的情感特征,以便可以更准确地判断音乐的情感,更好地反映音乐中所包含的情感信息和情感倾向。
3、2d-convnet具有同时编码时域和频域信息的强大能力,因此被用于音频特征提取,引入残差连接使得网络的参数优化变得更加容易,比起普通堆叠网络而言,随着网络层数的增加,识别精度也更高,同时,为了防止特征在传播过程中发生信息丢失,采用一种多级跳跃连接的方式,将前面卷积层的输出特征通过跳跃连接的方式传递给后面的卷积层作为输入,构建resnet2d残差卷积网络提取具有情感意义的声学特征。lstm常用于处理序列数据,能够有效地学习序列信息,gru是lstm的优化版本,通过简化内部结构,在保持几乎相同效果的同时提升了训练效率。bigru通过引入反向传播,能够同时利用过去和未来的信息,进而提供更全面的上下文信息,有助于情感识别性能的提高。同时,由于数据集在大小上受到严重限制,本文选择了相对简单的bigru模型而非bilstm网络以避免过拟合,同时,引入注意力机制进一步提升分类精度。因此采用bigru网络并引入注意力机制提取midi格式音乐中具有情感意义的符号特征。进一步说明,本发明针对midi数字乐谱格式的符号音乐数据基于2d-convnet引入多级跳跃连接构建resnet 2d残差卷积网络提取音频情感特征,针对音频数据采用bigru网络并引入注意力机制提取midi格式音乐的符号情感特征,将二者进行多模态特征融合,能够更全面的提取音乐的情感特征,进一步提升分类精度。
技术实现思路
1、针对现有音乐学习单一模态识别情感提升的空间有限,不能深度挖掘音乐数据集中的特征向量,识别性能差等的问题,提出基于多模态特征融合的音乐情感识别方法。本发明基于russell情感二维v-a模型来评估分类性能,其中横轴valence反映主体的主观感受,代表效价,纵轴arousal表示了主体的情感活跃程度,表示唤醒度,音乐情绪根据v/a级别分为4类:“快乐”代表高唤醒和高价(q1),‘愤怒”代表高唤醒和低价(q2),“悲伤”代表低唤醒和低价(q3),“放松”代表低唤醒和高价(q4)。为了提升4种音乐情感状态(4q)的识别准确率,本发明分别构建声学分支与符号分支特征提取网络,通过跨模态注意机制融合了分别从midi和音频数据中提取的各种具有情感意义的符号特征和声学特征,能够更全面的提取音乐的情感特征,相比于单一模态的音乐情感特征具有更高的识别准确率,取得了良好的4q分类效果。
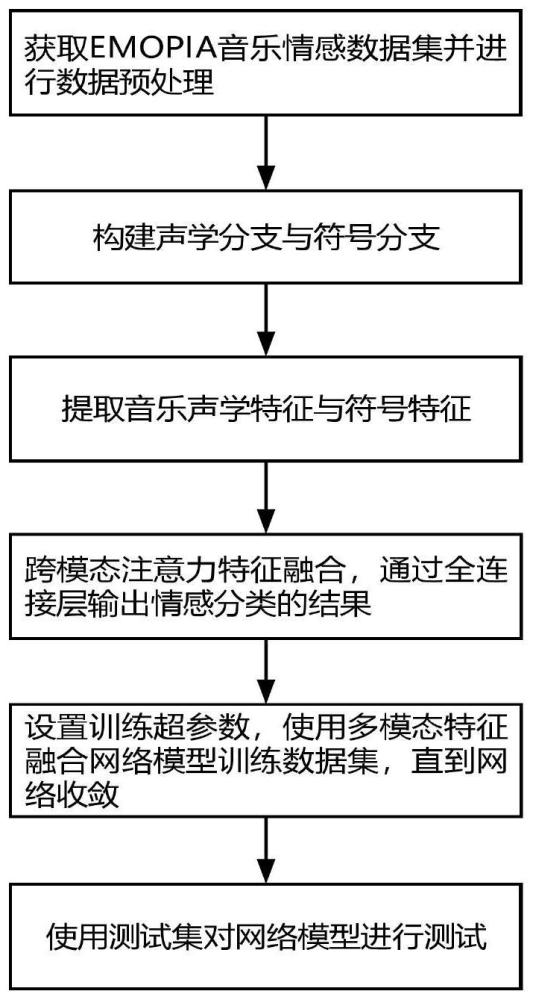
2、该方法可由以下步骤实现:
3、步骤一、下载开源emopia情感音乐数据集,将数据集按照7:2:1划分为训练集、验证集与测试集,并对所有数据集进行预处理。
4、步骤二、基于wav音频音乐与midi符号音乐构建声学模态部分与符号模态部分。
5、步骤三、声学模态部分具体为基于2d-convnet网络通过引入多级跳跃连接构建resnet 2d残差卷积网络来提取wav格式音乐的声学特征;符号模态部分具体为采用bigru网络并引入注意力机制提取midi格式音乐的符号特征。
6、步骤四、构建跨模态注意力模块将声学特征与符号特征进行跨模态特征融合,通过全连接层输出情感分类的结果,所述音乐情感类别包括快乐(q1)、愤怒(q2)、悲伤(q3)、放松(q4)4种音乐。
7、步骤五、设置训练超参数,使用多模态特征融合网络模型训练数据集,直到网络收敛,得到训练完备的音乐情感识别模型,并得到准确率(accuracy)、精准度(precision)、召回率(recall)、f1值(f1-score)。
8、步骤六、使用测试集再次对网络模型进行测试,完成音乐情感识别任务,将待测音乐输入训练得到的最佳网络模型,输出音乐情感类别(q1、q2、q3、q4)。
9、本发明的优点及有益效果如下:
10、1.本发明提供了一种新的基于多模态特征融合的音乐情感识别模型,有效提升了音乐情感识别的准确率。
11、2.本发明解决了单一模态情感信息不足的问题,将纯钢琴音乐视为声学(音频)与符号(音符)两种模态,将从midi和音频数据中提取的各种具有情感意义的符号特征和声学特征通过跨模态注意力机制进行多模态特征融合,实现两种模态的信息交互,能够更全面的提取音乐的情感特征,相比于单一模态的音乐情感特征具有更高的识别准确率。
技术特征:1.一种基于多模态特征融合的音乐情感识别方法,其特征是:该方法由以下步骤实现:
2.根据权利要求1所述的一种基于多模态特征融合的音乐情感识别方法,其特征在于:在进行训练前,还需要对音乐数据进行预处理,加载音频文件并以22050hz的采样率重新采样,加载midi符号数据用midi-like进行符号序列编码。
3.根据权利要求1所述的一种基于多模态特征融合的音乐情感识别方法,其特征在于:步骤三中将声学模态部分与符号模态部分分别构建神经网络进行特征提取。其中,声学模态部分采用mfcc和梅尔频谱图作为声学分支的输入,在原有2d-convnet的基础上引入多级跳跃连接构建resnet 2d残差卷积网络提取wav格式音乐的声学特征,能够防止特征在传播过程中发生信息丢失,以便更好地进行声学特征提取;符号模态部分构建bigru来处理符号序列数据,为了进一步提升网络性能,同时引入注意力机制,通过线性加权序列的特征表征目标位置的特征,以便更好地进行符号特征提取。
4.根据权利要求1所述的一种基于多模态特征融合的音乐情感识别方法,其特征在于:步骤四中构建跨模态注意力模块,为了减少单一模态情感信息不足的问题,本发明引入跨模态注意力机制模块进行模态交互。在步骤三中得到声学特征与符号特征,使用一个输入作为查询(q),另一个输人作为键(k)和值(v),用注意力机制来计算两个输入每个元素之间的相关性。然后,将注意力权重与值(v)相乘并求和,得到模态间的交互特征。最后,将交互特征与原始输入连接起来,形成新的融合了多模态信息的特征表示。通过这种方式,可以有效地减少单个模态在情感分析中的局限,提高模型的泛化性能和鲁棒性。
技术总结本发明属于音乐情感识别技术领域,具体为一种基于多模态特征融合的音乐情感识别方法。近年来有关音乐情感识别的研究得到了较大的进展,基于深度学习的方法被越来越多的科研人员广泛关注,但音乐作为信息的媒介,蕴含着丰富的情感信息,音乐情感本质上是多面性和多模态的,这使得深度学习方法很难从特定类型的音乐形式中分析音乐中蕴含的情感。针对在以往的音乐情感识别研究中,研究人员只关注音乐曲目的单一模态内容,分类识别精度受限等问题,本发明提出一种多模态特征融合的音乐情感识别方法,具体来说,本发明方法构建声学模态部分与符号模态部分,分别进行MIDI符号数据和WAV音频数据的特征提取,然后将从MIDI数据和WAV音频数据中提取的各种具有情感意义的符号特征和声学特征通过跨模态注意力机制进行多模态特征融合,最后将得到的融合多模态特征通过全连接层输出最终的情感分类结果。本发明能够提高音乐情感识别的精度。技术研发人员:白雪梅,赵荟圆,张晨洁,胡汉平,丁志超,周靖博,齐浩男受保护的技术使用者:长春理工大学技术研发日:技术公布日:2024/4/29本文地址:https://www.jishuxx.com/zhuanli/20240618/23537.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表