一种基于VITS神经样条流改进的音素时长预测方法
- 国知局
- 2024-06-21 11:46:55
本发明属于语音合成,具体涉及一种基于vits神经样条流改进的音素时长预测方法。
背景技术:
1、目前,基于深度学习的语音合成方法主要分为自回归方法和非自回归方法,自回归方法是语音合成领域中较早采用的生成模型之一,主要的自回归模型包括循环神经网络(rnn)和长短时记忆网络(lstm)等;非自回归方法是相对较新的研究方向,非自回归方法试图通过并行生成整个序列,而不依赖于先前生成的内容,这样的方法可以显著提高生成速度,特别适用于实时应用。然而由于非自回归方法的生成方式不依赖于先前生成的内容,而使用音素时长预测来确定最终的语音波形数据的总长度,所以可能在保持上下文一致性方面存在一些挑战,导致生成结果可能相对较差。在早期的语音合成系统中,时长信息通常是通过手动标注或基于规则的方法获得的,例如基于统计模型方法如隐马尔可夫模型和决策树等来预测音素时长,这种方法的问题在于它可能无法适应不同说话人、语境或情感的变化,因此导致语音合成的表现不够自然。最近,端到端的非自回归语音合成系统变得越来越流行,其中包括了端到端的时长预测,这意味着整个语音合成过程,从文本到语音的转换可以通过一个统一的模型进行,例如tacotron、fastspeech、vits(variational inferencewith adversarial learning for end-to-end text-to-speech)等。
2、公开号为cn102222501a的中国专利申请提出了一种语音合成时长参数的预测方法,其基于隐马尔可夫模型的语音合成中进行状态时长参数的生成,对于输入的上下文相关隐马尔可夫模型序列生成各模型的各个状态的时长,即各状态的驻留时间,在生成状态时长参数时结合了隐马尔可夫模型中的状态时长模型和时长整体方差模型;创建时长整体方差模型训练语料库,利用时长整体方差分析器从训练语料库中生成时长整体方差训练样本,利用整体方差训练样本训练时长整体方差模型。
3、公开号为cn102231276 a的中国专利申请提出了基于决策树-高斯混合模型的线性回归的音素时长预测方法,其针对上下文环境参数采用逐步线性回归的时长预测模型,对语音合成单元的时长进行初始预测,获得初始时长预测结果;采用决策树-高斯混合模型对所述初始时长预测结果进行分配,得到分配后的时长预测结果,能够提高时长预测结果的准确性,使得从语音合成系统中合成出的语音具备真实的韵律感。
4、上述两种专利技术所采用的方法需要给予大量的语音语料数据来训练才能达到较好的模型泛化能力,所需的成本较大,并且随着语料的扩充和音素序列的增长,训练和推理速度下降比较明显,不能够满足实时语音生成的需求。
技术实现思路
1、鉴于上述,本发明提供了一种基于vits神经样条流改进的音素时长预测方法,对vits所使用的随机时长预测器中的神经样条流提出改进,能够耦合变换函数的数据变换能力,从而实现音素时长预测准确性的提高。
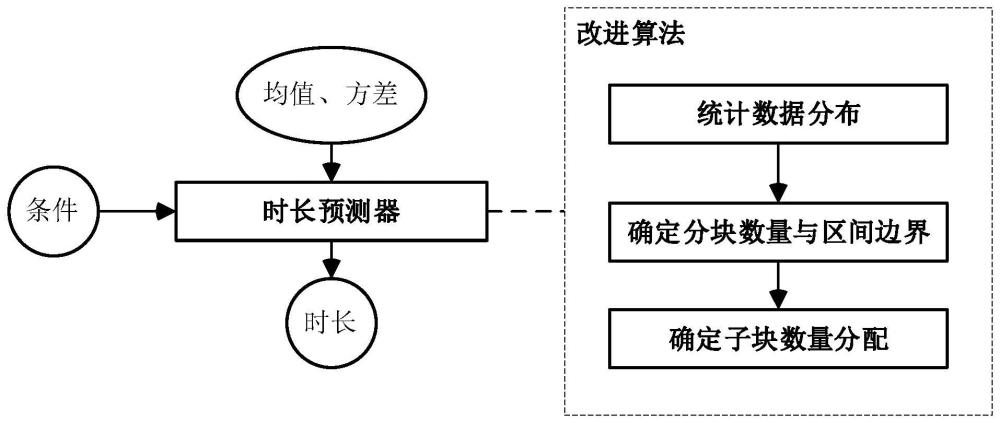
2、一种基于vits神经样条流改进的音素时长预测方法,包括如下步骤:
3、(1)统计并分析神经样条流的输入数据分布;
4、(2)将输入数据的变换区间划分为多个块区间,确定每个块区间的边界,为每个块区间分配子块数量;
5、(3)通过对vits模型冻结训练的方式,加速神经样条流的训练过程,从而利用神经样条流来预测音素时长,并由模型生成音频;
6、(4)通过时长预测误差分析来评估神经样条流的预测性能;
7、(5)综合评测模型生成音频的质量以及模型算法的时间复杂度和空间复杂度。
8、进一步地,所述步骤(1)中在对vits模型的训练和推理阶段统计神经样条流输入数据中的非线性变换部分在变换区间中的数据出现频率,具体地则将变换区间均匀划分为100个子区间,进而统计出现在各子区间内的数据频率。
9、进一步地,所述vits模型中的时长预测模块是基于神经样条流实现的,所述神经样条流是一种归一化流生成模型,其采用样条插值使单调有理二次函数替换仿射变换函数来实现更复杂的数据变换,从而增强其耦合变换函数的灵活性来提高模型生成能力,由此将vits模型应用于语音合成中的时长预测模块,以实现高精确的音素时长预测。
10、进一步地,所述步骤(2)中首先根据输入数据的分布,确定vits模型中的超参数b以及变换区间的分块数量,所述超参数b用于确定输入数据的变换区间即区间边界值;然后将整个变换区间划分为多个块区间,进而通过数据分析确定每个块区间的边界,使得在每个块区间内的耦合变换更加有效。
11、进一步地,神经样条流输入数据的整个变换区间分为n个子块,共n+1个节点,根据这些节点进行插值,边缘两端节点固定,由模型预测每个子块的宽度、高度以及中间n-1个节点的一阶导数值;由此所述步骤(2)在每个块区间内根据实际数据需求分配相应的子块数量,以满足非线性变换的要求。
12、进一步地,所述步骤(3)中首先加载vits的预训练模型,由于时长预测模块中的神经样条流发生了改变,故不加载时长预测模块的参数,在加载完其他模块的参数后,将这些参数冻结不参与优化;然后利用ljspeech数据集对模型进行训练,只优化时长预测模块的参数,从而提高模型的训练效率。
13、进一步地,所述步骤(4)的具体实现方式为:在模型训练完成后,首先通过计算时长预测值与真实值之间的误差均值和方差,验证模型的时长预测准确性,其中时长真实值来自于模型训练过程的单调对齐搜索计算的值;然后通过对比不同超参数b下的时长预测误差,确定能够达到最佳性能的变换区间边界值。
14、进一步地,所述步骤(5)中采用主观意见分数作为验证指标用以评测模型生成音频的质量,所述主观意见分数使用深度学习模型nisqa计算获得;此外,通过实时因子和参数量的计算,综合评估整个模型算法的时间复杂度和空间复杂度。
15、本发明通过改进vits模型中的随机时长预测器,引入基于神经样条流的方法,有效提升了音素时长预测的准确性,通过对输入数据分布的细致分析和块区间的划分,模型能够在各个块区间内进行更有效的耦合变换,这使得模型在实际语音合成应用中能够以更高的精确度预测音素的时长。此外,本发明通过对模型进行冻结训练,即在训练过程中冻结除时长预测模块外的其他参数,可以加速训练过程并专注于优化时长预测模块的性能,这种方法不仅提高了训练效率,还确保了模型在预测音素时长时的准确性,采用误差均值和方差作为评估指标进一步验证了模型的预测准确性,并通过调整超参数b优化了变换区间边界值,实现了模型性能的最优化。最终,通过综合评估模型生成音频的质量、时间复杂度和空间复杂度,确保了本发明在准确性上有所提高,并且在效率和资源消耗方面没有较大变化,这种综合评估包括使用主观意见分数和深度学习模型nisqa来评测音频质量,以及计算实时因子和参数量来评估模型算法的复杂度,实验结果表明本发明能够提升所合成的音频质量。
技术特征:1.一种基于vits神经样条流改进的音素时长预测方法,包括如下步骤:
2.根据权利要求1所述的音素时长预测方法,其特征在于:所述步骤(1)中在对vits模型的训练和推理阶段统计神经样条流输入数据中的非线性变换部分在变换区间中的数据出现频率,具体地则将变换区间均匀划分为100个子区间,进而统计出现在各子区间内的数据频率。
3.根据权利要求1所述的音素时长预测方法,其特征在于:所述vits模型中的时长预测模块是基于神经样条流实现的,所述神经样条流是一种归一化流生成模型,其采用样条插值使单调有理二次函数替换仿射变换函数来实现更复杂的数据变换,从而增强其耦合变换函数的灵活性来提高模型生成能力,由此将vits模型应用于语音合成中的时长预测模块,以实现高精确的音素时长预测。
4.根据权利要求1所述的音素时长预测方法,其特征在于:所述步骤(2)中首先根据输入数据的分布,确定vits模型中的超参数b以及变换区间的分块数量,所述超参数b用于确定输入数据的变换区间即区间边界值;然后将整个变换区间划分为多个块区间,进而通过数据分析确定每个块区间的边界,使得在每个块区间内的耦合变换更加有效。
5.根据权利要求4所述的音素时长预测方法,其特征在于:神经样条流输入数据的整个变换区间分为n个子块,共n+1个节点,根据这些节点进行插值,边缘两端节点固定,由模型预测每个子块的宽度、高度以及中间n-1个节点的一阶导数值;由此所述步骤(2)在每个块区间内根据实际数据需求分配相应的子块数量,以满足非线性变换的要求。
6.根据权利要求1所述的音素时长预测方法,其特征在于:所述步骤(3)中首先加载vits的预训练模型,由于时长预测模块中的神经样条流发生了改变,故不加载时长预测模块的参数,在加载完其他模块的参数后,将这些参数冻结不参与优化;然后利用ljspeech数据集对模型进行训练,只优化时长预测模块的参数,从而提高模型的训练效率。
7.根据权利要求1所述的音素时长预测方法,其特征在于:所述步骤(4)的具体实现方式为:在模型训练完成后,首先通过计算时长预测值与真实值之间的误差均值和方差,验证模型的时长预测准确性,其中时长真实值来自于模型训练过程的单调对齐搜索计算的值;然后通过对比不同超参数b下的时长预测误差,确定能够达到最佳性能的变换区间边界值。
8.根据权利要求1所述的音素时长预测方法,其特征在于:所述步骤(5)中采用主观意见分数作为验证指标用以评测模型生成音频的质量,所述主观意见分数使用深度学习模型nisqa计算获得;此外,通过实时因子和参数量的计算,综合评估整个模型算法的时间复杂度和空间复杂度。
技术总结本发明公开了一种基于VITS神经样条流改进的音素时长预测方法,通过改进VITS模型中的随机时长预测器,引入基于神经样条流的方法,有效提升了音素时长预测的准确性,通过对输入数据分布的细致分析和块区间的划分,模型能够在各个块区间内进行更有效的耦合变换,这使得模型在实际语音合成应用中能够以更高的精确度预测音素的时长。此外,本发明通过对模型进行冻结训练,可以加速训练过程并专注于优化时长预测模块的性能,这种方法不仅提高了训练效率,还确保了模型在预测音素时长时的准确性,采用误差均值和方差作为评估指标进一步验证了模型的预测准确性,并通过调整超参数B优化了变换区间边界值,实现了模型性能的最优化。技术研发人员:冯杰,朱明航,张海翔,马汉杰受保护的技术使用者:浙江理工大学技术研发日:技术公布日:2024/4/29本文地址:https://www.jishuxx.com/zhuanli/20240618/23534.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表