-
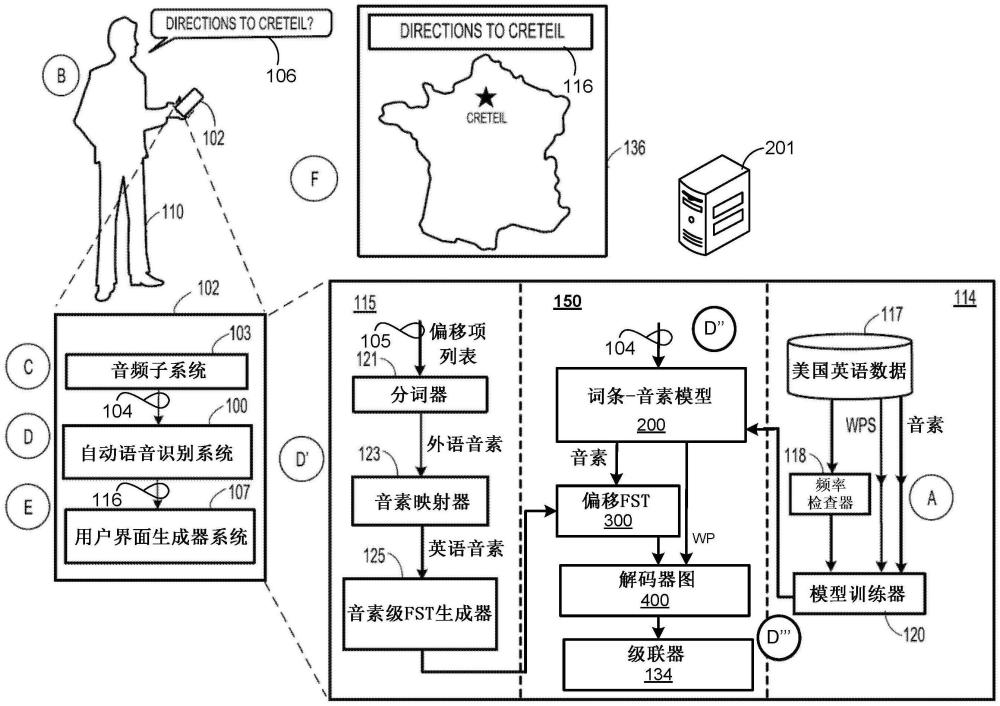
用于在端到端模型中跨语言语音识别的基于音素的场境化的制作方法
本公开涉及用于在端到端模型中的跨语言语音识别的基于音素的场境化(contextualization)。背景技术:1、识别语音的场境(context)是自动语音识别(asr)系统的目标。然而,鉴于人们可......
-
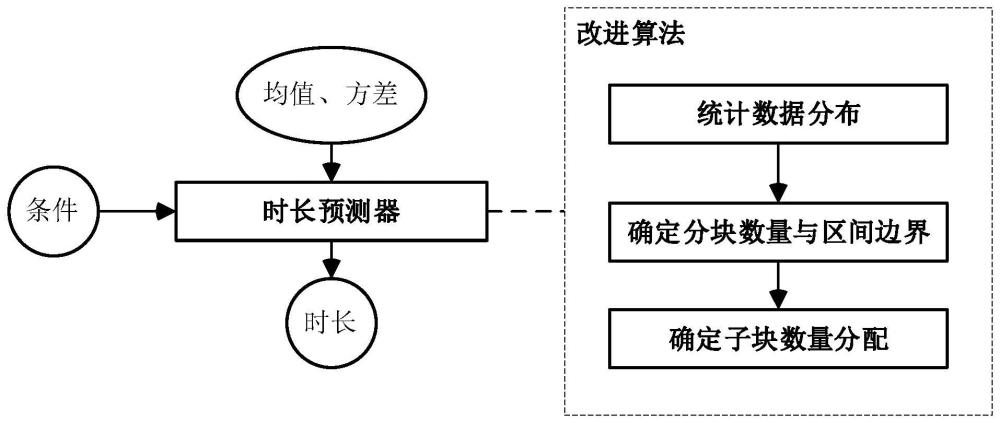
一种基于VITS神经样条流改进的音素时长预测方法
本发明属于语音合成,具体涉及一种基于vits神经样条流改进的音素时长预测方法。背景技术:1、目前,基于深度学习的语音合成方法主要分为自回归方法和非自回归方法,自回归方法是语音合成领域中较早采用的生成模......
-
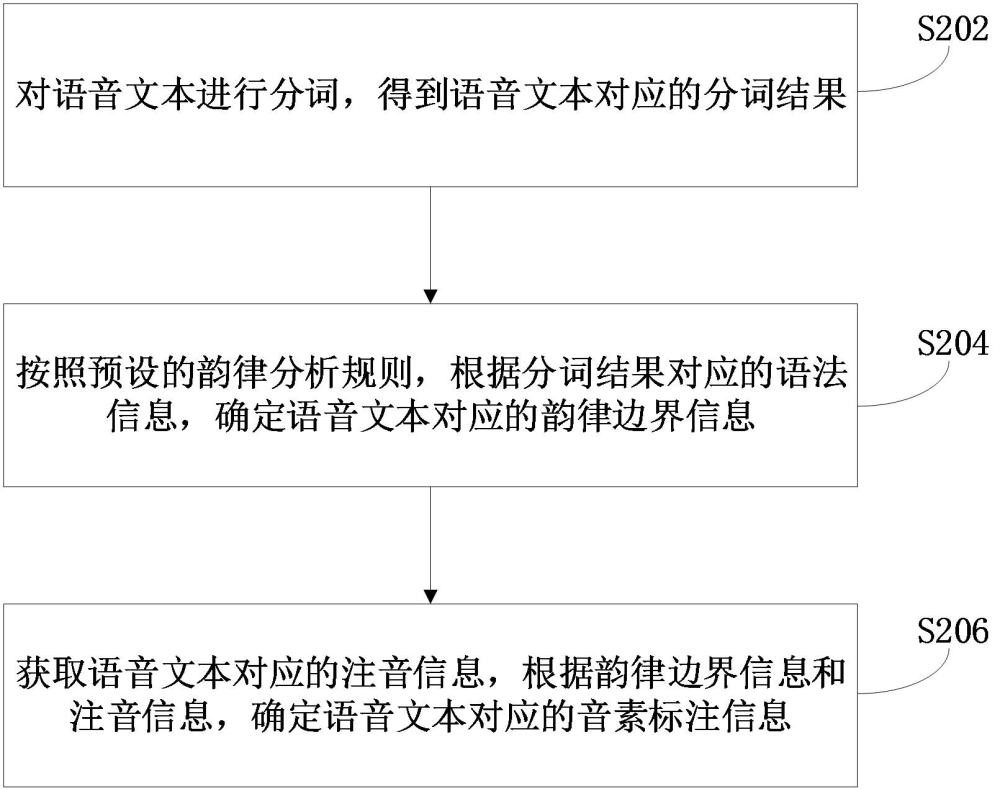
文本音素标注信息生成方法、装置和计算机设备与流程
本技术涉及计算机,特别是涉及一种文本音素标注信息生成方法、装置、计算机设备、存储介质和计算机程序产品。背景技术:1、语音合成可以将文字信息转化为语音,语音合成技术可以广泛应用于各个领域,例如:在金融领......
-
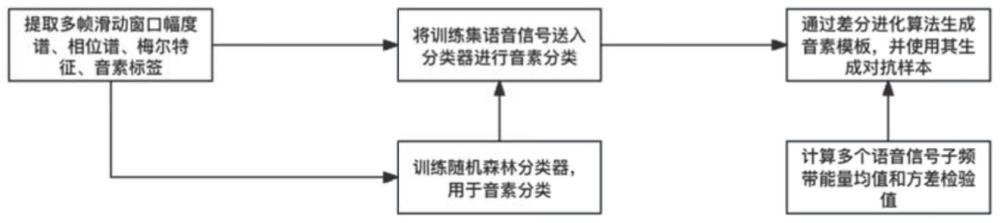
一种音素模板的实时对抗样本生成方法及计算机可读介质
本发明涉及数字媒体处理,尤其涉及一种音素模板的实时对抗样本生成方法及计算机可读介质。背景技术:1、互联网语音通话已经成为一种重要的社交通讯手段。然而,在现有互联网通讯被全面监听的情况下,任何语音通话都......
技术新讯 > 音素 > 列表
 2024-06-21
2024-06-21精选技术
-
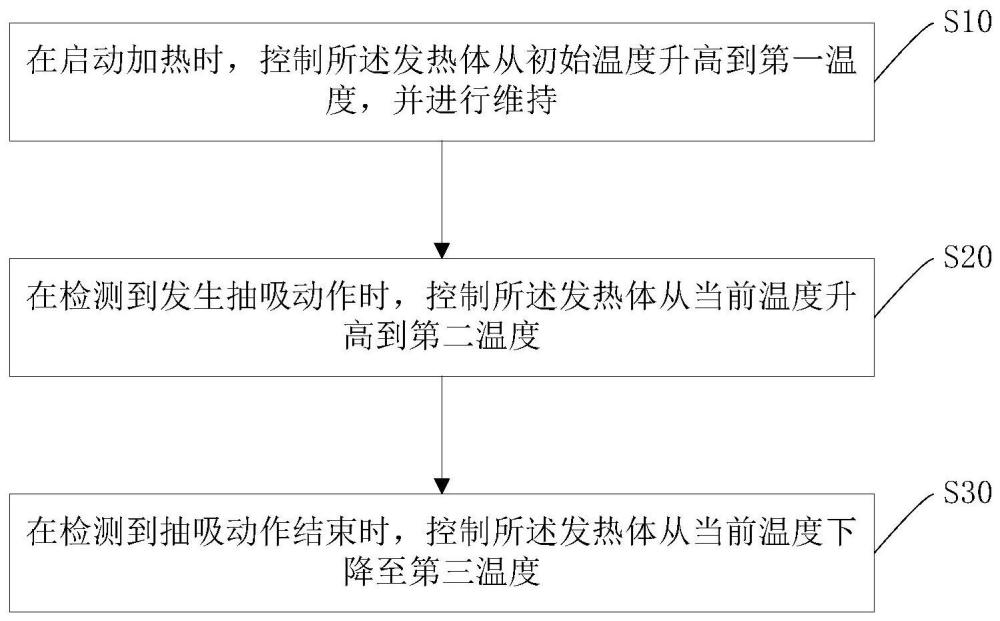
发热体、加热不燃烧装置及其加热控制方法与流程
2024-11-19 -
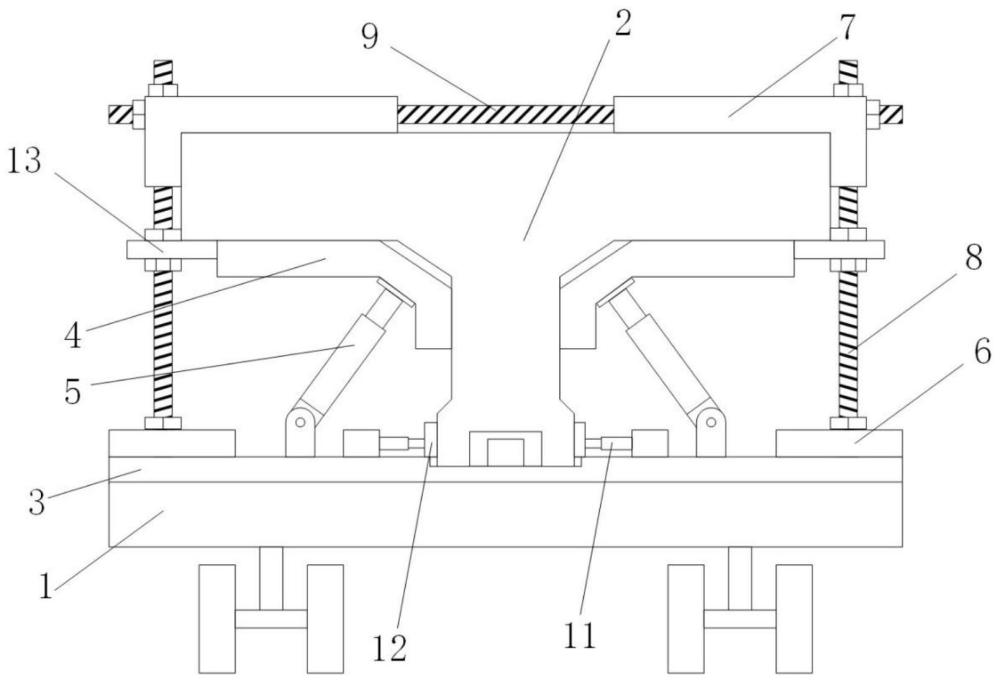
用于T梁转运的装置及方法与流程
2024-08-02 -
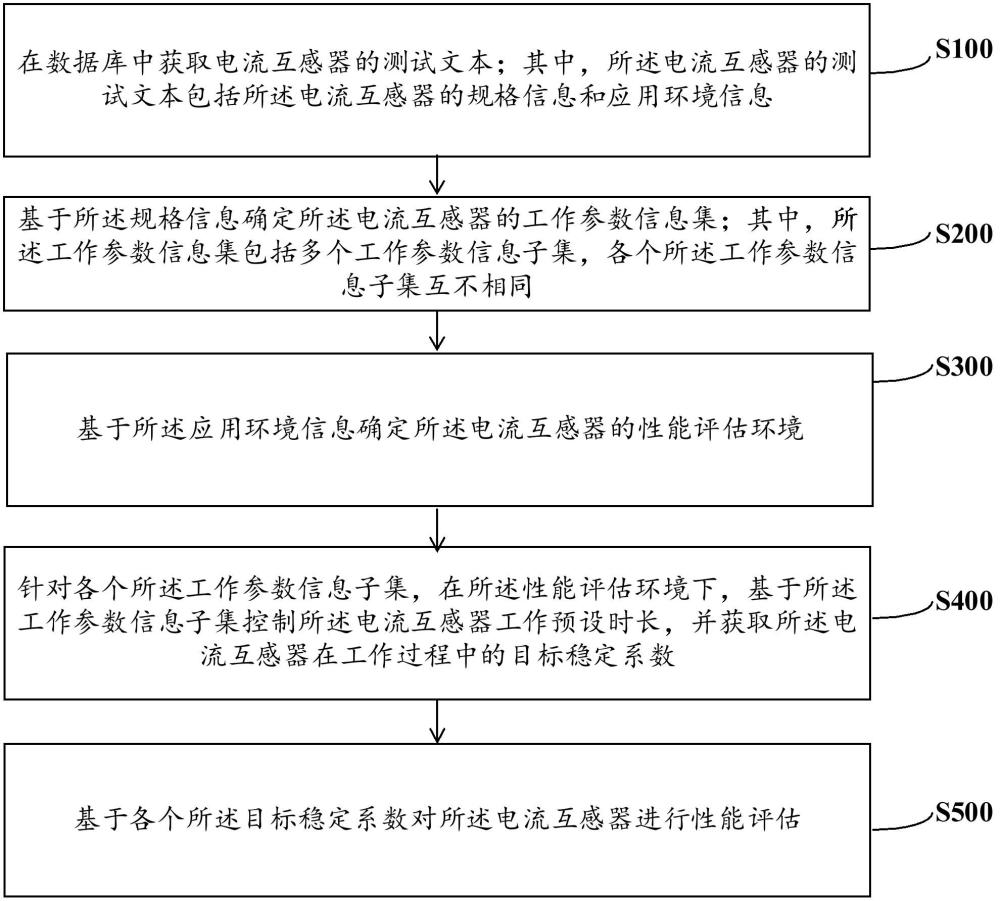
电流互感器的性能评估方法及系统与流程
2024-09-14 -

小数据传输失败报告的制作方法
2024-10-15 -
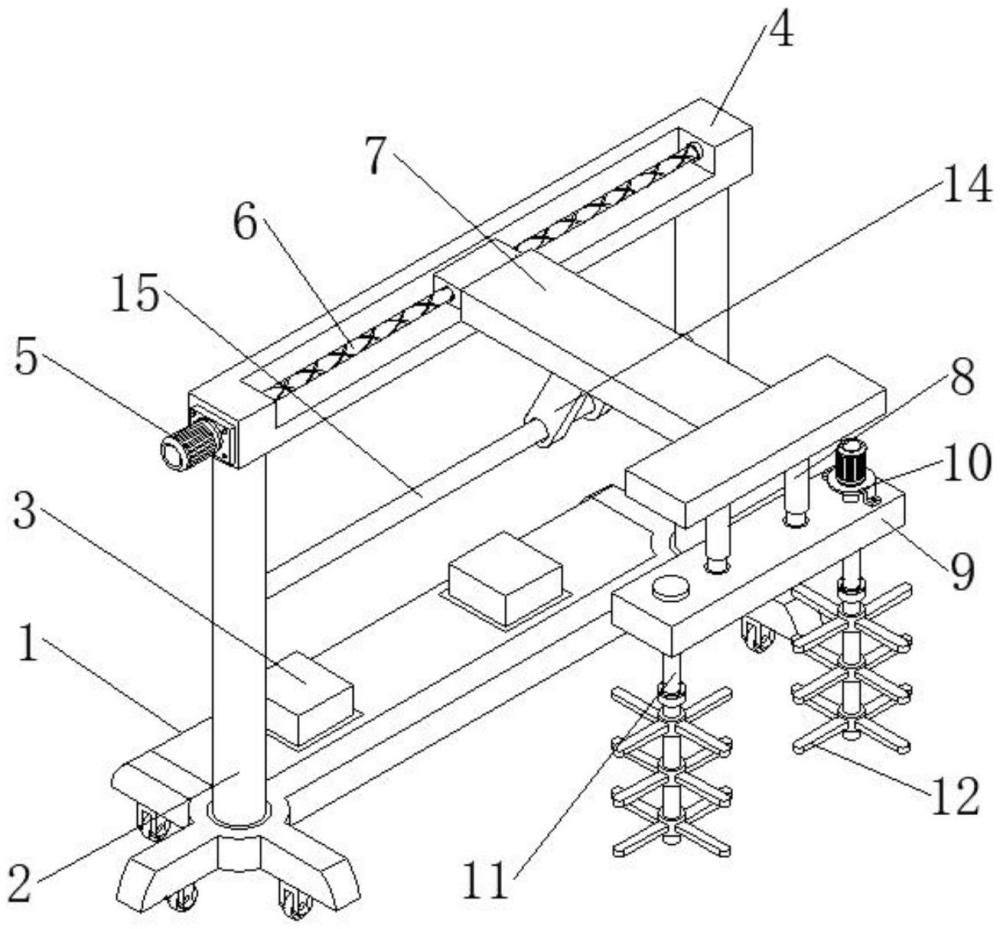
一种河道工程用河道清淤搅动装置的制作方法
2024-07-09 -
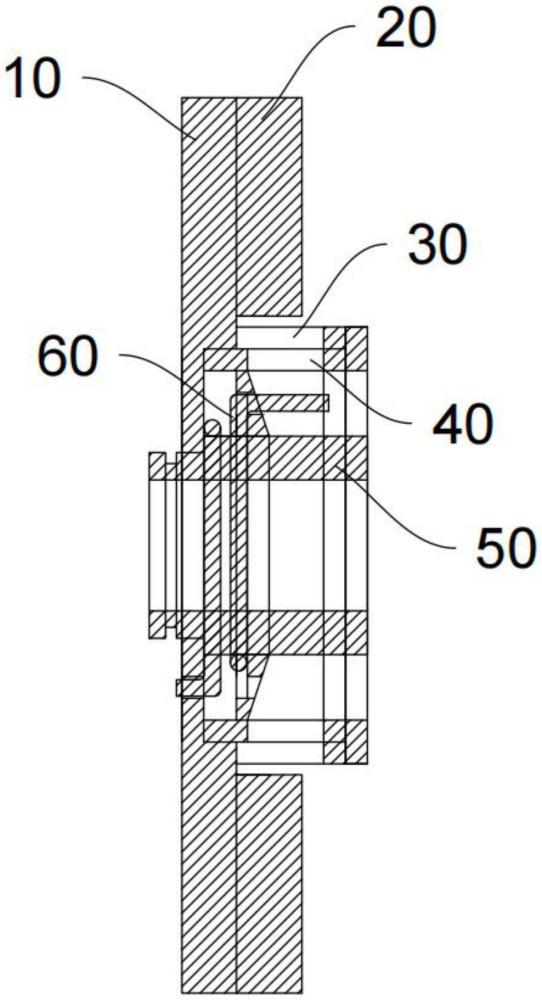
调控叶轮组的制作方法
2024-07-30 -
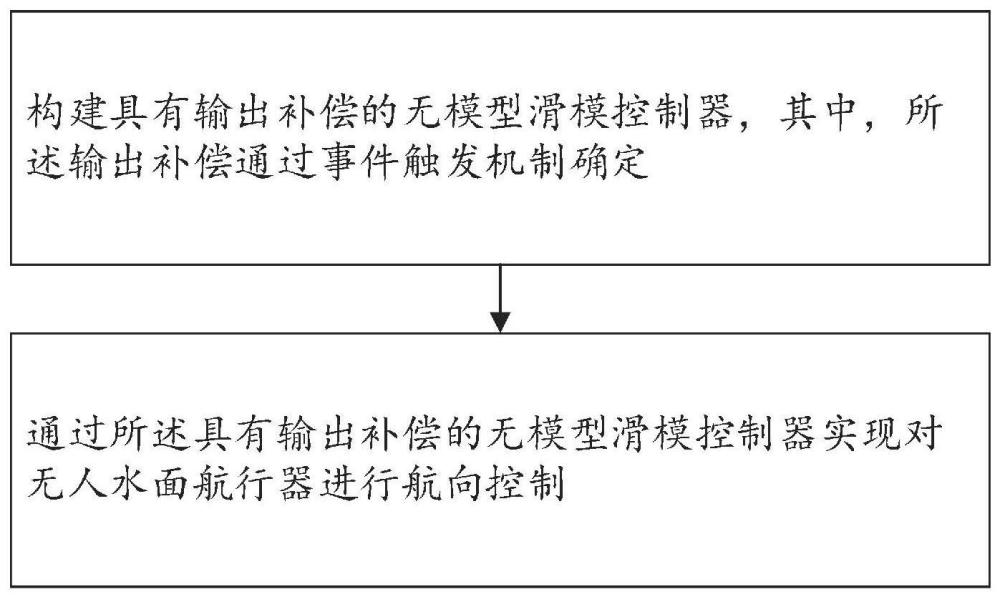
一种数据丢失情况下无人水面航行器的航向控制方法
2024-08-01 -
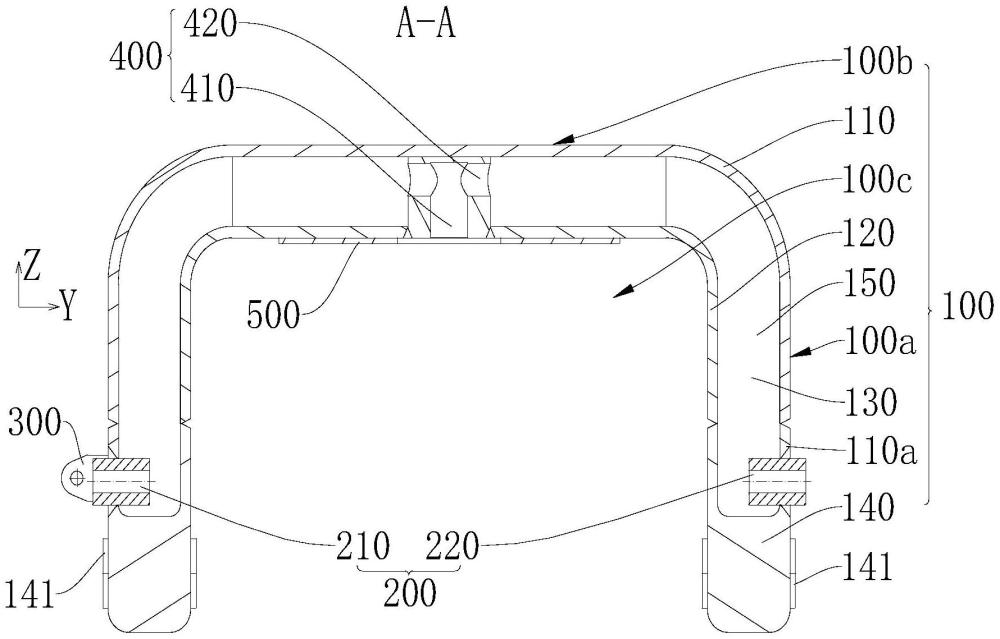
吊架及空铁交通系统的制作方法
2024-08-01 -
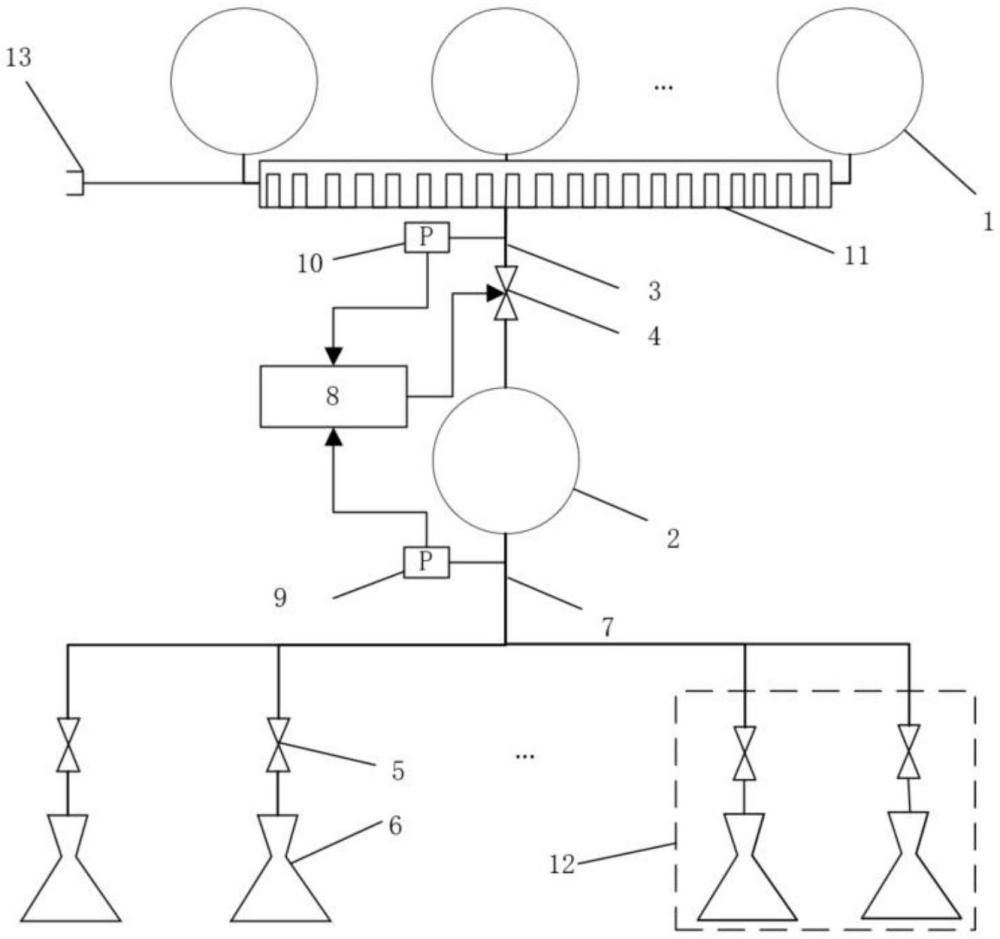
一种高低压气瓶组合的氮气推进系统的制作方法
2024-08-01 -
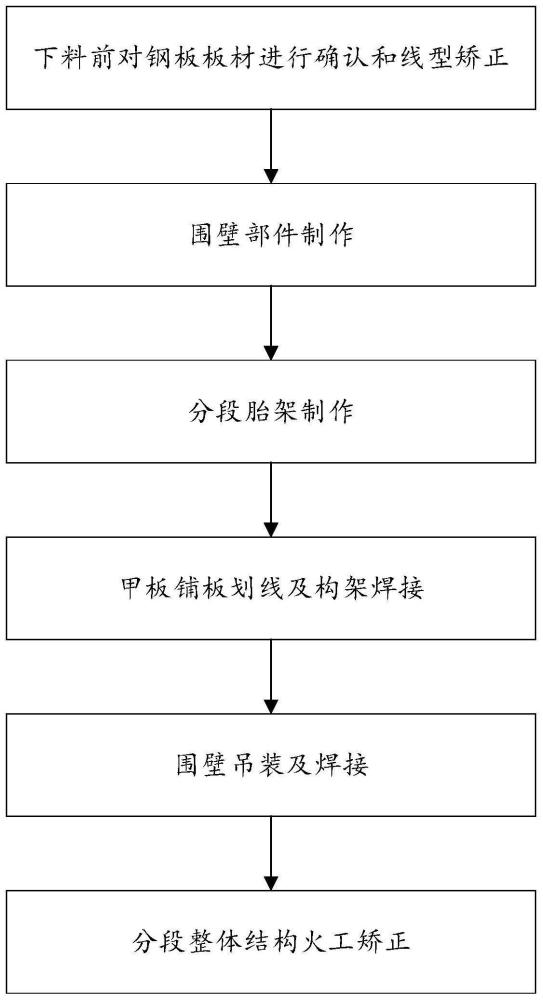
一种船体上层建筑分段建造工艺的制作方法
2024-08-01