一种判断关系亲近程度的方法、系统、设备及介质
- 国知局
- 2024-06-21 11:47:37
本发明属于信息,尤其涉及一种判断关系亲近程度的方法、系统、设备及介质。
背景技术:
1、人际关系中的对亲近程度的感知和判断对于社交过程的顺序进行至关重要。然而,由于交流双方对于关系亲近程度的感知和判断存在偏差,可能会导致不利的影响。目前,人们在判断关系亲近程度时主要依赖主观习惯感知,这种依赖性习惯容易受到个体表达能力较弱或者具有特殊口癖表达习惯的人的影响,从而增加了误解的可能性。目前尚没有一种可靠的技术方法来辅助人们判断关系亲近的程度。这样辅助方法的缺失使得人们在社交互动中更加依赖直觉和经验,而这种主观性判断可能会导致误判或产生不必要的矛盾纠纷。
技术实现思路
1、本发明的目的在于提供一种判断关系亲近程度的方法、系统、设备及介质,通过声音信息帮助人们理解和判断关系的亲疏程度,辅助人们在社交过程中更准确地理解和判断关系的亲疏程度,使得人们作出更恰当的交流反应。
2、本发明是通过以下技术方案实现的:
3、一种判断关系亲近程度的方法,包括以下步骤:
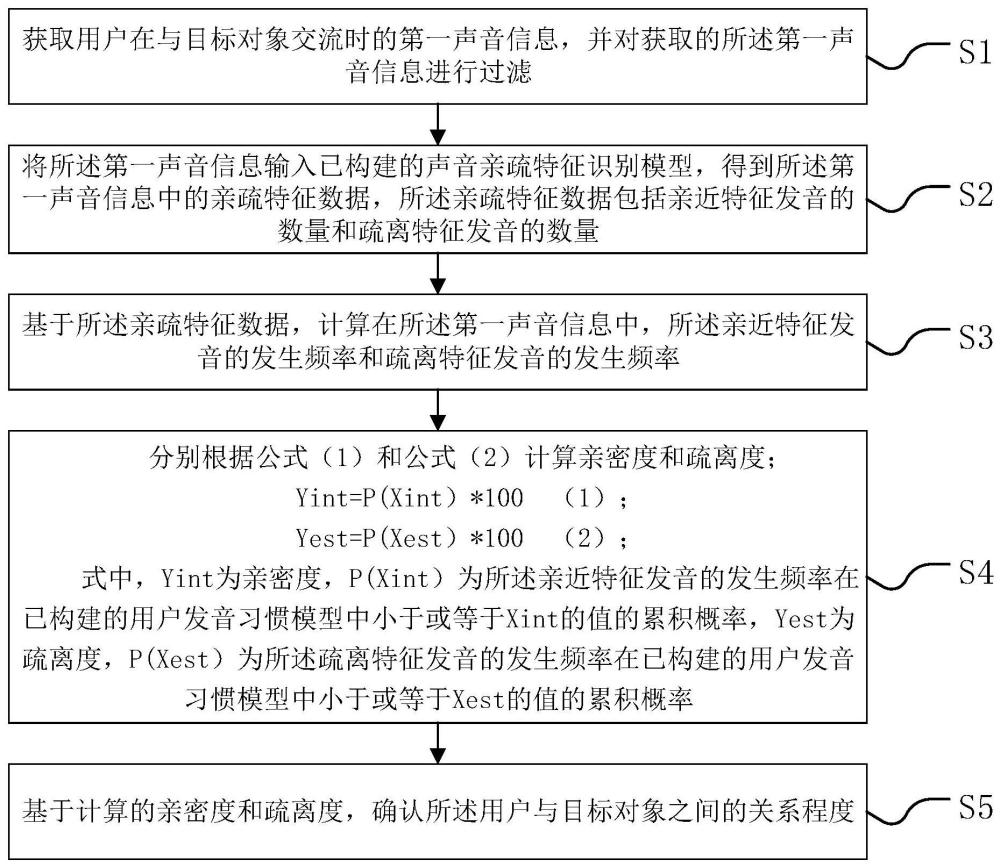
4、获取用户在与目标对象交流时的第一声音信息,并对获取的第一声音信息进行过滤;
5、将第一声音信息输入已构建的声音亲疏特征识别模型,得到第一声音信息中的亲疏特征数据,亲疏特征数据包括亲近特征发音的数量和疏离特征发音的数量;
6、基于亲疏特征数据,计算在第一声音信息中,亲近特征发音的发生频率和疏离特征发音的发生频率;
7、分别根据公式(1)和公式(2)计算亲密度和疏离度;
8、yint=p(xint)*100 (1);
9、yest=p(xest)*100 (2);
10、式中,yint为亲密度,p(xint)为亲近特征发音的发生频率在已构建的用户发音习惯模型中小于或等于xint的值的累积概率,yest为疏离度,p(xest)为疏离特征发音的发生频率在已构建的用户发音习惯模型中小于或等于xest的值的累积概率;
11、基于计算的亲密度和疏离度,确认用户与目标对象之间的关系程度。
12、进一步地,对获取的第一声音信息进行过滤的步骤包括:
13、对第一声音信息进行降噪处理,以去除周围噪声的干扰;
14、将第一声音信息转为文字信息和文字信息的时间戳;
15、根据预先设定的过滤词表,对文字信息进行过滤,并记录文字信息中过滤文字对应的时间戳,得到目标时间戳;
16、截掉第一声音信息中与目标时间戳对应的时间段,得到新的第一声音信息。
17、进一步地,获取用户在与目标对象交流时的第一声音信息的步骤包括:
18、收集用户与目标对象在自然对话中的多个第二声音信息;
19、将多个第二声音信息按照收集时间顺序进行拼接整合,得到第一声音信息,并使得第一声音信息的时间长度到设定时间长度。
20、进一步地,声音亲疏特征识别模型的构建过程如下:
21、收集多个不同对象在自然对话中的第三声音信息,得到多个第三声音信息;
22、对于每个第三声音信息,对第三声音信息进行降噪及拆分处理,得到若干声音信息段;
23、获取每段声音信息段中每个文字的声音对应的特征发音,特征发音包括亲近特征发音、疏离特征发音或无特征发音,其中,亲近特征发音为鼻音、入声、闭口音、唇齿音或模糊音,疏离特征发音为开口音、喉音或儿化音;
24、将多段声音信息段分为训练组和验证组;
25、利用训练组对预训练完成的声音亲疏特征识别模型进行微调训练,利用验证组验证预训练完成的声音亲疏特征识别模型的准确性及鲁棒性。
26、进一步地,获取每段声音信息段中每个文字的声音对应的特征发音的步骤包括:
27、获取多个评估员分别对每段声音信息段中每个文字的声音进行标注的若干特征发音;
28、对于每段声音信息段,计算声音信息段的特征标注一致性系数,并将特征标注一致性系数高于第一预设阈值的声音信息段标记为待评估的声音信息段,得到多个待评估的目标声音信息段;
29、将多个待评估的目标声音信息段划分为多组声音信息组;
30、对于每组声音信息组,获取专家对声音信息组的特征发音标注的抽样正确率,并将抽样正确率大于第二预设阈值的声音信息组标记为有效标注;
31、在多组声音信息组中,将有效标注的声音信息组保留,其余声音信息组删除,得到每段声音信息段中每个文字的声音对应的特征发音。
32、进一步地,用户发音习惯模型的构建过程如下:
33、根据每段声音信息段中每个文字的声音的特征发音,建立声音亲疏特征常模;
34、在得到第一声音信息中的亲疏特征数据的步骤之后,将亲疏特征数据进行存储;
35、判断存储的亲疏特征数据的数量是否达到预设数量,若则,根据存储的亲疏特征数据和声音亲疏特征常模,生成用户发音习惯模型。
36、进一步地,分别根据公式(1)和公式(2)计算亲密度和疏离度的步骤之前,方法还包括:
37、判断是否已构建用户发音习惯模型;
38、若是,则利用亲疏特征数据对用户发音习惯模型进行校准,更新用户发音习惯模型;
39、若否,则执行用户发音习惯模型的构建过程。
40、本发明还提供了一种判断关系亲近程度的系统,包括:
41、获取模块,用于获取用户在与目标对象交流时的第一声音信息,并对获取的第一声音信息进行过滤;
42、输入模块,用于将第一声音信息输入已构建的声音亲疏特征识别模型,得到亲近特征发音和疏离特征发音的数量;
43、第一计算模块,用于计算在第一声音信息中,亲近特征发音的发生频率和疏离特征发音的发生频率;
44、第二计算模块,用于分别根据公式(1)和公式(2)计算亲密度和疏离度;
45、yint=p(xint)*100 (1);
46、yest=p(xest)*100 (2);
47、式中,yint为亲密度,p(xint)为亲近特征发音的发生频率在已构建的用户发音习惯模型中小于或等于xint的值的累积概率,yest为疏离度,p(xest)为疏离特征发音的发生频率在已构建的用户发音习惯模型中小于或等于xest的值的累积概率;
48、确认模块,用于基于计算的亲密度和疏离度,确认用户与目标对象之间的关系程度。
49、本发明还提供了一种电子设备,包括:
50、处理器;
51、存储器,用于存储可执行的计算机程序;
52、其中,所述处理器执行所述计算机程序时实现所述判断关系亲近程度的方法的步骤。
53、本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述判断关系亲近程度的方法的步骤。
54、相比于现有技术,本发明的有益效果为:通过对用户的声音信息进行初始化评估和校准,能够个性化地适应用户的语音特征习惯,帮助人们识别和分析声音信息中的亲疏特征,并根据亲疏特征发生频率与用户发音习惯模型的对比,计算出用户与目标对象之间的关系的亲近程度和疏离程度,从而通过声音信息帮助人们理解和判断关系的亲疏程度,辅助人们在社交过程中更准确地理解和判断关系的亲疏程度,使得人们作出更恰当的交流反应。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23595.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表